From Language Models to Language Agents
https://www.bilibili.com/video/BV1ju4y1e7Em/?vd_source=ae5444af4da3a86008dab51f4f1a3a37
https://ysymyth.github.io/papers/from_language_models_to_language_agents.pdf
Language Model
Great, but several disadvantages
● Stateless
● Ungrounded 没有与世界交互
● Limited Knowledge 知识是有限的因为unground的原因
Language Agent
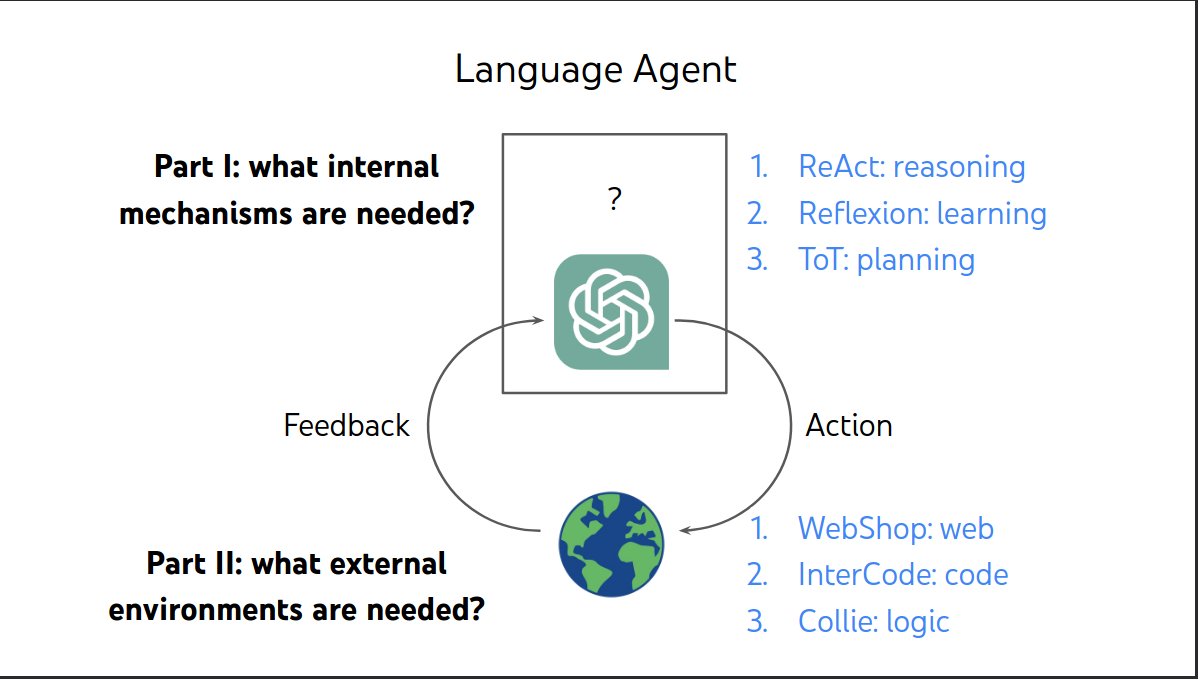
Prat I:what internal mechanisms are needed?
Mechanism 1: Reasoning-ReAct
thought:both reasioning and acting. Similar to human behavior
RL的效果很差,因为不知道为什么有这个行为(lack of reasoning)
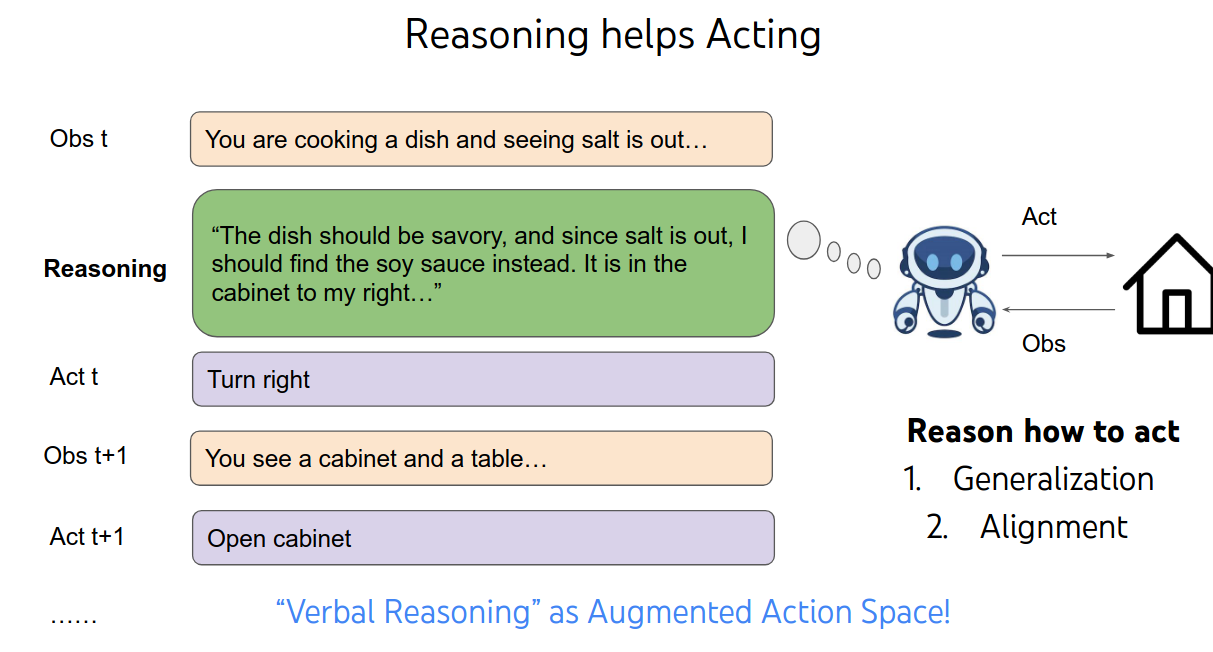
Gerneralization UP
Alignment UP
因为学习到了思维,学到了根本。
必须会Acting其实就是用工具,人也是这样的。
ReAct的思想就是既然Acting and Reasoning相辅相成,那就一起利用他们。
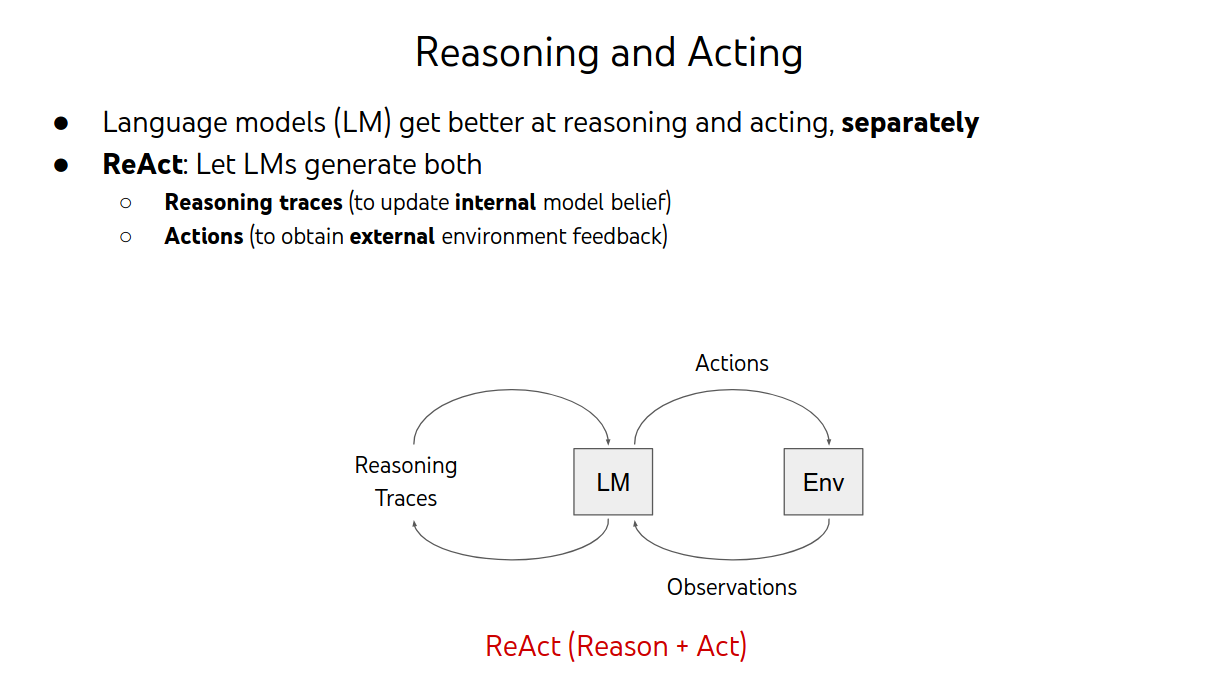
ReAct: Overview
Tasks: Question answering, Fact verification, Text game, Web Interaction task效果非常好
Learning: prompting / finetuning
Model: PaLM-540B / GPT-3
Synergy: Reasoning guides acting, acting supports reasoning
Benefits of ReAct:
○ Flexibility: diverse reasoning / interactive tasks
○ Generalization: strong few-shot / fine-tuning performances
○ Alignment: the human way of problem solving!
就像人类解决问题的方式一样!
How to realize ReAct?

reasoning->acting->reasoning->acting->.............就像人一样提prompt.
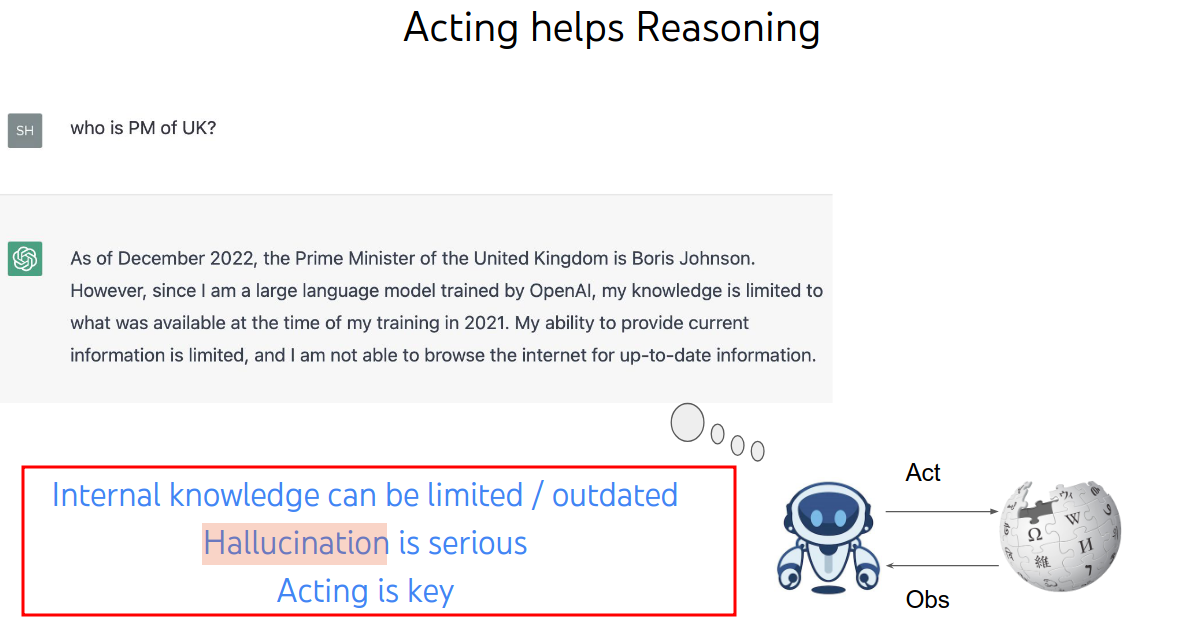
Without Act: Misinformation

出现幻觉,模型开始瞎编。
ReAct: Interpretable, Factual
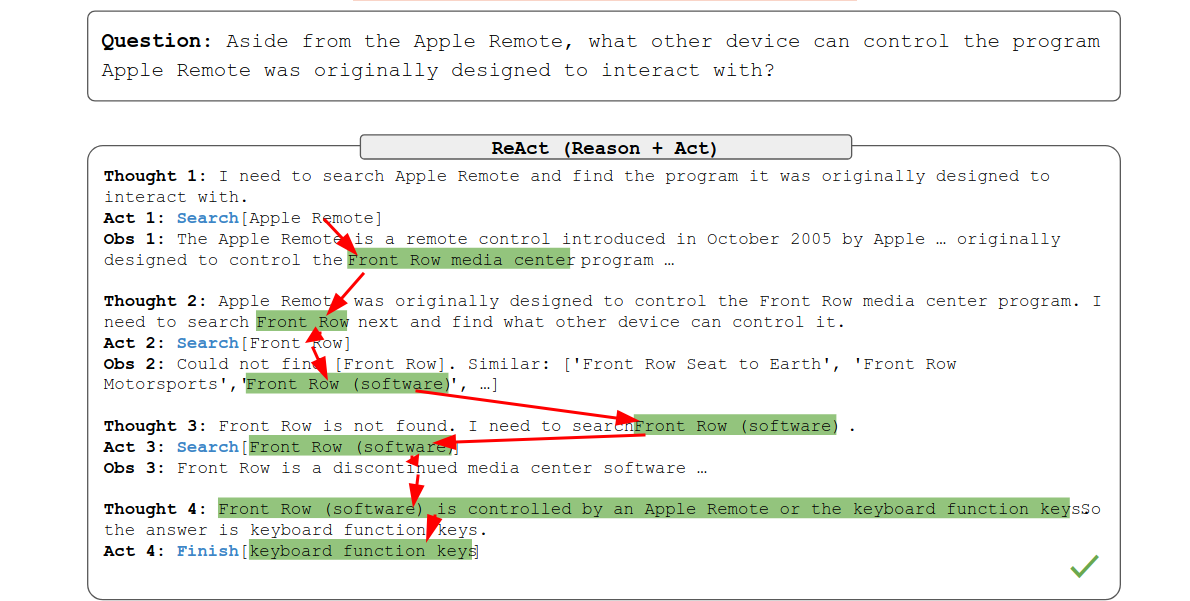
再次强调仿生,仿人。
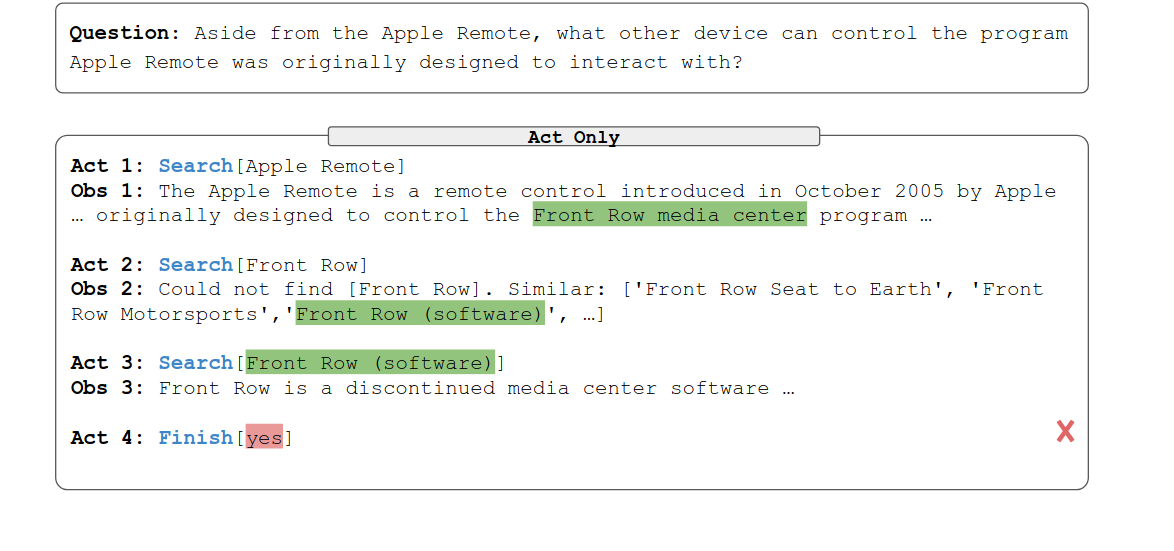
Act Only: Unable to Synthesize Final Answer
ALFWorld Example

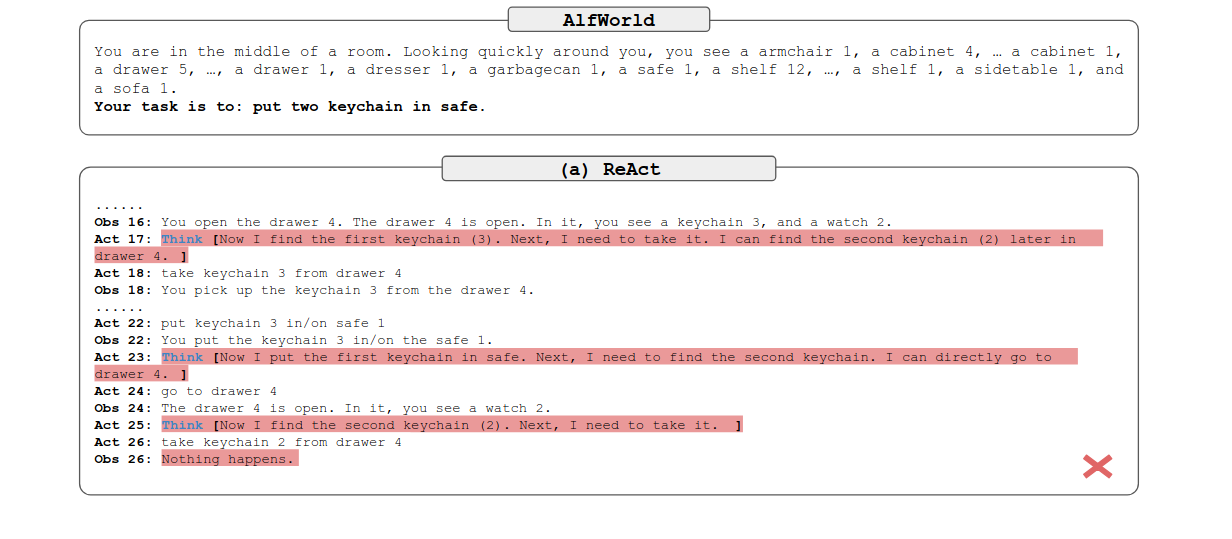
ALFWorld Example: Reasoning is Key to Long-horizon Acting
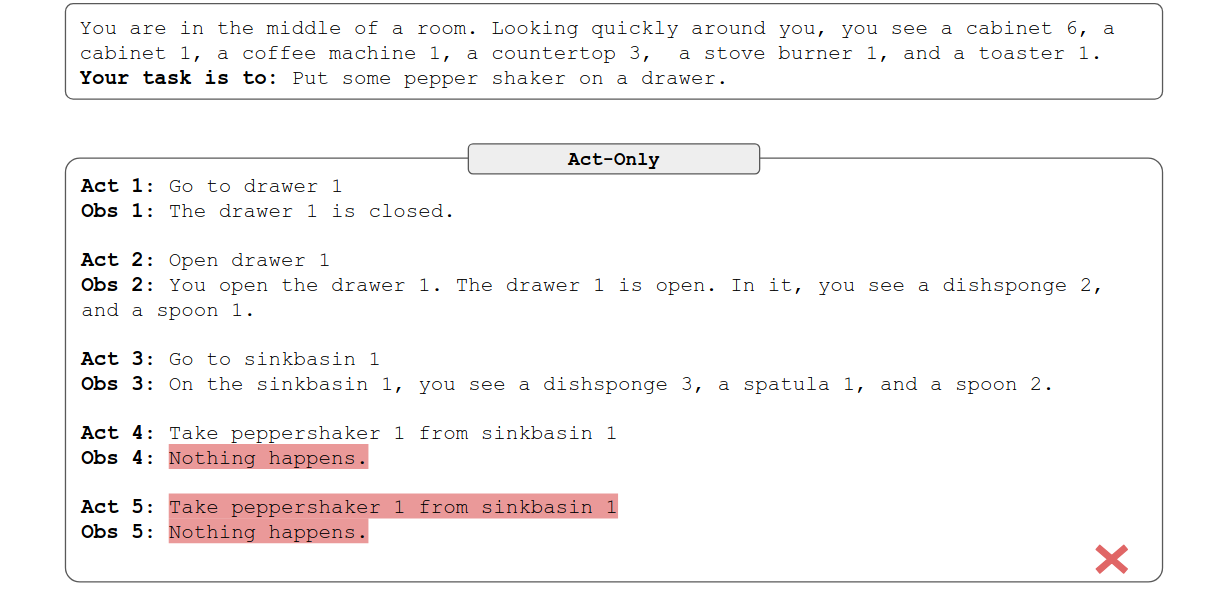
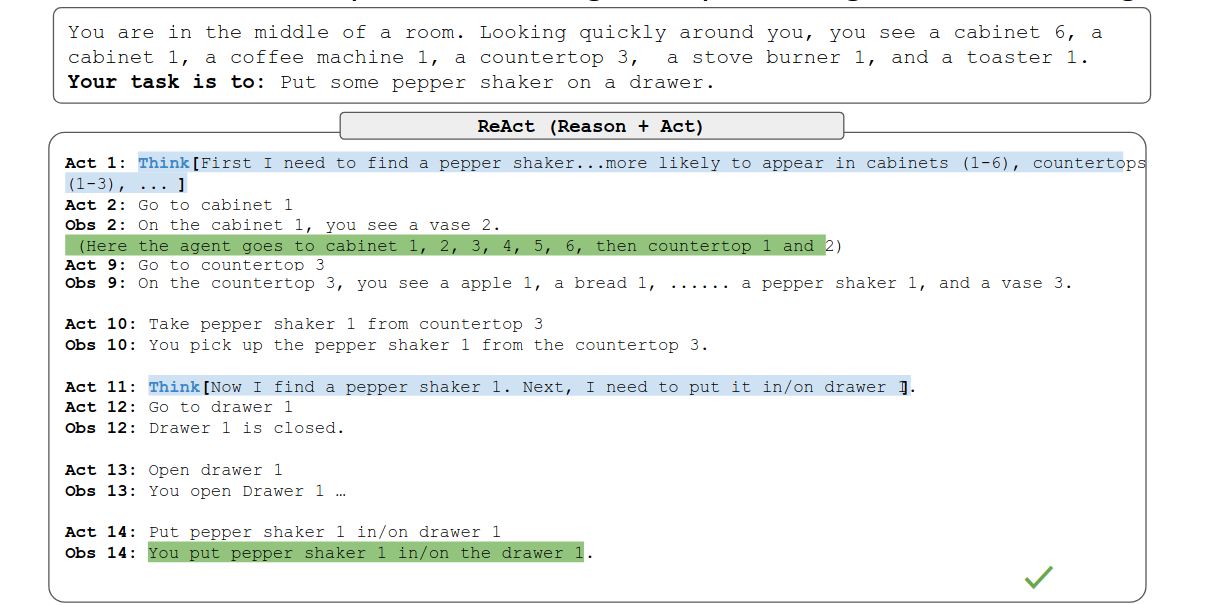
两者对比,我们可以发现加了reason,效果好了很多。think部分这像不像是人类的碎碎念?
ALFWorld Example: Human-in-the-loop Control
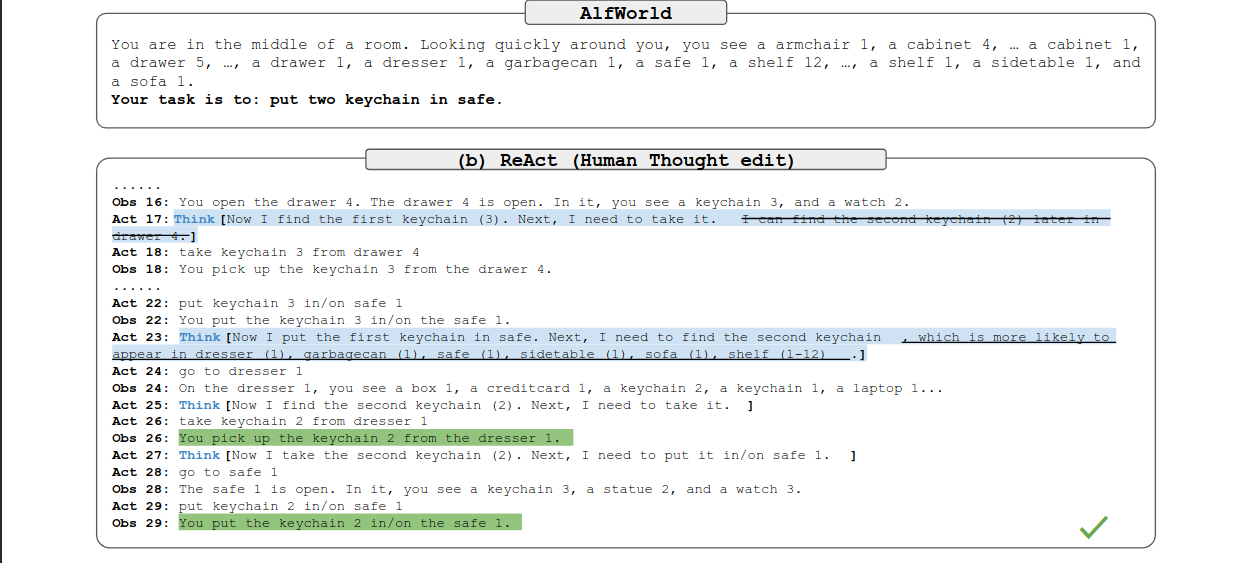
人为去修改他的reasoning也能更正他的acting。
Finetuning > Prompting
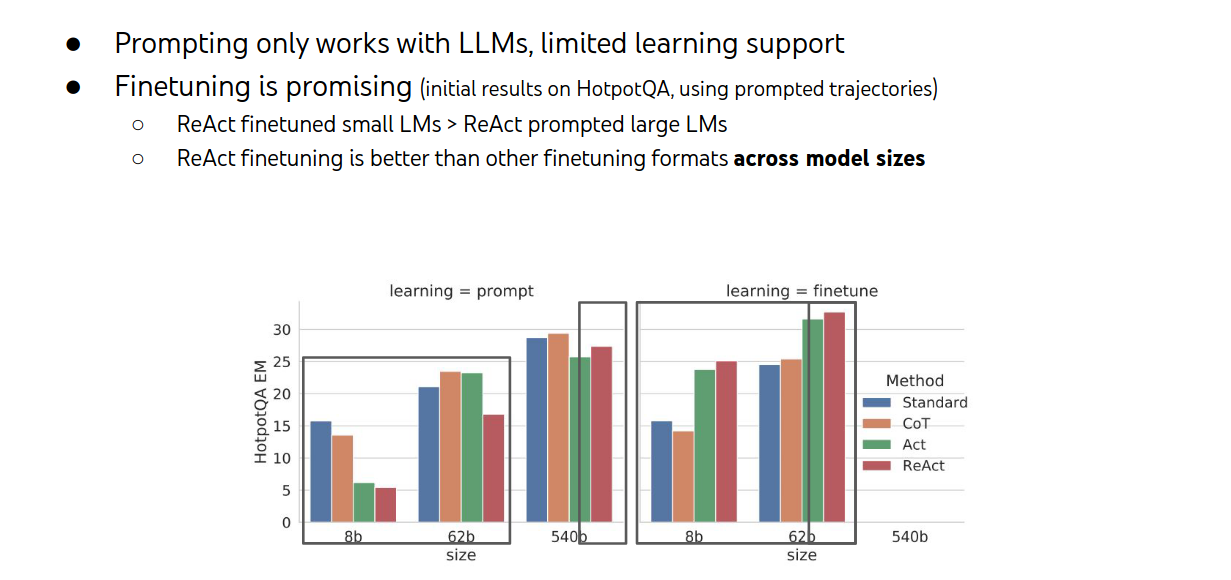
ReAct: Summary

如果有一个更长期的更能操作的memory是不是就更好了!这个想法引出了下一个机制。
Mechanism 2: Learning
(Reinforcement) Learning
Behavior -> Feedback -> Update -> Better Behavior
Learning: Feedback
还是思考人是怎么进行这个人物的。

语言的feedback是比做错做对给出的0和1要更加丰富的,也更符合人的学习习惯。
Learning: Update

traditional Q-learning.参数更新
gpt4没有办法更改参数。
Reflexion: “Verbal” RL

我们看一个例子剩下的不看,全是说性能非常好
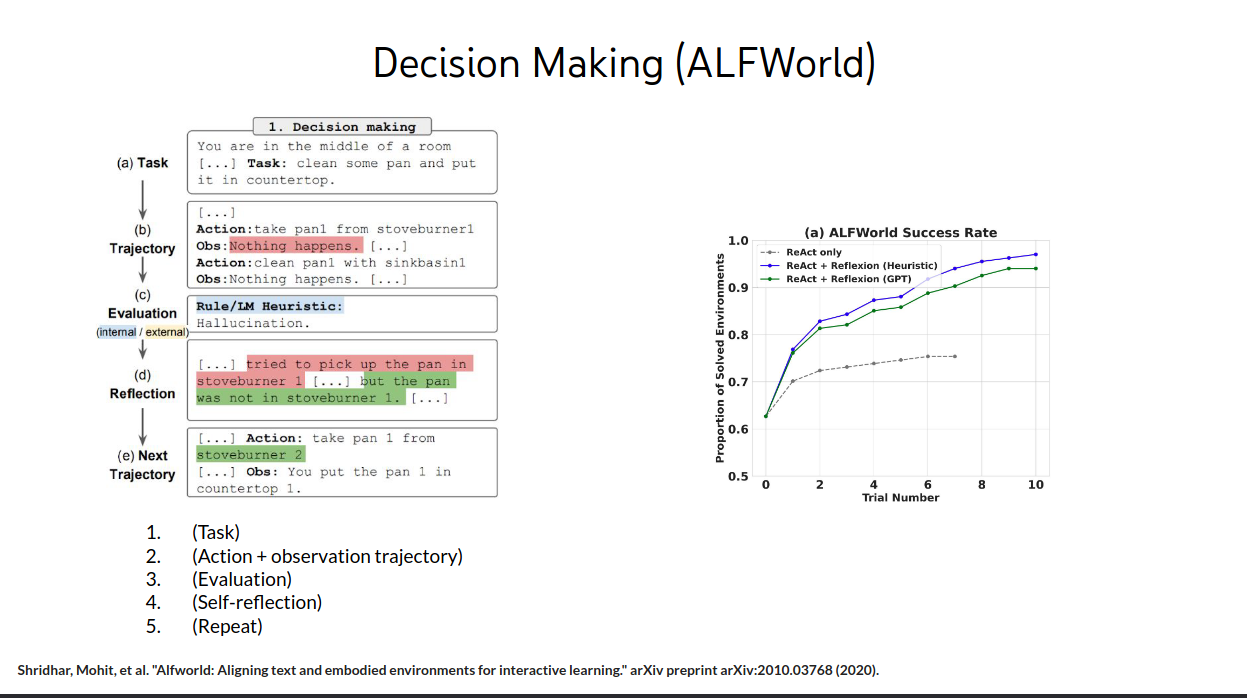
经验必须压缩成知识给gpt,他才会学,之前的text知识他很难学习到


Reflexion: Summary

reflection很好很好,但是prompt来实现reflection感觉只是一种过度,可能会存在更好的泛用化方式
一种任务只能学习一种,对其他的task没有帮助!!
memory结构的研究是一个可以研究的方向!!
人脑对知识是编码提取的,学习之后归因到大脑,但是gpt只能在prompt方面学习,不能修改参数。
能不能既学习prompting同时修改parameters?
reflection—>训练LM—>交互获得知识—>知识压缩进小模型
Mechanism 3: Planning
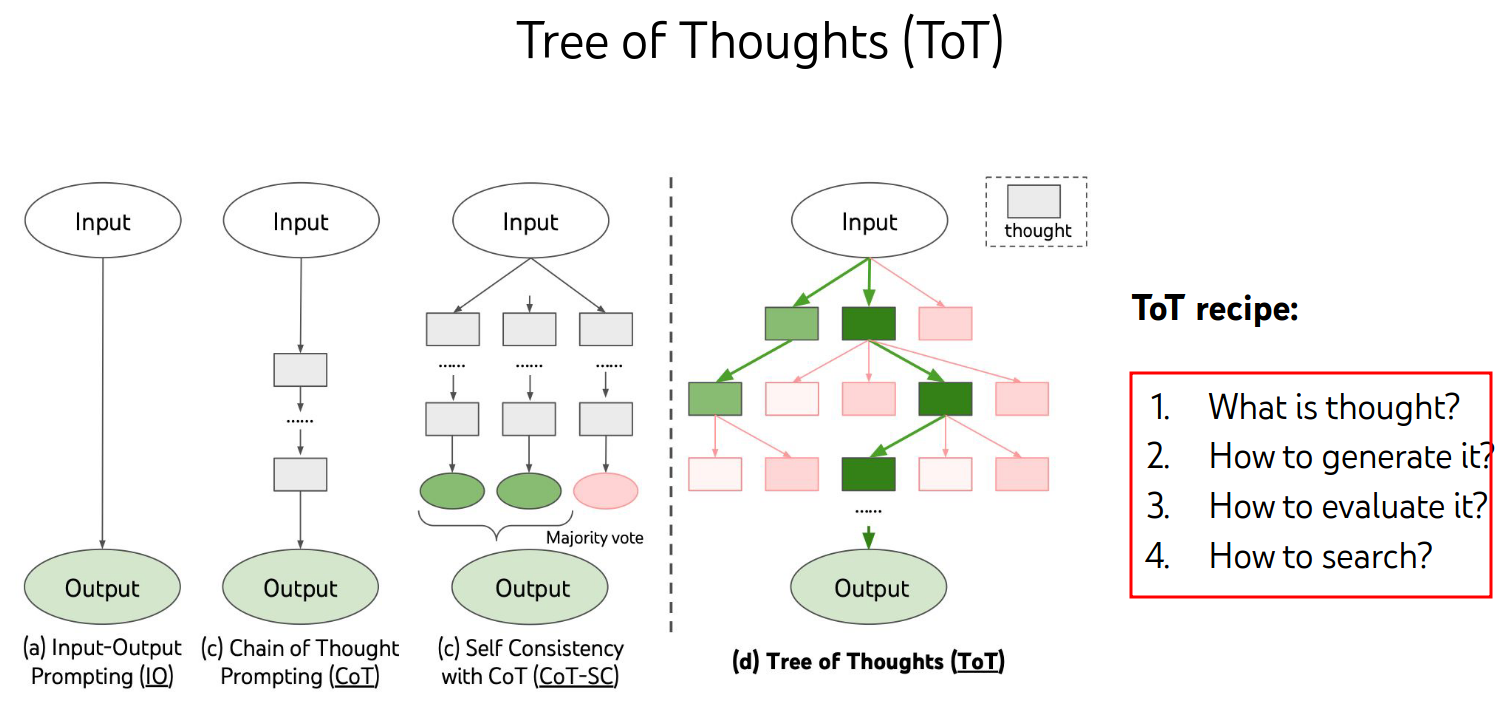
ToT

幻觉的出现,gpt只能通过前面的text来预测后面的文本,因此如果第一步就输出错了,那么后面就开始出现幻觉
0.Why Tree Search?

1.What is thought?
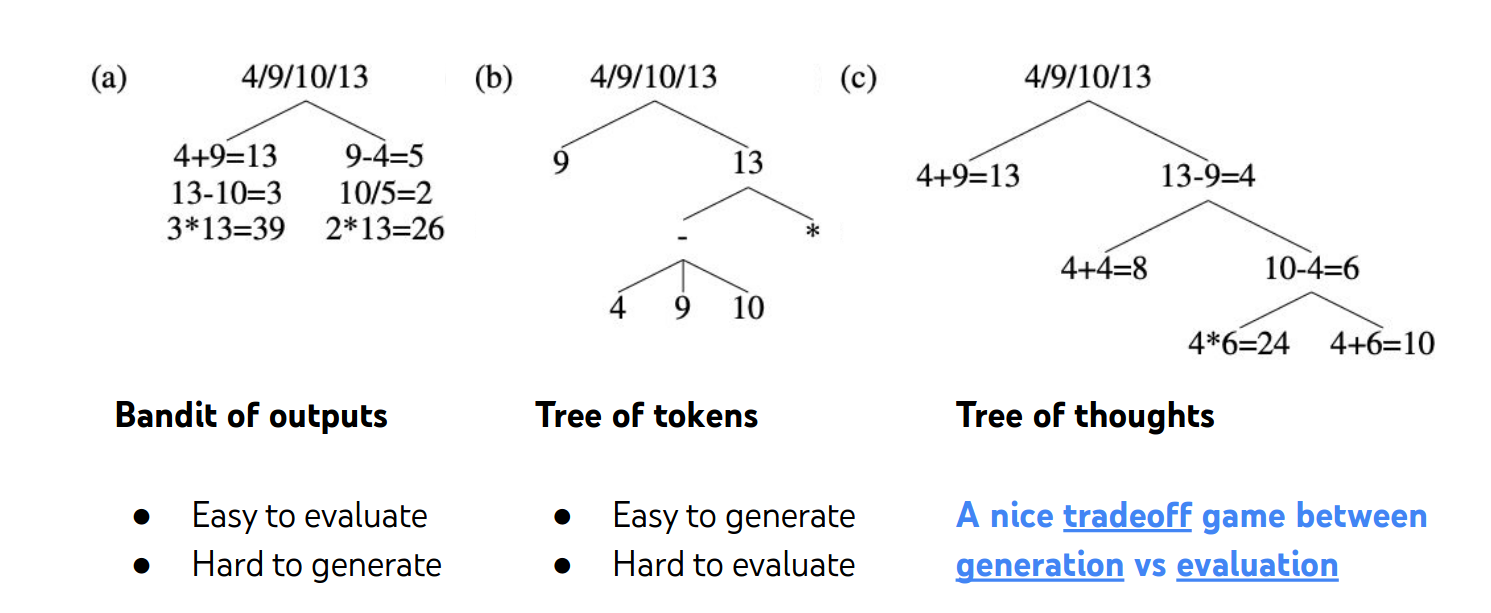
2.How to generate thoughts?


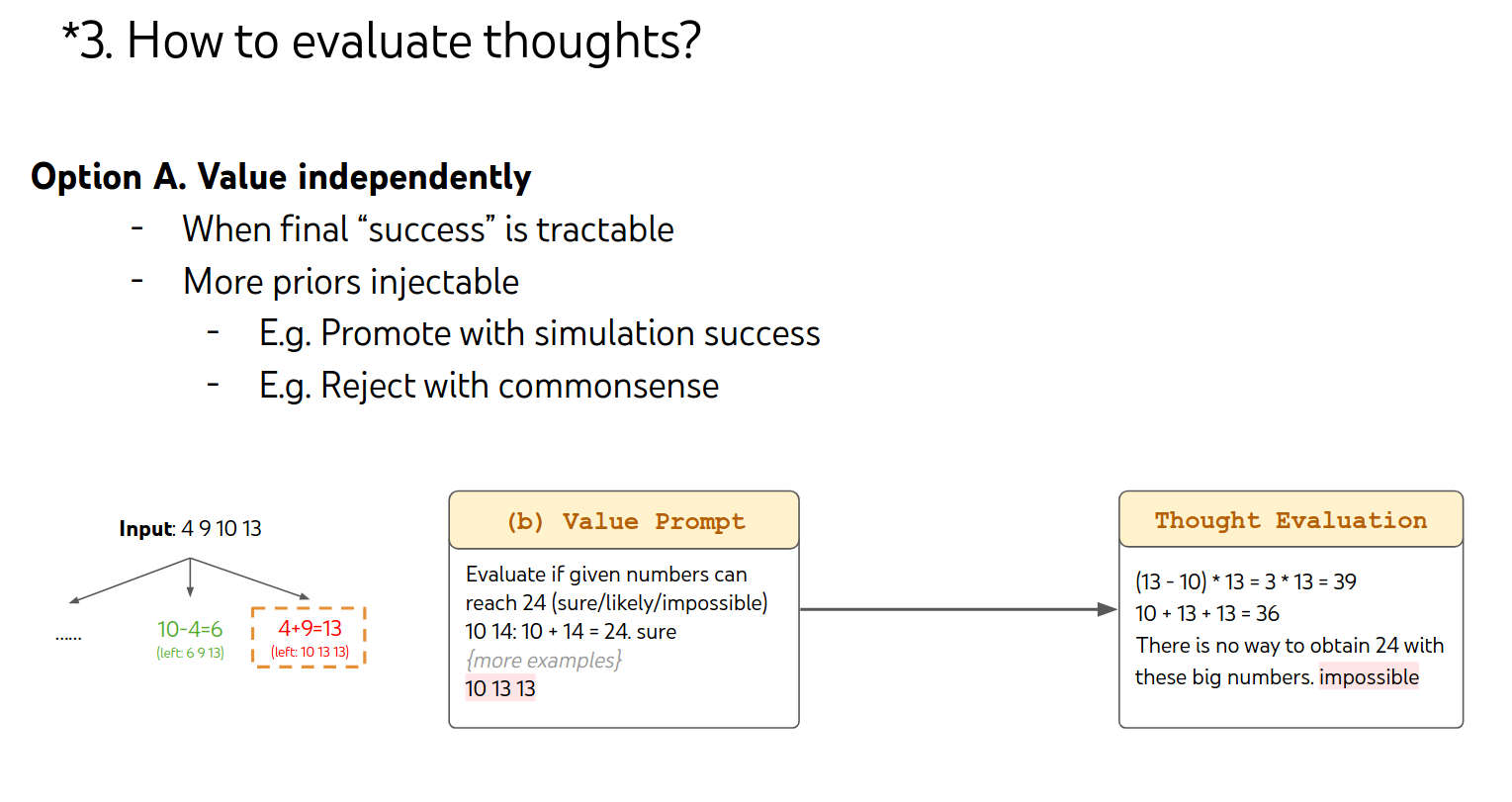
3.How to evaluate thoughts?

4.How to search?

接下来是几个task,去看原来的paper吧。
ToT: Summary
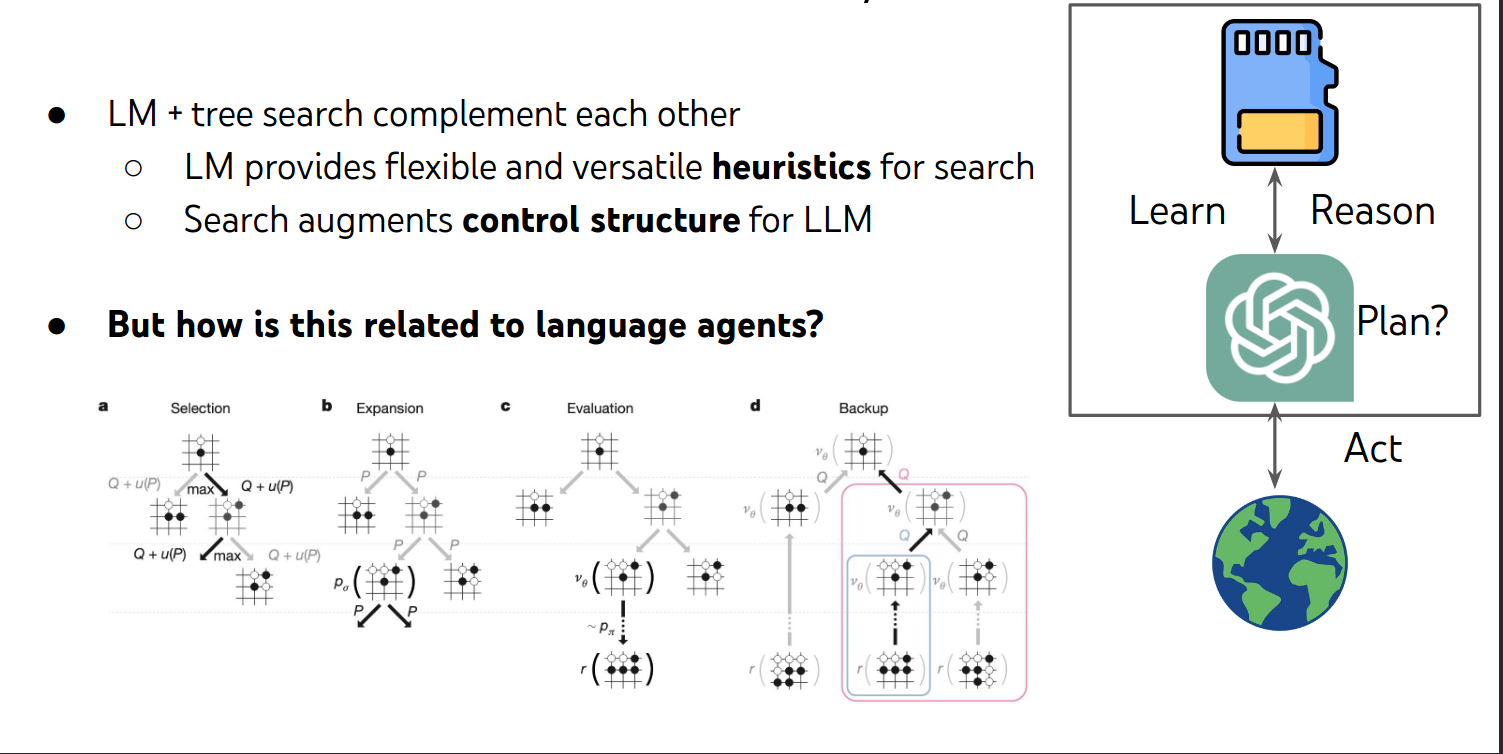
Language Agent

LLM agent可以跟外界交互同时可以跟自己的记忆来交互。
但是RL就只能跟外界来交互。
一个更系统的框架来结合这些想法?
Part II what external environments are needed?
Environment: how to be cheap, fast, yet useful?

Evaluation: how to be cheap, fast, yet high-quality?

Overview
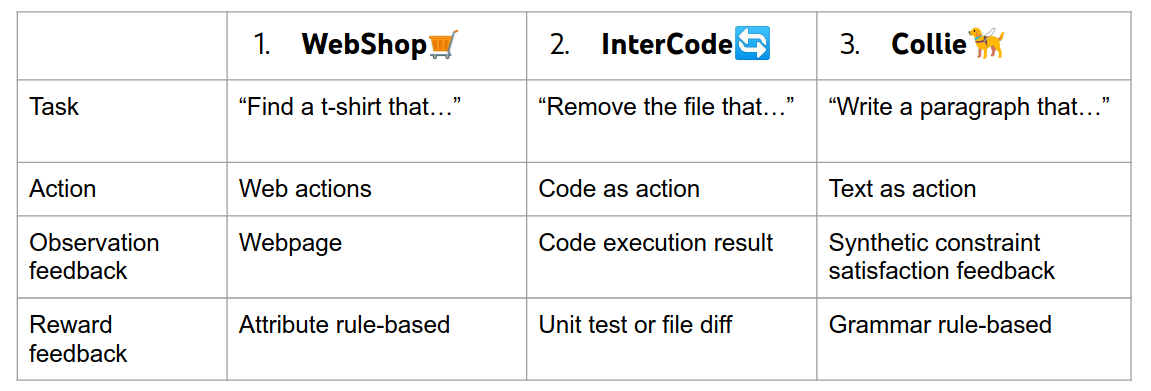
三个交互环境。