ChatGPT Prompt Engineering for Developers
attention
这种技术大概是2023年中旬,现在大模型的能力提升很多,我认为不要太过注重prompt工程,就按照跟人之间交待工作一样来提prompt就可以。
Two Types of large language models(LLMs)

Base LLM会从网络上搜索到的脚本进行训练,实际上是一个文字预测。左下角是没有经过Instr Tuned的输出,可以看到他的样本可能是一系列问题。
右边是微调之后的内容,这一部分请去看NTU的prompt教程。
Guidelines for Prompting
原则1:指令清晰具体Clear instruction
策略一:使用分隔符清晰地表示输入的不同部分**,分隔符可以是:```,"",<>,<tag>,<\tag>等。

你可以使用任何明显的标点符号将特定的文本部分与提示的其余部分分开。
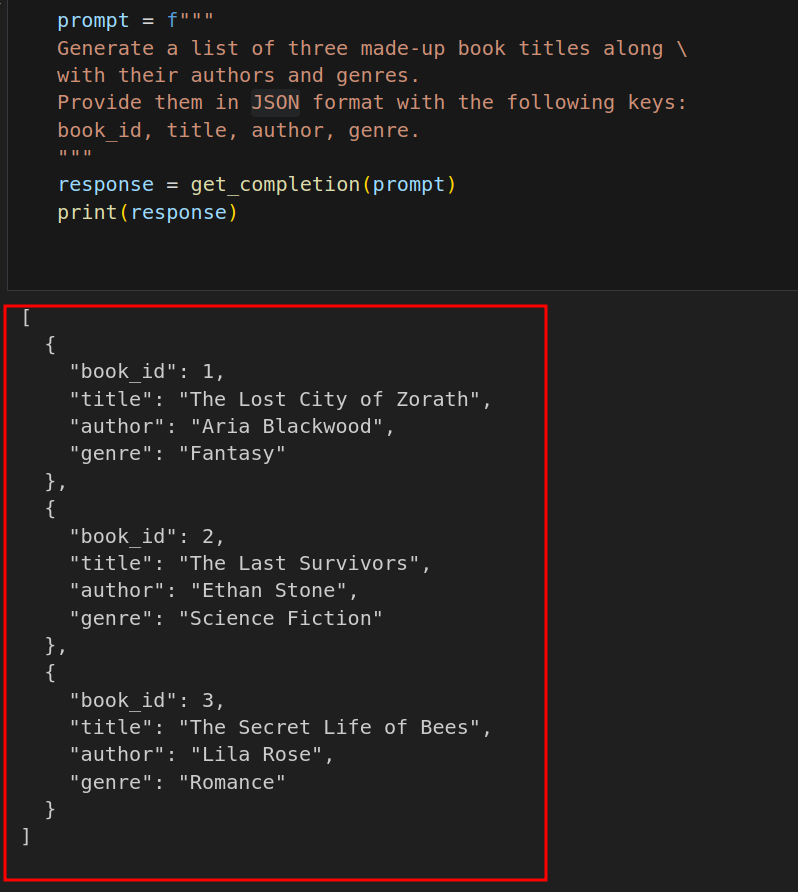
策略二:要求一个结构化的输出,可以是 Json、HTML 等格式。
策略三:要求模型检查是否满足条件。如果任务做出的假设不一定满足,我们可以告诉模型先检查这些假设,如果不满足,指示并停止执行。
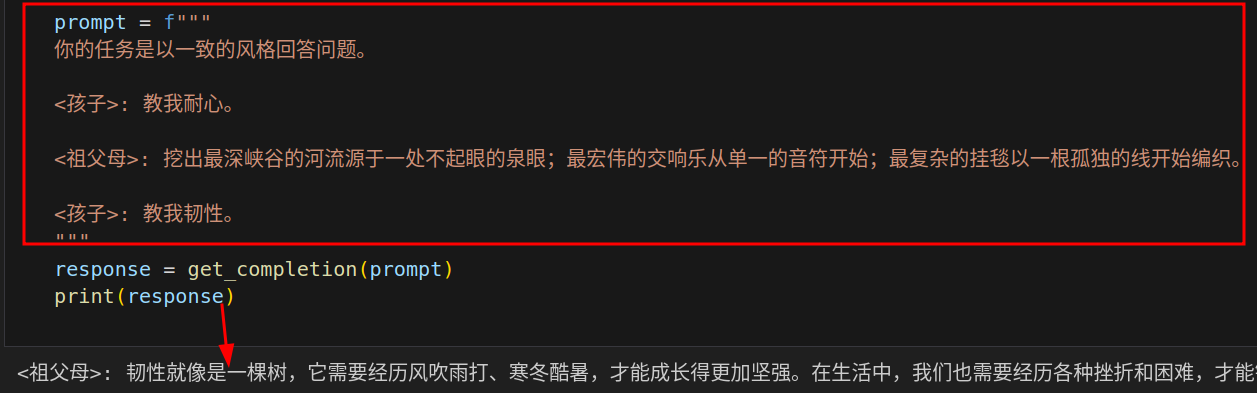
策略四:Few-shot提供少量示例,即在要求模型执行实际任务之前,提供给它少量成功执行任务的示例。
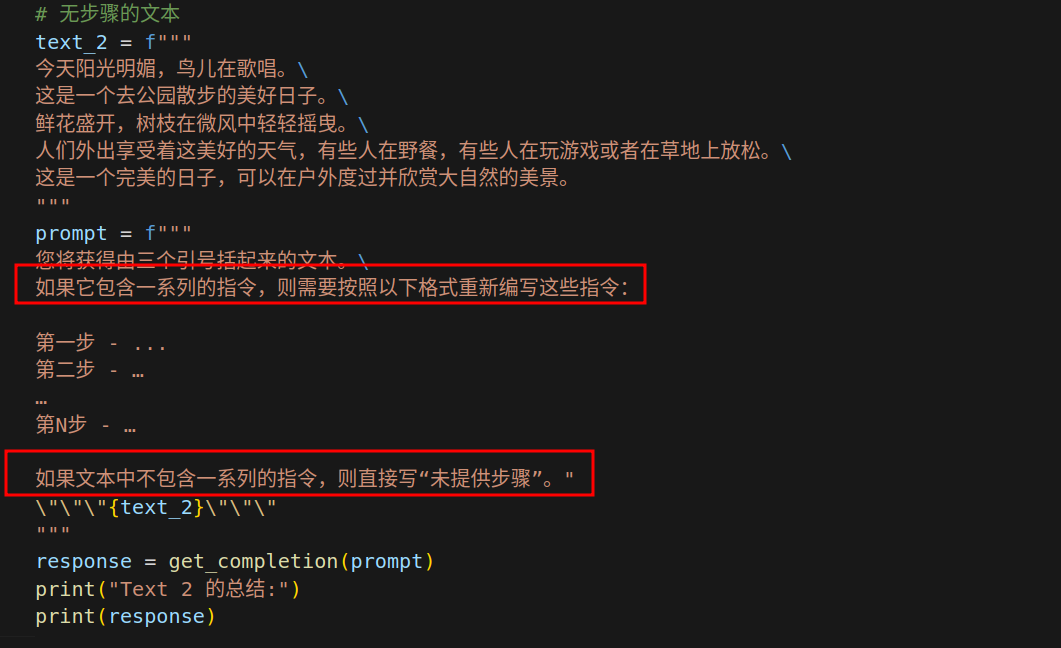
原则二:给模型时间去思考More time to think
如果模型匆忙地得出了错误的结论,应该尝试重新构思查询,请求模型在提供最终答案之前进行一系列相关的推理。换句话说,如果给模型一个在短时间或用少量文字无法完成的任务,它可能会猜测错误。这种情况对人来说也是一样的。
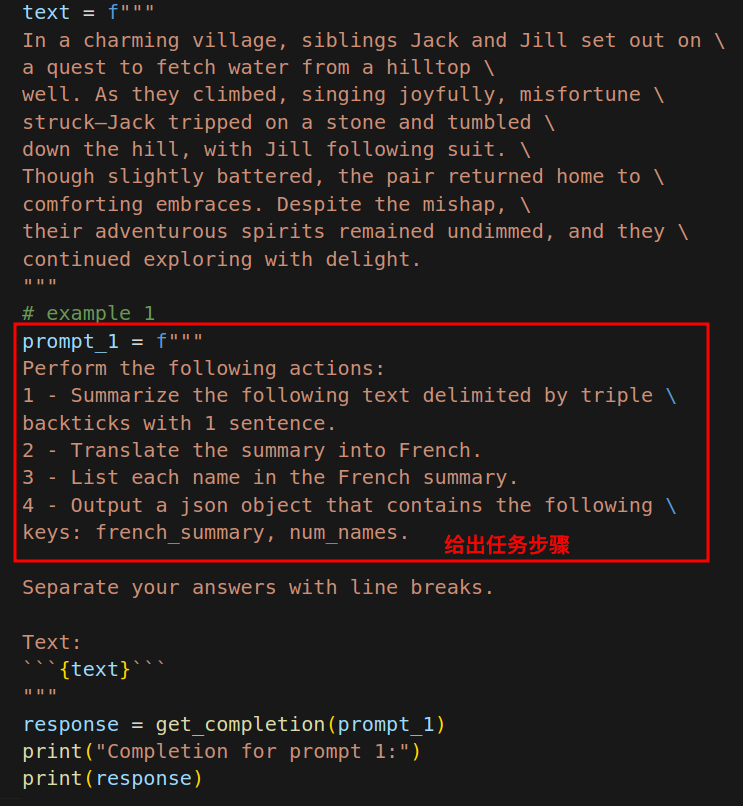
策略一:指定完成任务所需的步骤 Chain of Thought?
给定一个复杂任务,给出完成该任务的一系列步骤。
策略二:指导模型在下结论之前找出一个自己的解法
有时候,在明确指导模型在做决策之前要思考解决方案时,我们会得到更好的结果。
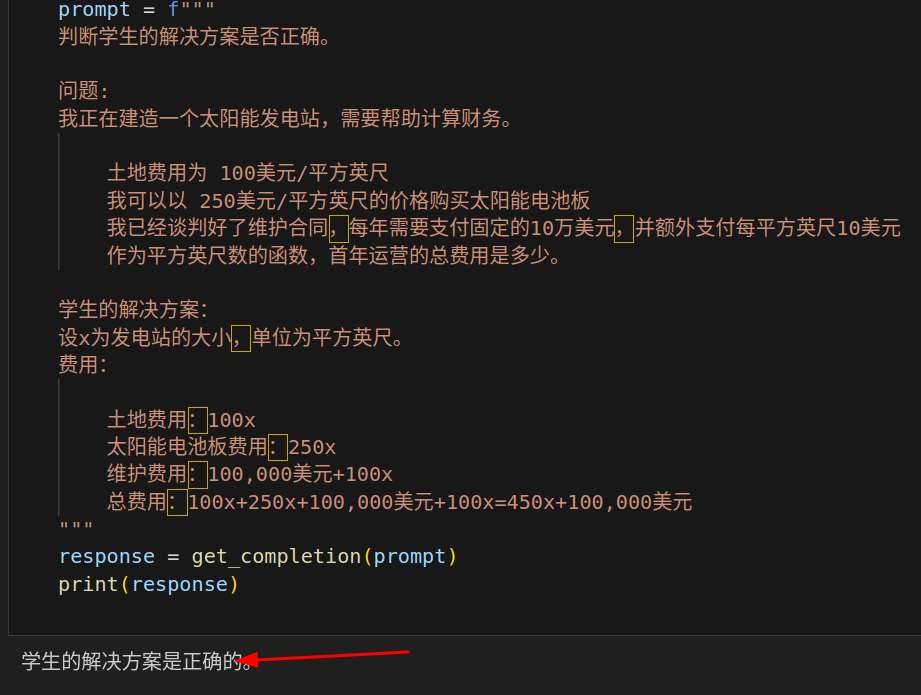
实际上学生是错误的!!
可以通过指导模型先自行找出一个解法来解决这个问题。
在接下来这个 Prompt 中,我们要求模型先自行解决这个问题,再根据自己的解法与学生的解法进行对比,从而判断学生的解法是否正确。
Hallucinations局限性-幻觉
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
如果模型在训练过程中接触了大量的知识,它并没有完全记住所见的信息,因此它并不很清楚自己知识的边界。这意味着它可能会尝试回答有关晦涩主题的问题,并编造听起来合理但实际上并不正确的答案。我们称这些编造的想法为幻觉Hallucinations。
What's more
You can either set it as the OPENAI_API_KEY environment variable before using the library:
!export OPENAI_API_KEY='sk-...'
Or, set openai.api_key to its value:
import openai
openai.api_key = "sk-..."
Iterative迭代
Core idea:先写prompt再逐步改进。
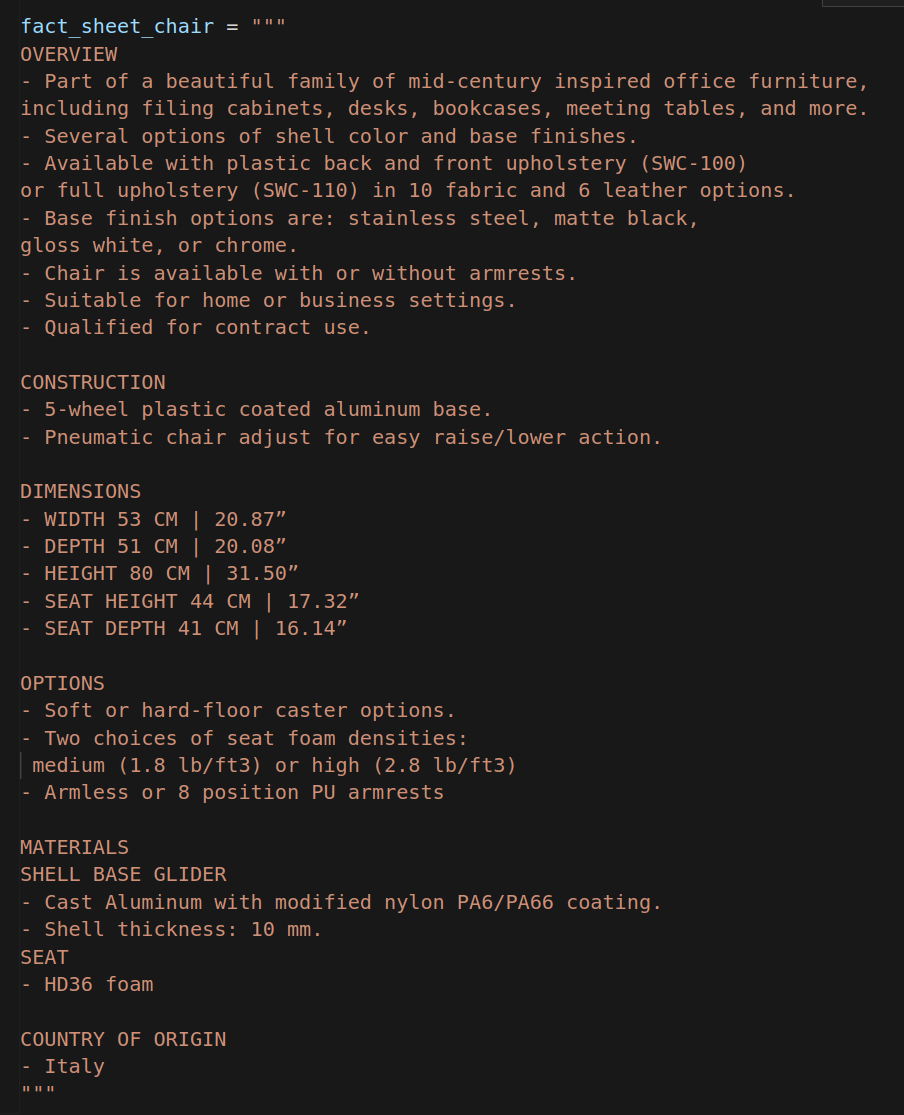
现在有这样一个任务
根据这样的一个产品事实清单来生成一个营销产品的说明
输出结果

Issue 1:The text is too long 文本过长
直接用提示词来规定长度。
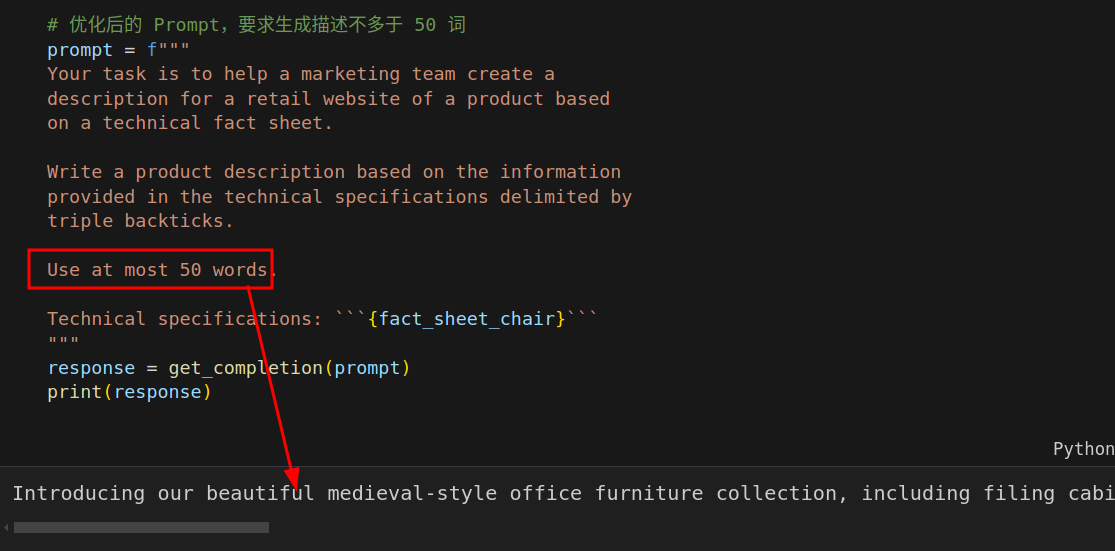
LLM在遵循非常精确的字数限制方面表现得还可以,但并不那么出色。有时它会输出60或65个单词的内容,但这还算是合理的。这原因是 LLM 解释文本使用一种叫做分词器的东西,但它们往往在计算字符方面表现一般般。
Issue 2:Text focuses on the wrong details
第二个问题是,这个网站并不是直接向消费者销售,它实际上旨在向家具零售商销售家具,他们会更关心椅子的技术细节和材料。
解决方法:要求它专注于与目标受众相关的方面。
Issue 3. Description needs a table of dimensions
通常值得首先尝试编写 Prompt ,看看会发生什么,然后从那里开始迭代地完善 Prompt,以逐渐接近所需的结果。因此,许多成功的Prompt都是通过这种迭代过程得出的。
summary
本章的主要内容是 LLM 在开发应用程序中的迭代式提示开发过程。开发者需要先尝试编写提示,然后通过迭代逐步完善它,直至得到需要的结果。关键在于拥有一种有效的开发Prompt的过程,而不是知道完美的Prompt。对于一些更复杂的应用程序,可以对多个样本进行迭代开发提示并进行评估。最后,可以在更成熟的应用程序中测试多个Prompt在多个样本上的平均或最差性能。
temperature
温度越高回复的信息随机性越大,越低,回复的内容基本一致。