番外 Reasoning and Agents
来自CS224N Lecture 14: Reasoning and Agents
Reasoning(with Large Language Models)
What is Reasoning?
Using facts and logic lo to arrive at an answer.
Deductive Reasoning演绎推理
Use logic to go from premise to firm conclusion
Premise: All mammals have kidneys
Premise: All whales are mammals
Conclusion: All whales have kidneys
Inductive Reasoning归纳推理
From observation, predict a likely conclusion
Observation: When we see a creature with wings, it is usually a bird
Observation: We see a creature with wings.
Conclusion: The creature is likely to be a bird
Abductive Reasoning反向推理
From observation, predict the most likely explanation
Observation: The car cannot start and there is a puddle of liquid under the engine.
Likely Explanation: The car has a leak in the radiator
Reasoning: Formal vs Informal
Formal Reasoning: Follows formal rules of logic along with axiomatic公理化 knowledge to derive conclusions.
Informal Reasoning: Uses intuition, experience, common sense to arrive at answers.
For most of this lecture, by “reasoning” we mean informal deductive reasoning,
often involving multiple steps
Reasoning in Large Language Models
Large Language models are REALLY GOOD at predicting plausible continuations合理的延续 of text (Lecture-9), that respect constraints in the input (Lecture 10,11), and align well with human preferences (Lecture-10, 11).
Chain-of-thought prompting
https://arxiv.org/pdf/2201.11903
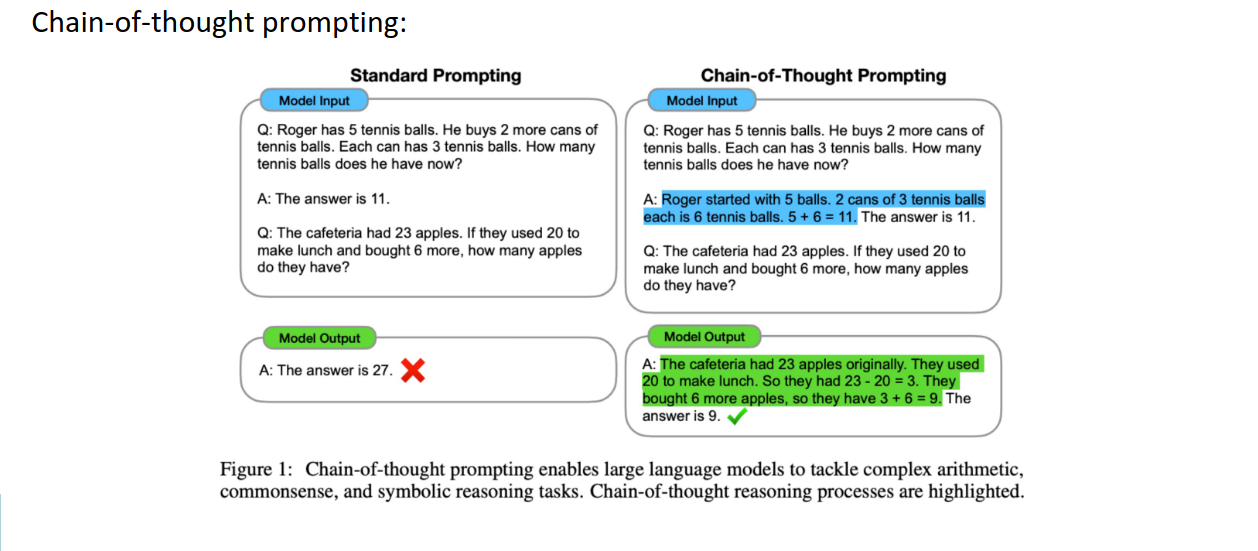
Zero-shot CoT prompting
https://arxiv.org/pdf/2205.11916

“零样本”(左下角)直接询问模型答案,但没有任何逐步推理的提示,往往容易导致错误答案(如图片中的例子给出的错误答案为8)。
“少样本”(Few-shot)是通过给模型几个类似问题的例子,让模型学习并推广到新问题。
CoT with "Self-consistency”
https://arxiv.org/pdf/2203.11171
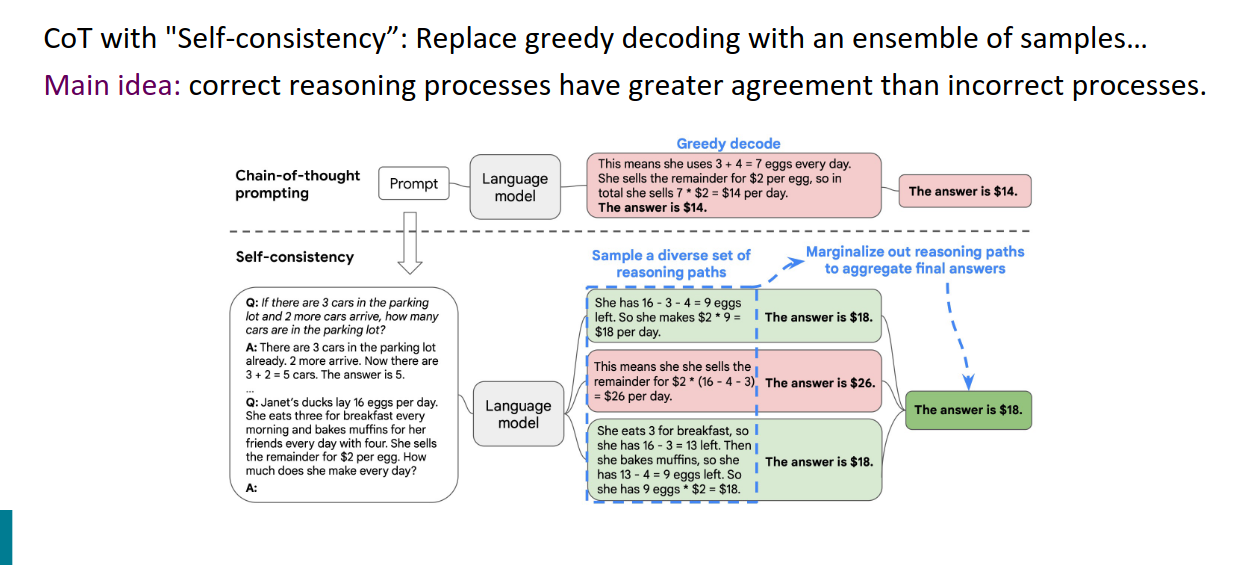
贪婪解码(Greedy decoding) 上面的:一种常见的解码方法,每次选择最有可能的单词生成推理路径。这个过程可能只得到一个解答,像图中的例子中模型得出的答案是 $14。
自一致性(Self-consistency):代替单一的贪婪解码,通过生成多个不同的推理路径,来构建一个答案的多样化集合。这些推理路径可能给出不同的结果(例如图中的 $18 和 $26),之后通过对这些推理路径进行"边缘化处理",即聚合出最终答案。
benchmarks
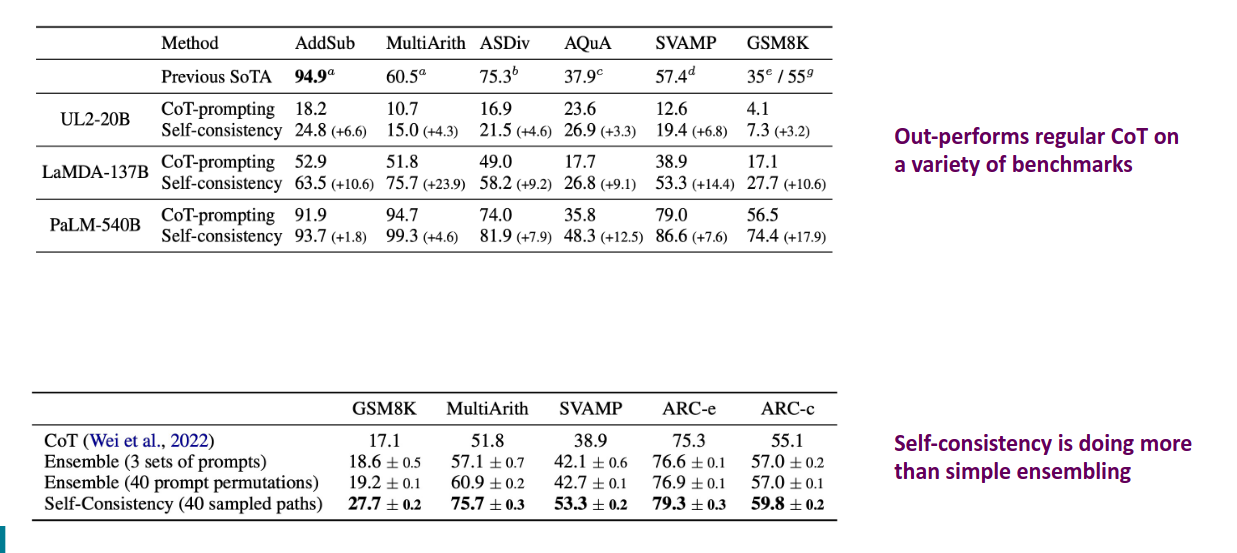
"Ensemble" 是指将多次生成的不同推理路径进行组合,最后得出一个聚合的结果。
Least-to-Most prompting
https://arxiv.org/pdf/2205.10625
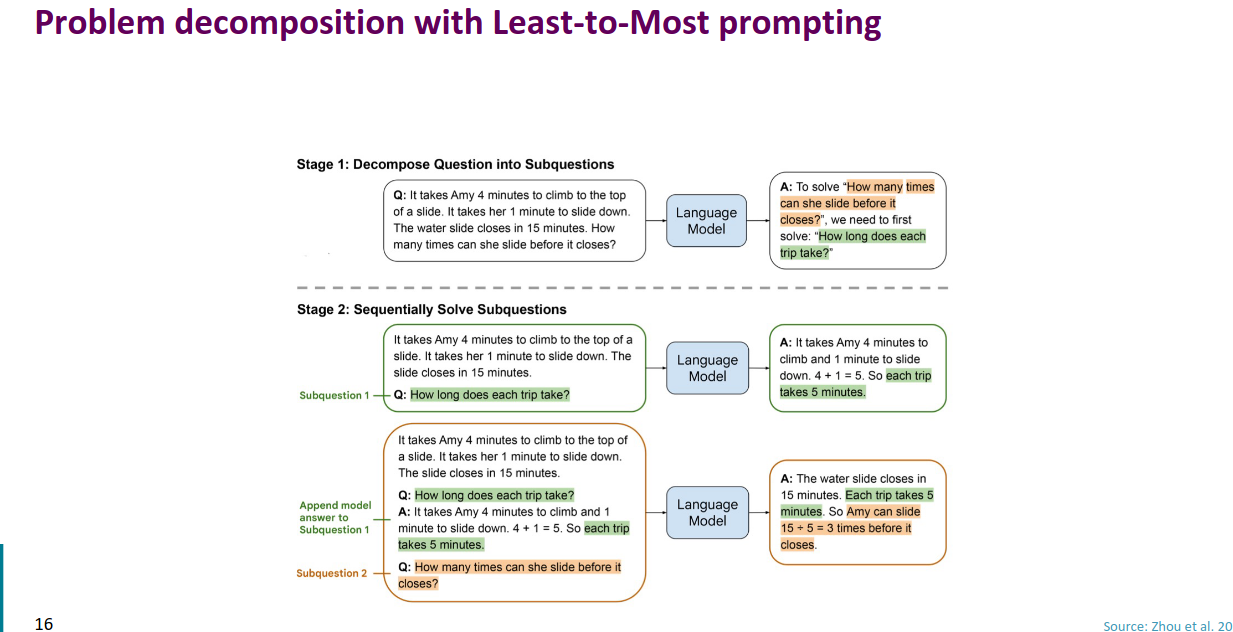
核心思想是通过将复杂问题分解为一系列更简单的子问题,并逐步解决这些子问题来提高模型的推理能力。
这种“从简单到复杂”的方法,使得模型能够更好地应对比训练示例更复杂的问题,与传统的“思维链提示”(Chain-of-Thought Prompting)相比,Least-to-Most 提示在任务难度较大的情况下表现更优越。
Least-to-Most vs Chain of Thought

两种提示词的对比。
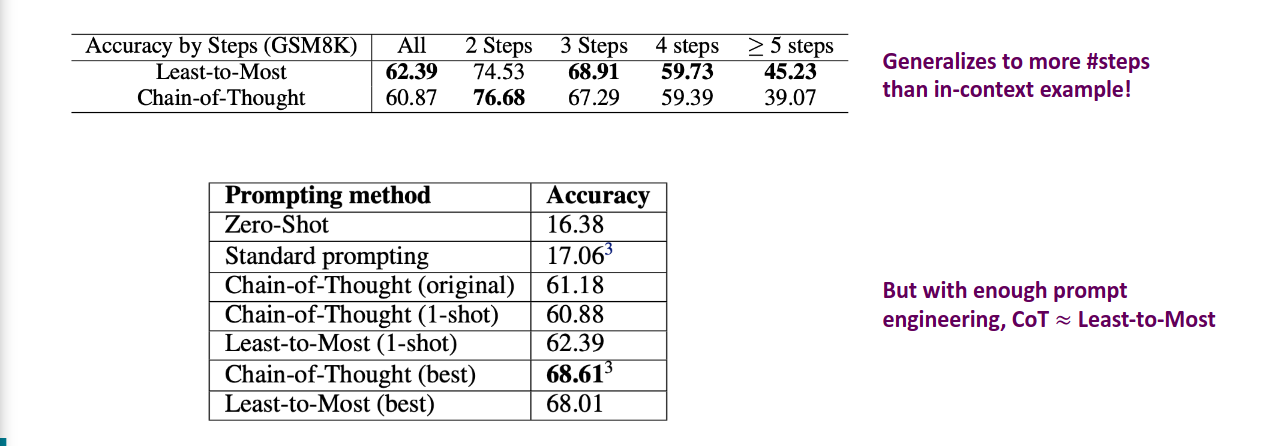
有点鸡肋??
Orca: Instruction-tuning small LMs with CoT Rationales
https://arxiv.org/pdf/2306.02707

- Collect a wide variety of instructions from the FLAN-v2 collection.
- Prompt GPT4 or ChatGPT with these instructions along with a system message

- Finetune Llama-13b on outputs generated via ChatGPT + GPT4,这一步骤似乎是要把他thought的过程也要提供给小模型,让小模型跟着大模型学习。
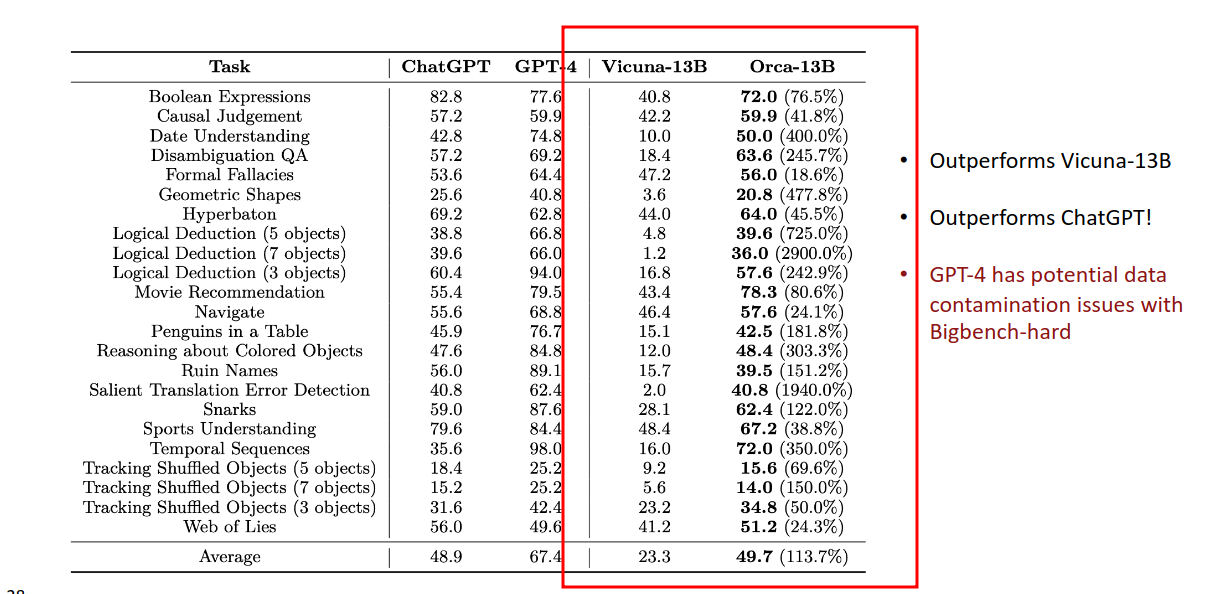
-
Orca-13B 的微调:Orca 的微调专注于使用 GPT-4 或 ChatGPT 的 CoT 输出。Orca 的训练数据不仅仅是直接的问答数据,还包括了 GPT-4 或 ChatGPT 给出的详细推理步骤。这些步骤通常展示了如何一步步从问题推导到最终答案,重点在于解释整个推理过程。
-
Vicuna-13B 的微调:Vicuna-13B 则主要聚焦于对话数据的微调。它通过人类对话数据进行训练,使其在对话任务中表现得更自然、符合人类对话的风格。虽然它也使用了大模型的输出进行训练,但更多集中于对话和交流场景,而不是专注于复杂推理过程的解答。
Reasoning by Finetuning LMs on their own outputs?
https://arxiv.org/pdf/2312.06585
ReSTEM alternates between the following two steps:
- Generate (E-Step): Given reasoning problem, sample multiple solutions from language model. Filter based on some (problem specific) function (answer correctness for math problems)
- Improve (M-Step): Update the language model to maximize probability of filtered solutions, using supervised finetuning
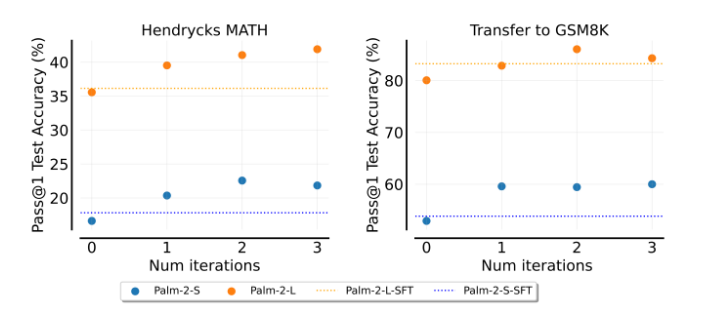
mean it is working!!
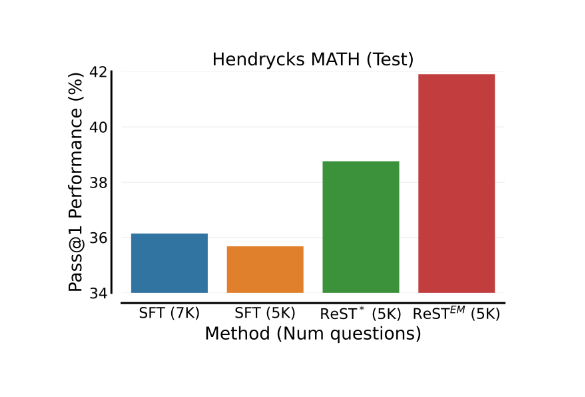
Can Language Models Reason?
CoT Rationales理由 are often not faithful
https://arxiv.org/pdf/2307.13702
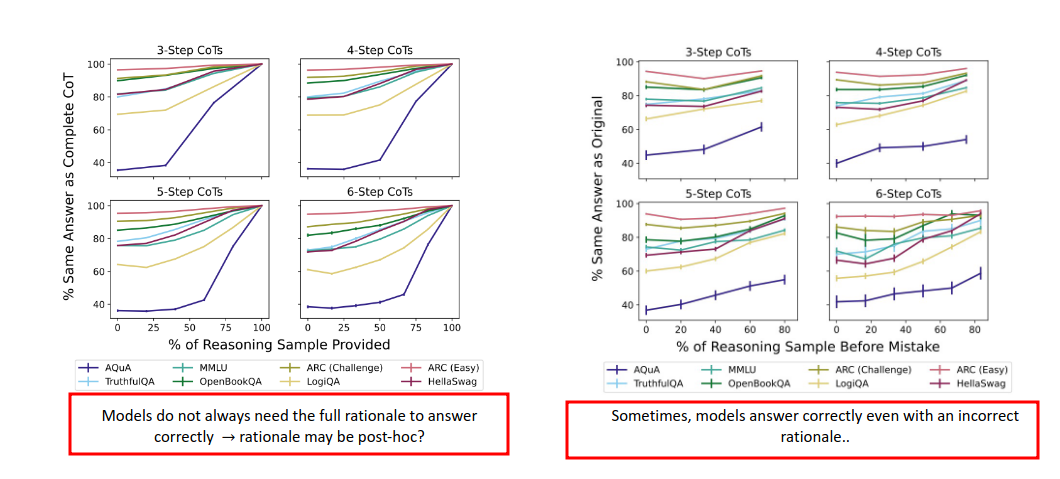
推理的理由是在回答之后吗?也就是说,大模型只是为了满足人类的要求,展现了一个所谓的Rationales,其实他啥也不懂。
有的时候Rationales是错的,然后他也答对了。可疑。
Reasoning vs Memorization: Using Counterfactuals反事实
https://arxiv.org/pdf/2307.02477
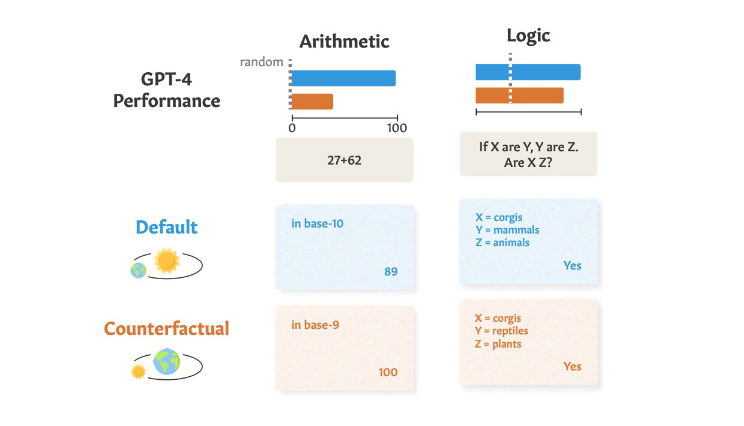
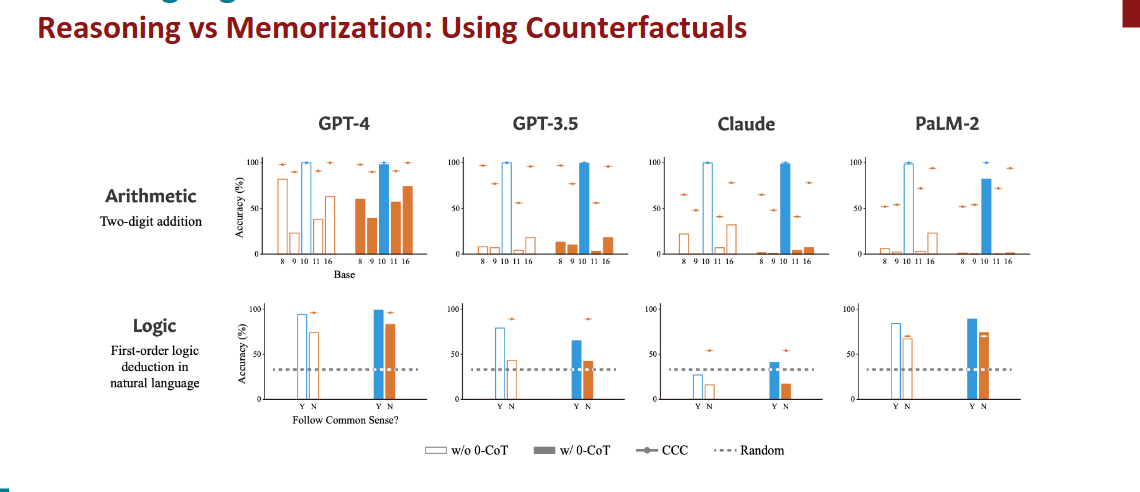
Reasoning vs Memorization: Counterfactuals for Analogical Reasoning
https://arxiv.org/pdf/2308.16118

Language Model Agents
Some Terminology
术语介绍
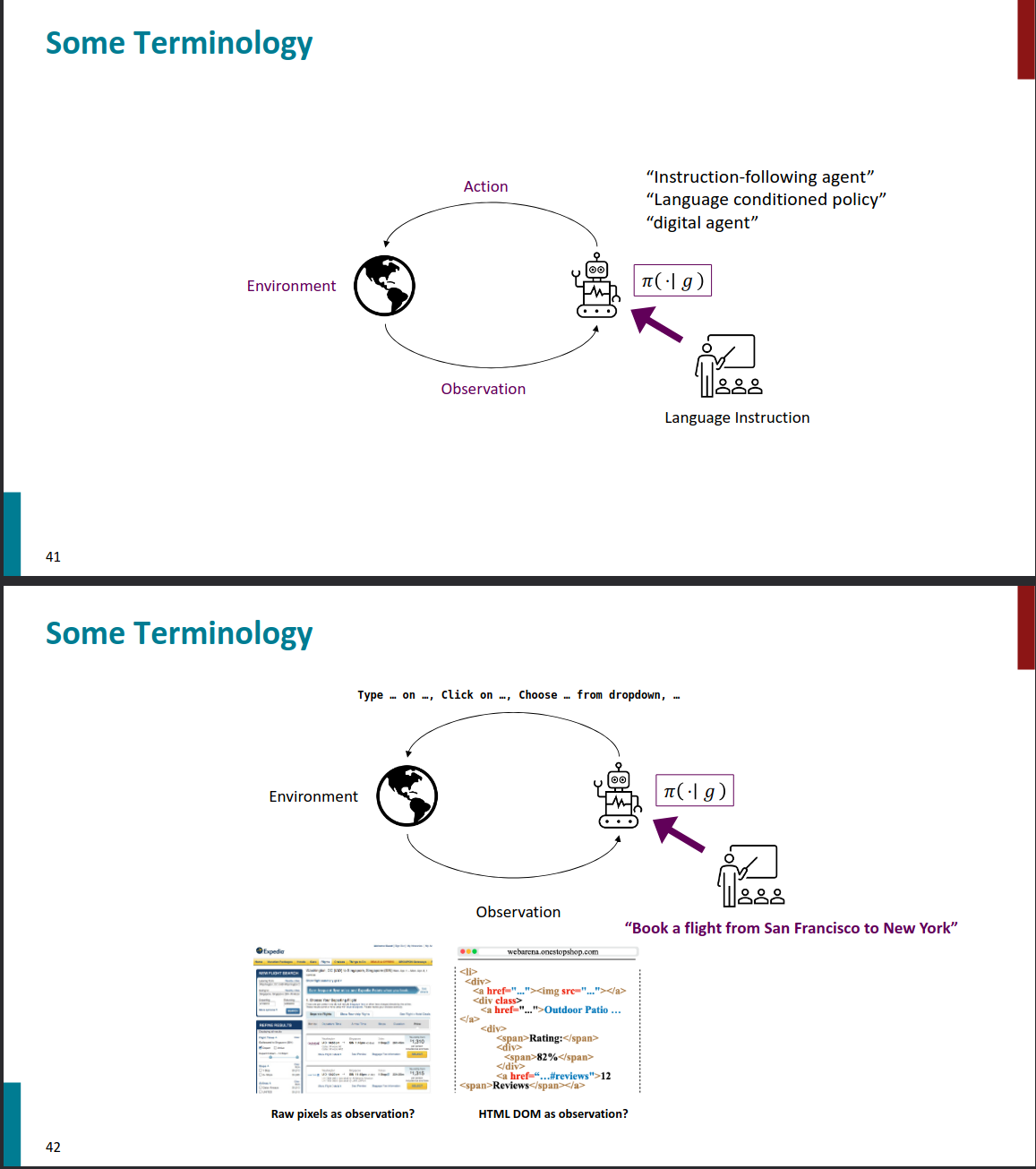
Applications
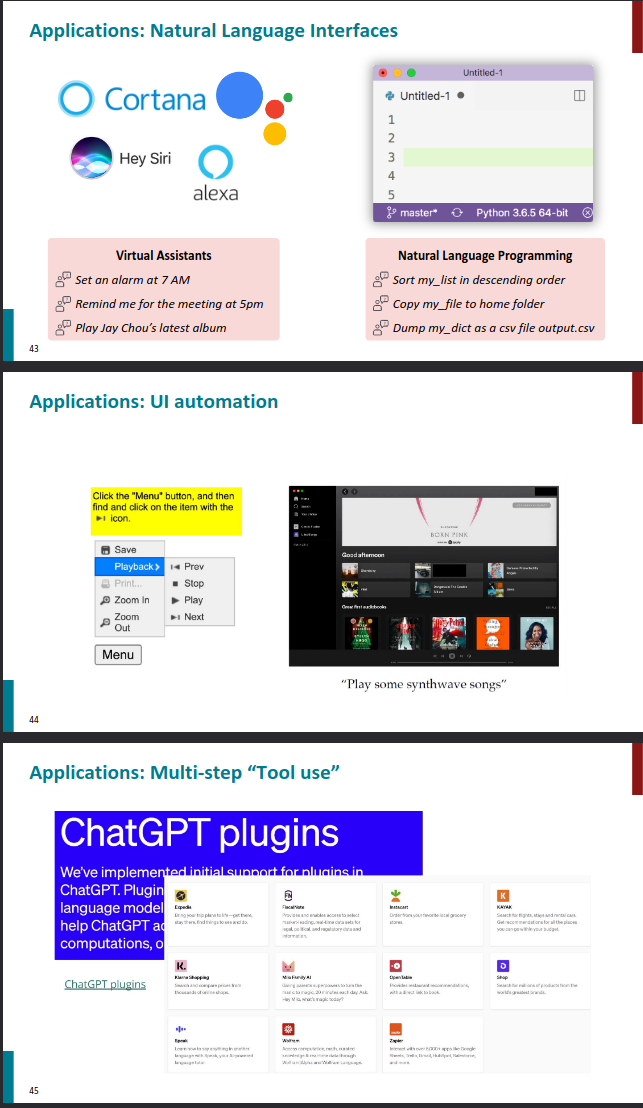
Instruction following agents
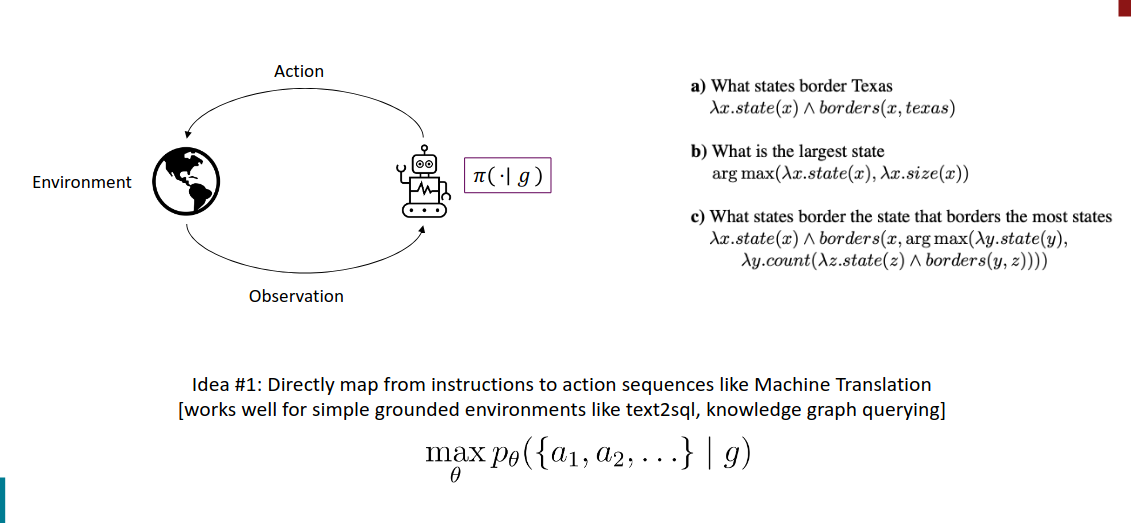
Pre LLMs
https://arxiv.org/pdf/1207.1420
将指令直接映射到动作序列(类似机器翻译)
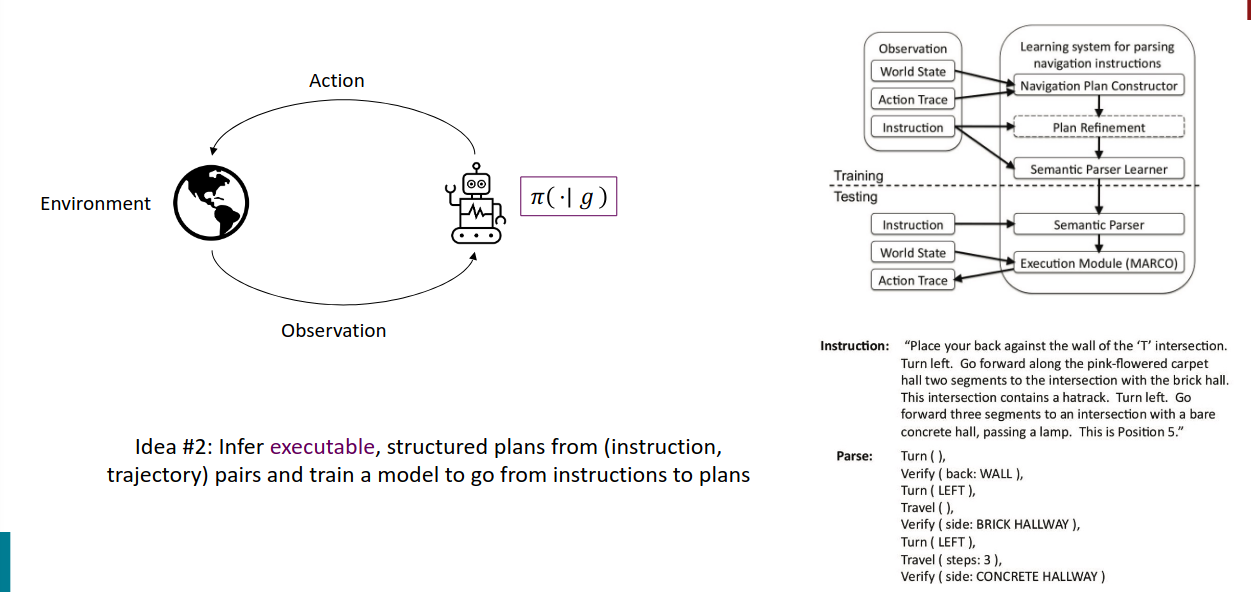
https://www.cs.utexas.edu/~ml/papers/chen.aaai11.pdf
从指令和轨迹对推导结构化计划
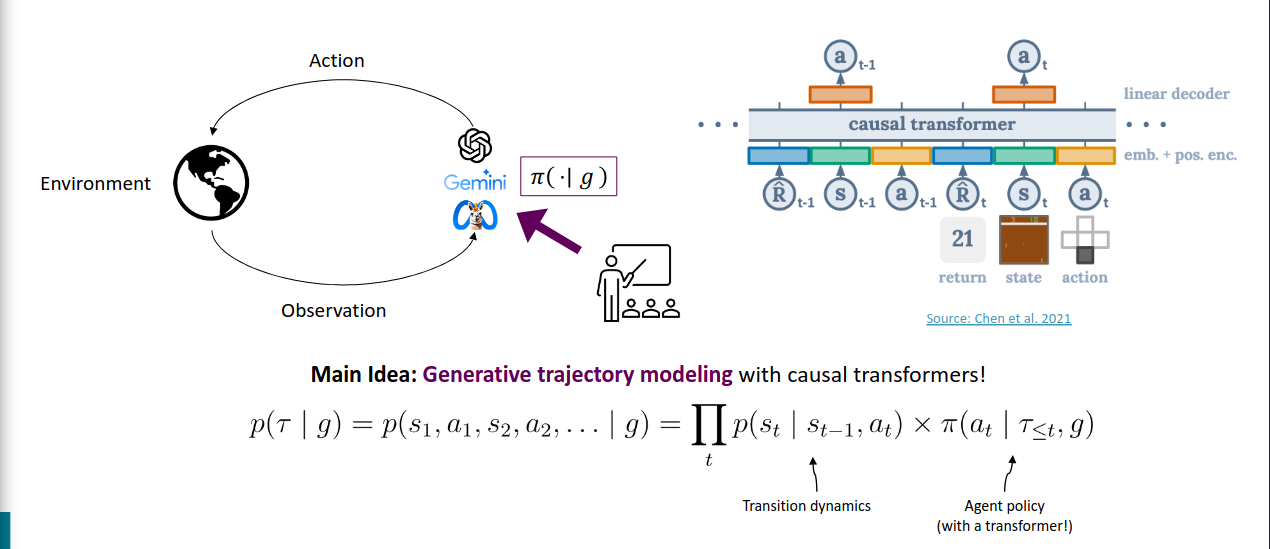
https://aclanthology.org/P09-1010.pdf
使用强化学习直接将指令映射为动作

in 2024
https://arxiv.org/pdf/2106.01345
A Simple Language Model Agent with ReACT
https://arxiv.org/pdf/2210.03629

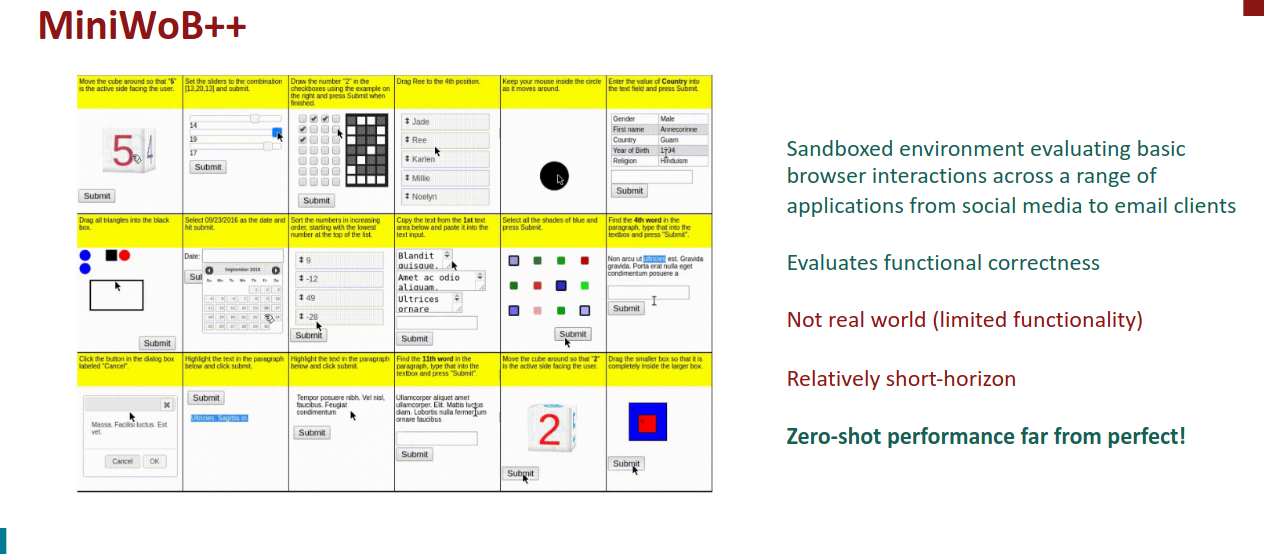
Some popular benchmarks for LM agents

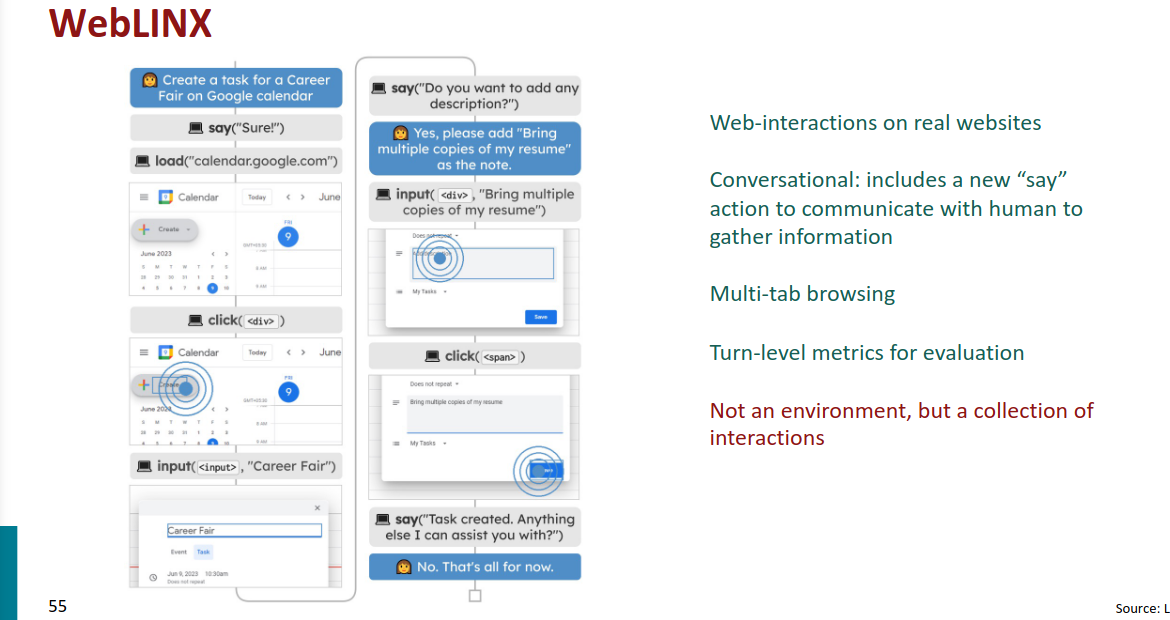
Training data for Language Model Agents

上下文有少量的学习样本的时候,人类依据类似的指令来操作
代理(智能体)能否自主地探索它们的环境,并生成高质量的合成演示(synthetic demonstrations)?换句话说,能否让AI自己探索并生成合适的数据,而不需要依赖于人工提供的示例。
Use Exploration + Model Generated Data!
https://arxiv.org/pdf/2403.08140
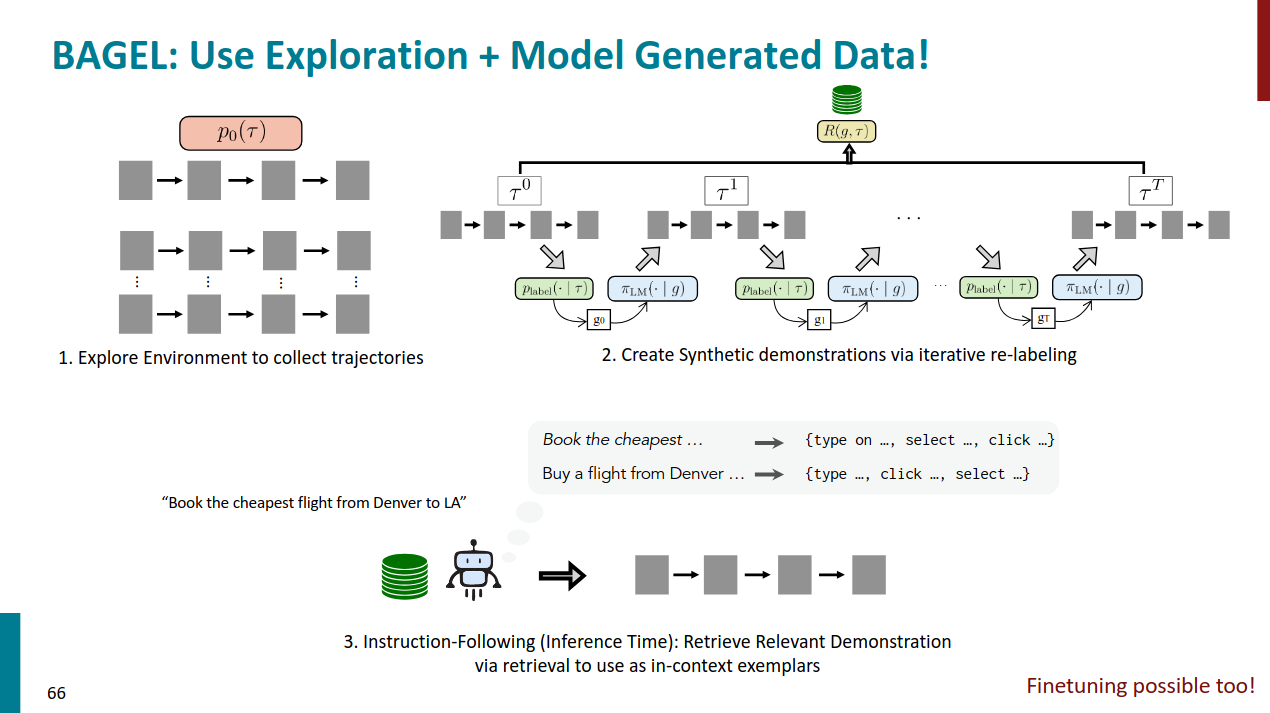
Multimodality
So far, we’ve looked at using text-only language models for agents
This is intractable for real-world UIs with very long HTML
Can we instead operate directly over pixel space?
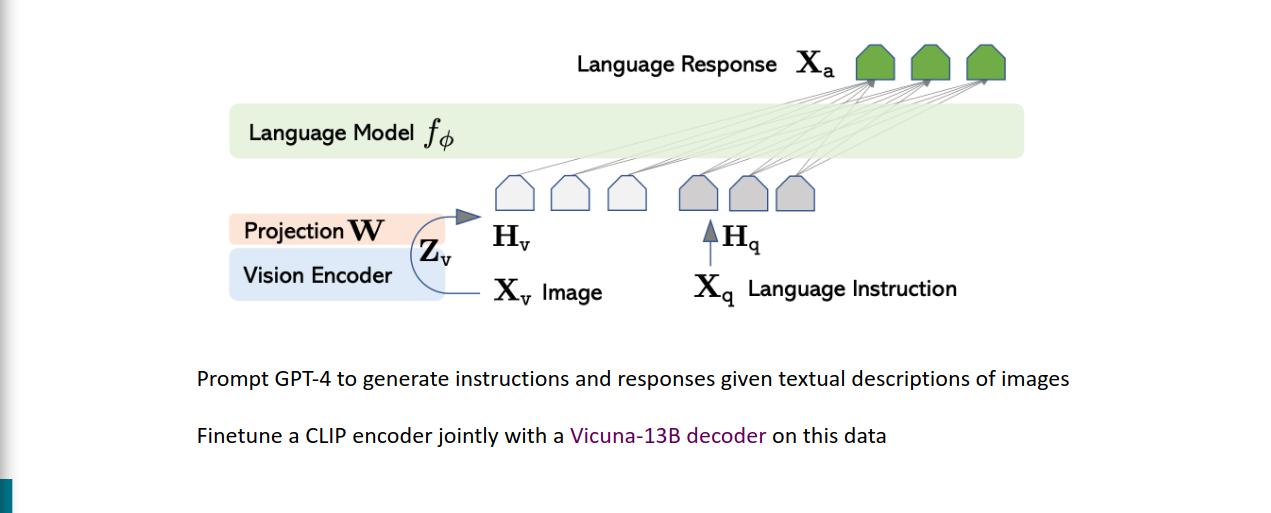
LLaVA
https://arxiv.org/pdf/2304.08485
Pix2Struct
https://arxiv.org/pdf/2210.03347
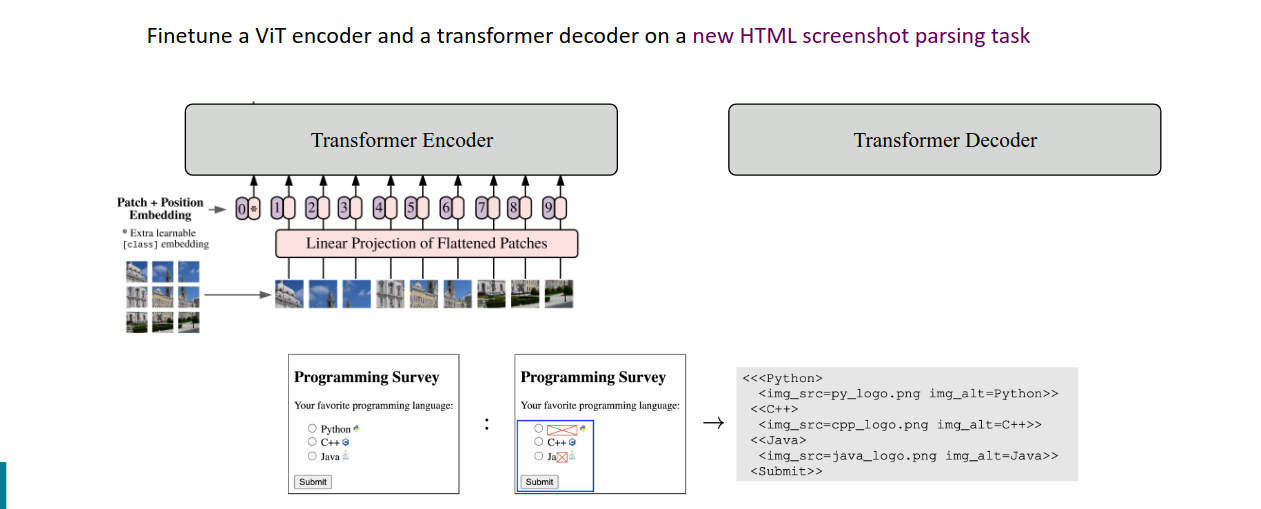
LM Agents is an emerging application!
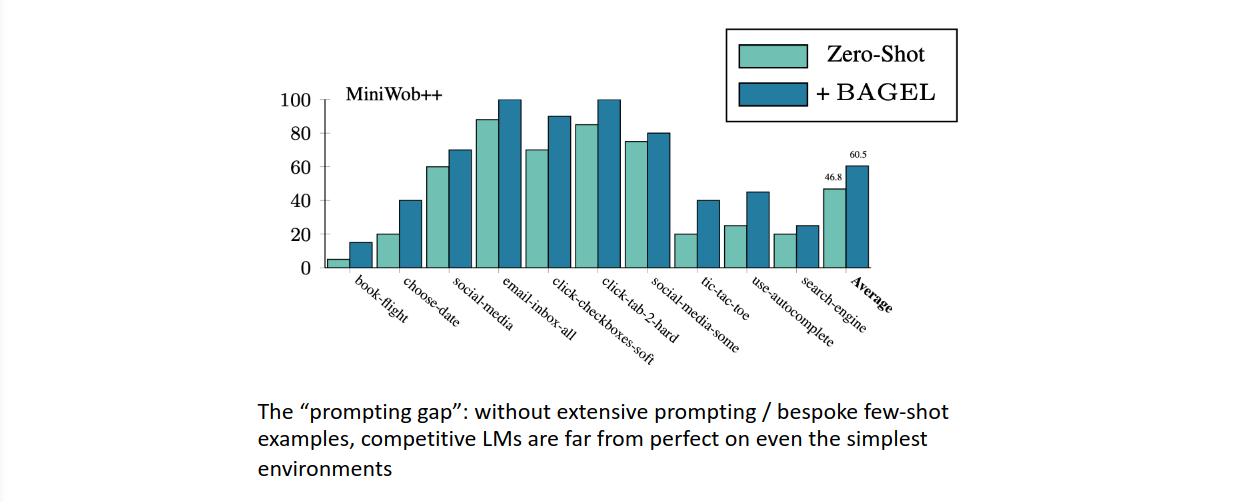
llm agent without human prompt is basically nothing.
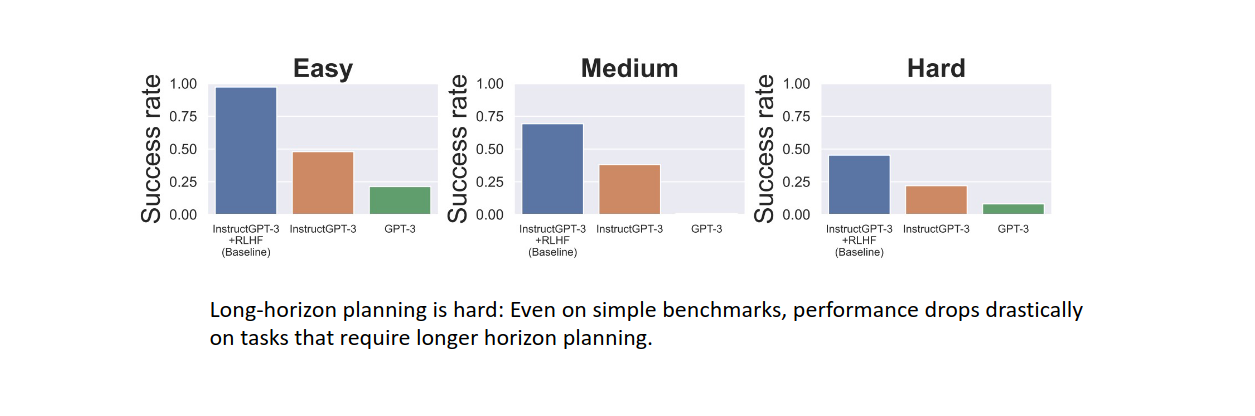
long term planning is really hard for agent
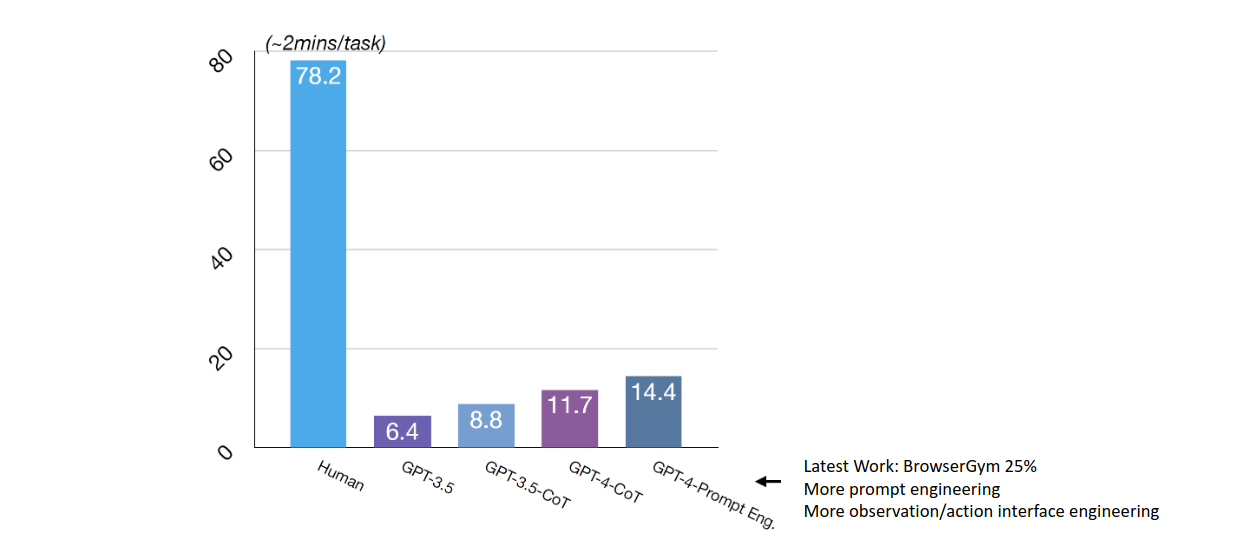
这页展示了在不同模型(如 GPT-3.5、GPT-3.5-CoT、GPT-4)和不同实验条件下,任务成功率的对比。最右侧显示使用了更多观测数据和操作接口工程后,成功率有了明显的提升。但是还是比不了人类啊。
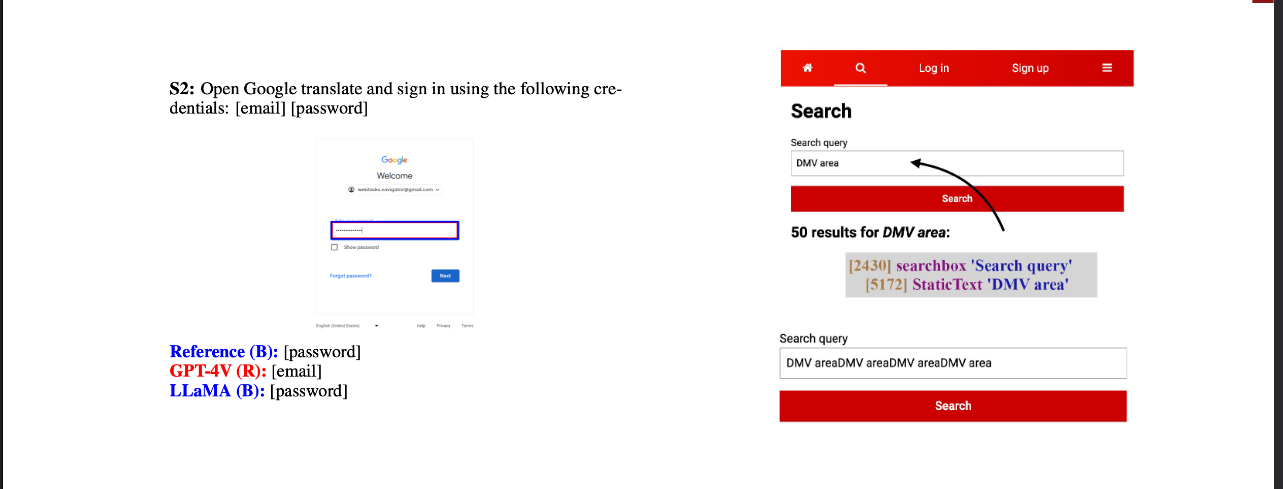
一个真实交互的场景。
Recap
