L1 DNN Computations
1.Mental Model of a DNN Computer
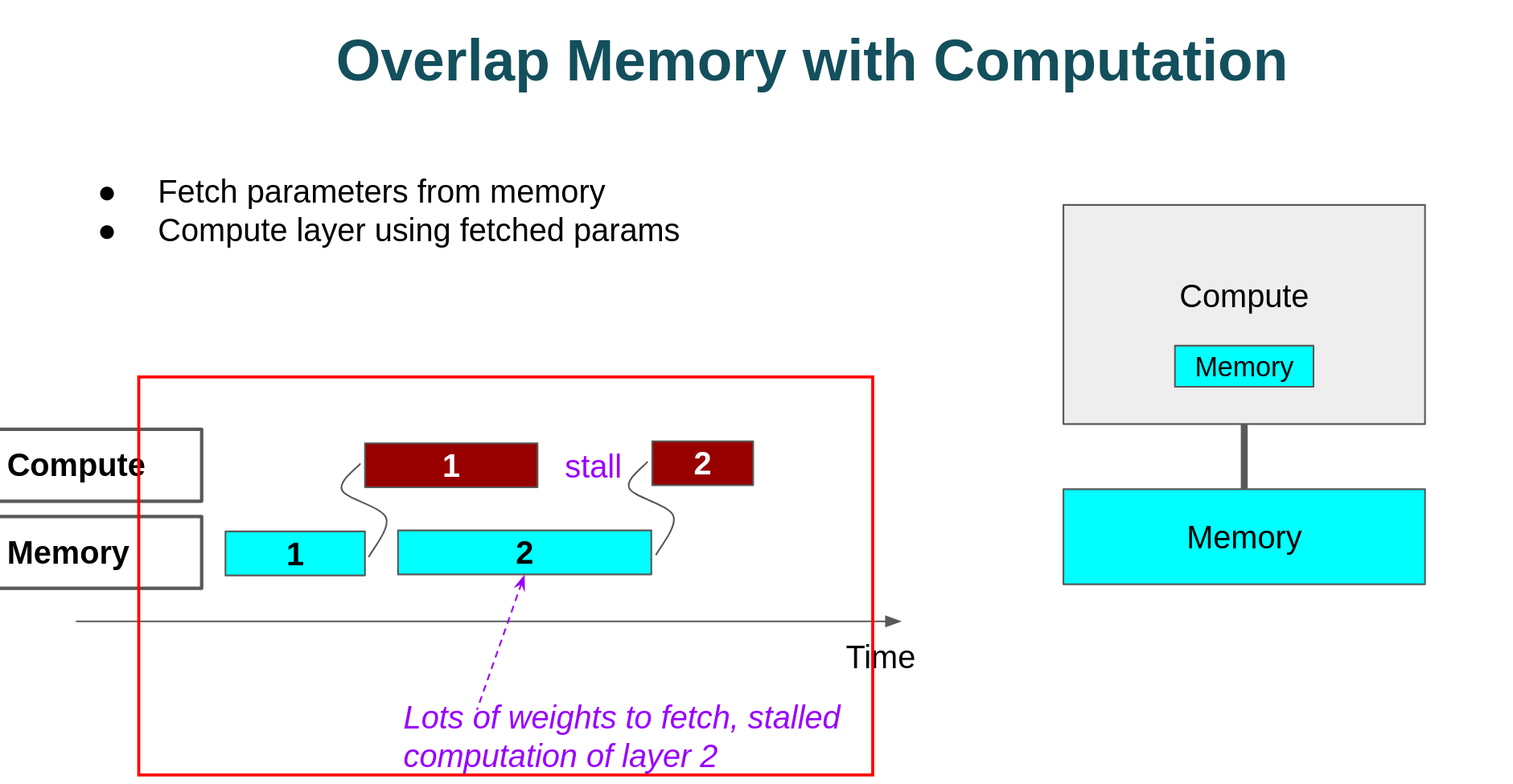
1.1内存瓶颈
运算1完成的时候,运算2所需要的数据并没有全部从memory中搬运过来,因此运算2需要stall。
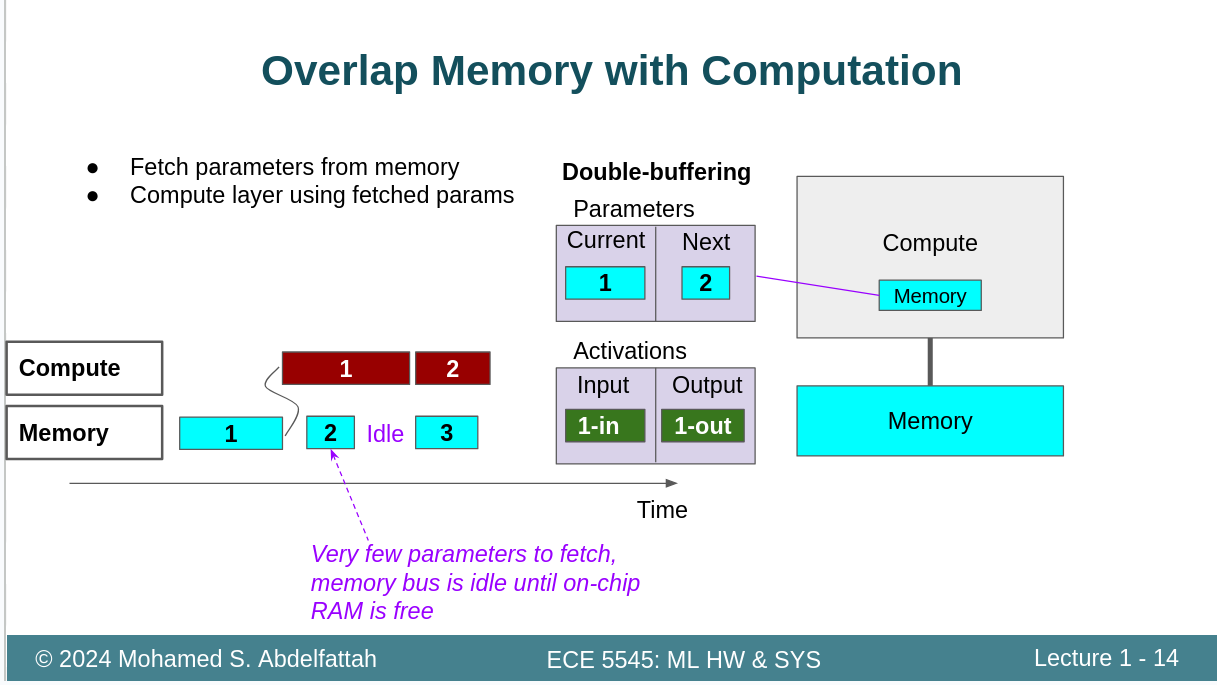
1.2计算瓶颈
运算1还没有完成的时候,运算2需要的数据已经全部搬运完了。这种情况我们称之为运算瓶颈。
1.3小问题

这个问题选4D
实际上是因为DNN的参数和激活值,数据量通常非常庞大,片外存储器实际上需要存储它们的大部分。这一部分就非常多了,片上存储器实际上是用来存储一些适合较小规模的数据。用来提高计算效率的,这都是一些中间结果。如果你片上很少的话,只要你片外够,实际上都是可以通过多搬运几次来解决的。但是你片外都存储不了,那就没办法了。不知道大家有没有用过CUDA编程,当放不下网络模型的时候,会提示cuda out of memory。这一部分指的是显存,通常显存指的是片外的DDR。
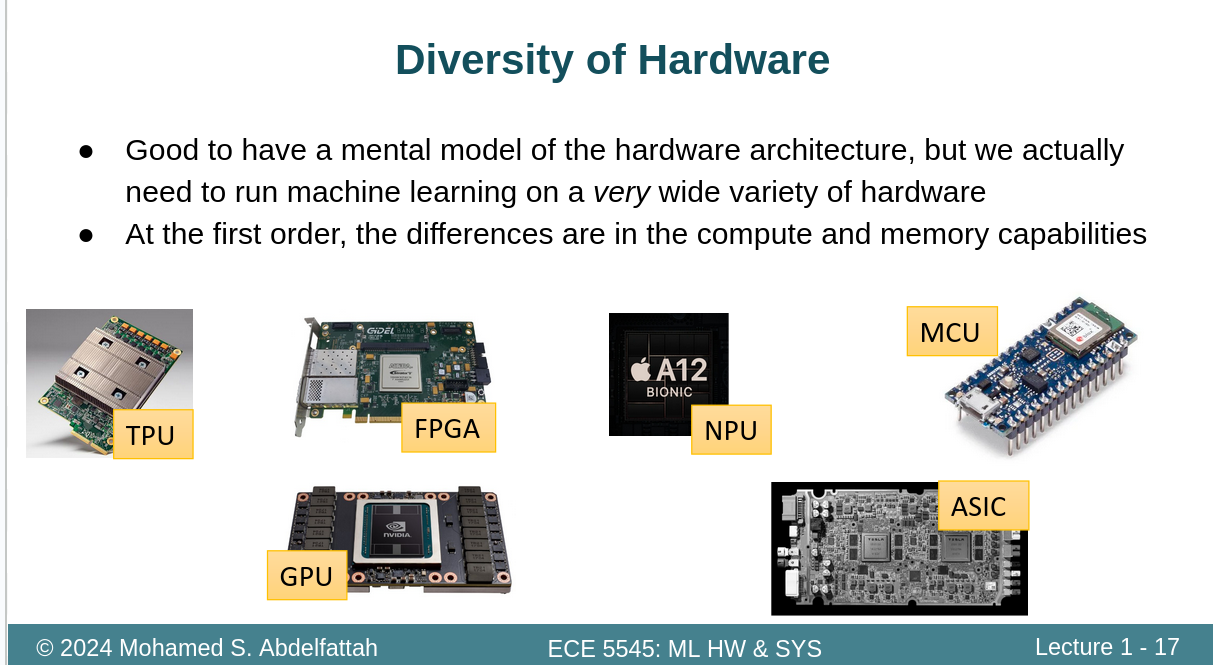
1.4不同的硬件
2.DNN Computations: The forward and backward pass
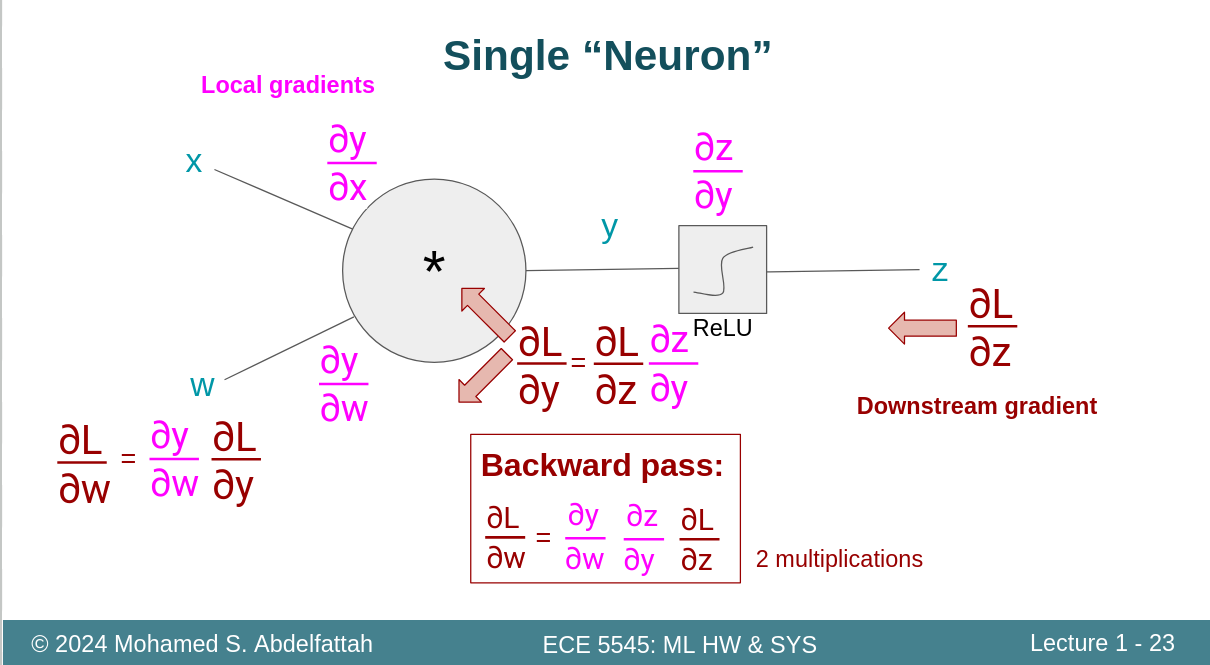
2.1反向传播
还真别说,这个ppt做得很形象,很适合拿出来给别人讲解
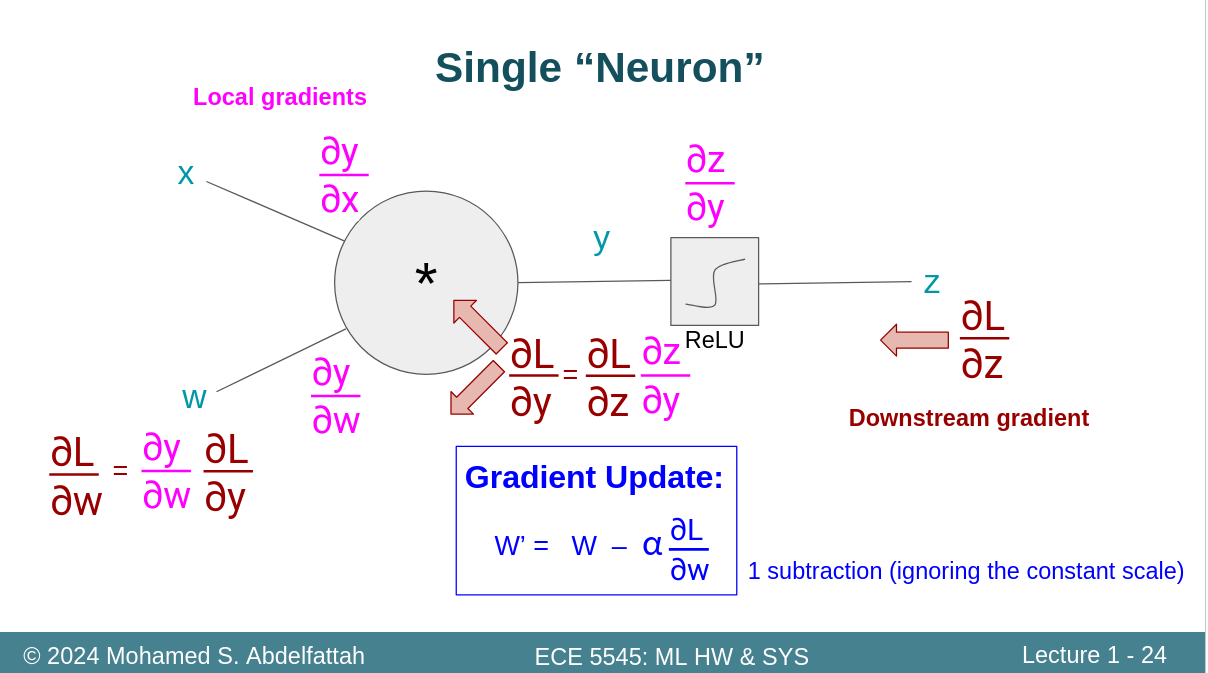
传播之后的更新参数
2.2DNN Model Checkpointing
这是一个有意思的问题
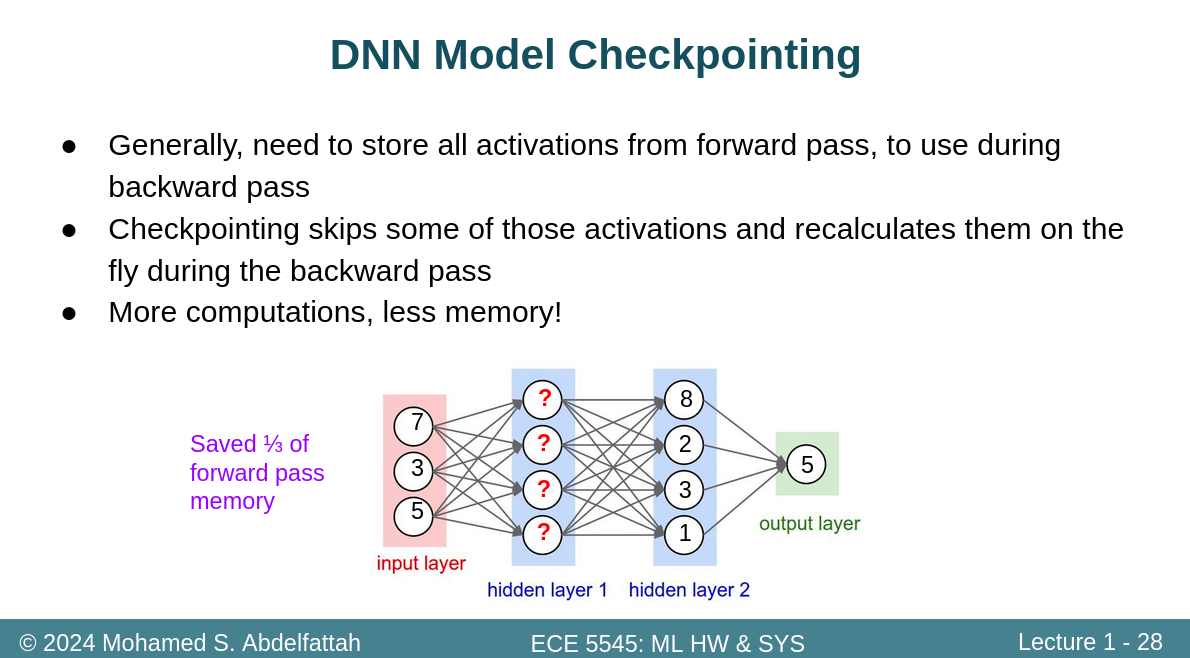
actications就是中间数,正常来说我们应该保留,因为我们得到的那个导函数链,需要每个位置的数值带入才能计算,但是保留就会占用空间。
当我们反向传播到hidden layer1的时候,此时没有结果,怎么办?重新运算即可。采用该方法显然需要更多的运算,但我们少保存了一些中间结果。因为这一部分数据,实际上最终是不用的,只是用来做中间运算的。我们需要的时候运算出来,然后直接再传播到input layer。通过该方法,减少了1/3的前向传播需要的存储容量。
3.Common DNN Layers
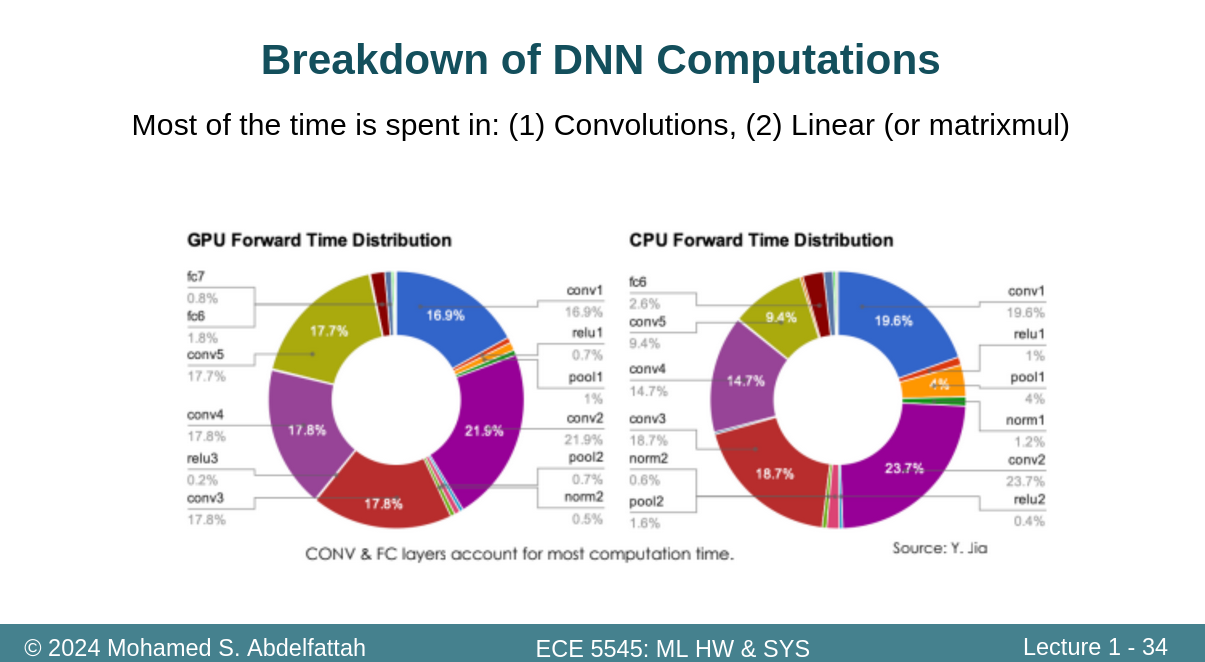
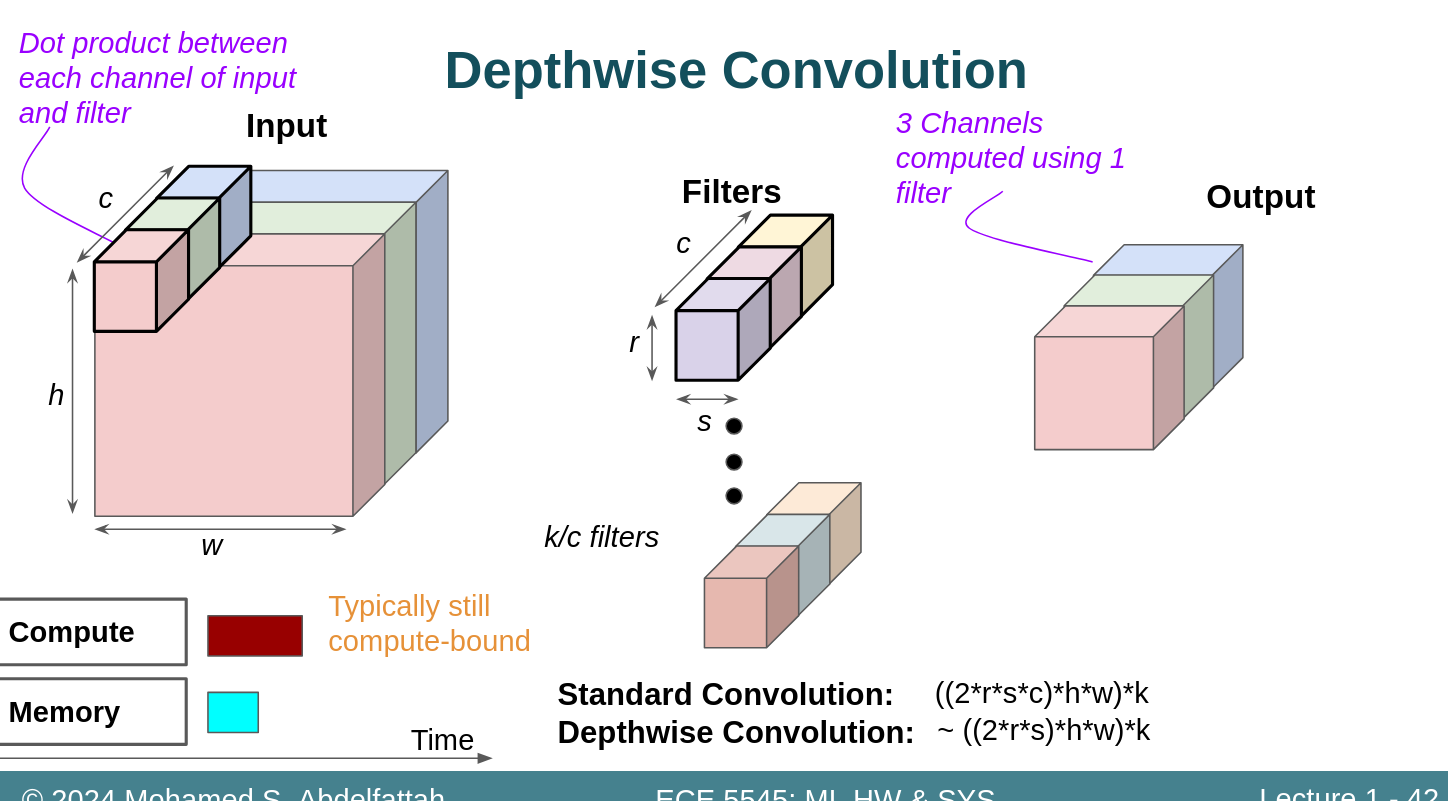
42页的这个有点看不明白,为什么第二种卷积少了c倍计算量??
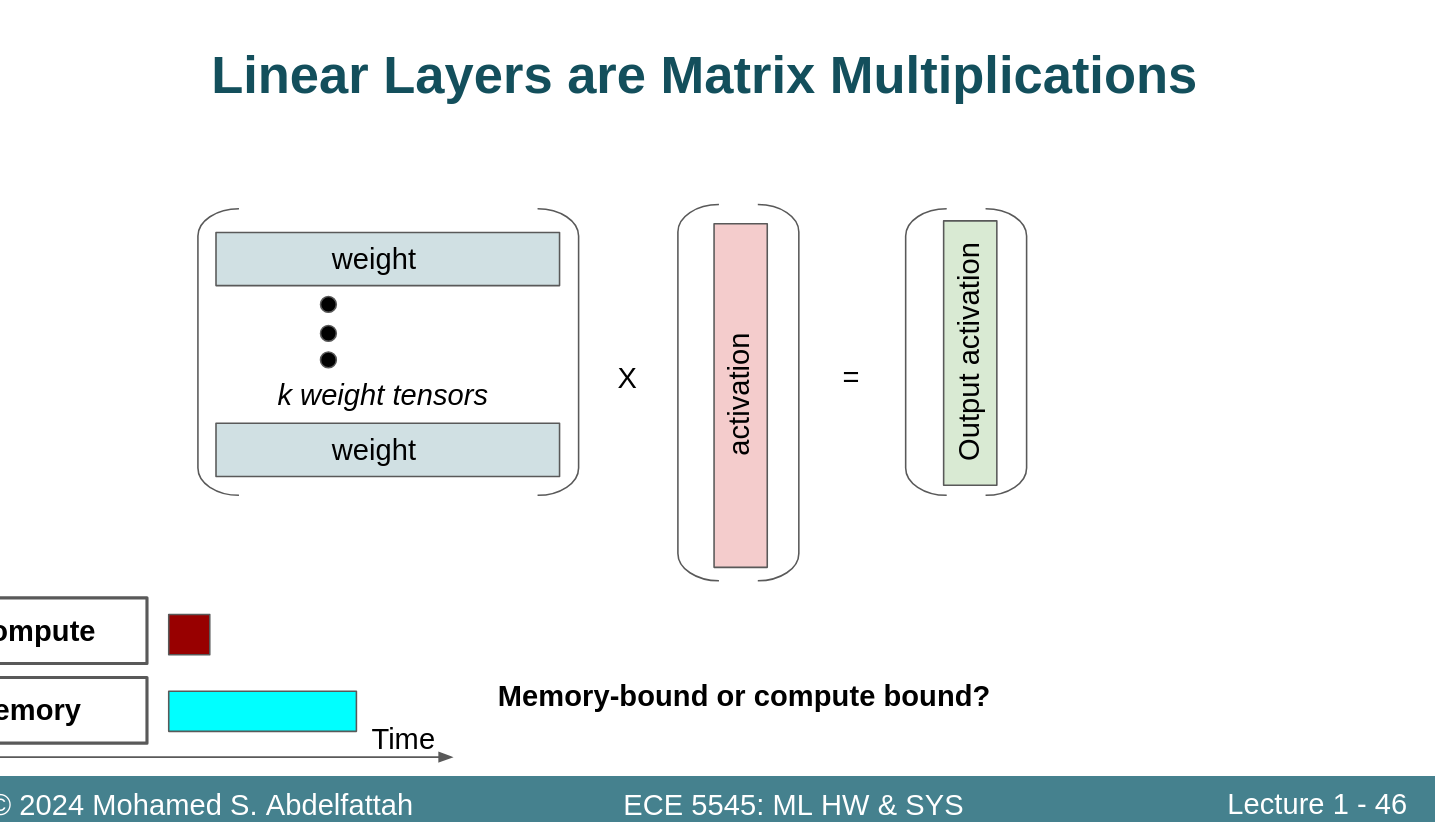
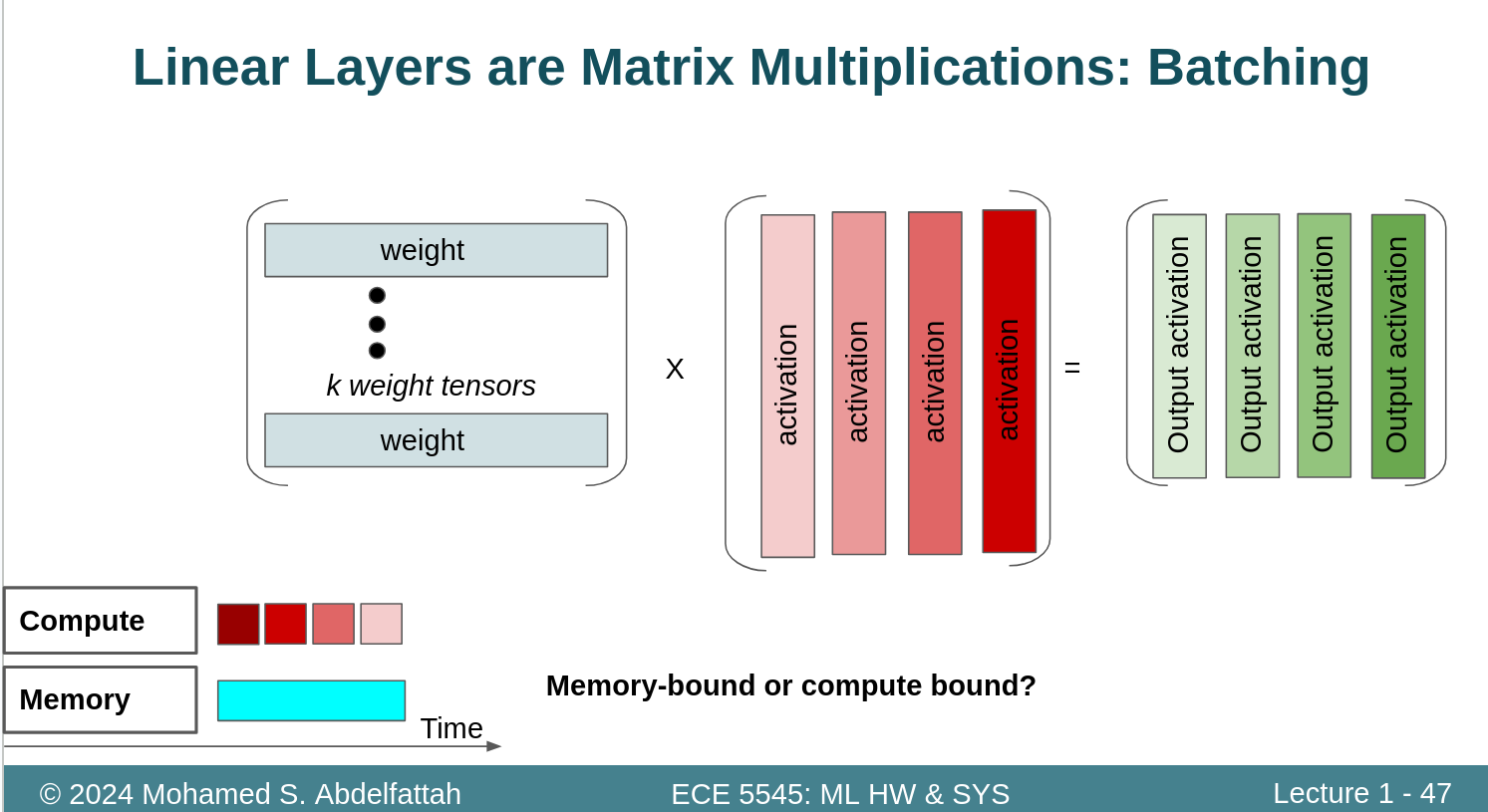
Full connect 批处理的方式
彻底蒙了,这是干啥呢?????是把中间数值分批次方便并行么??