GPT
时间轴
openai gpt-link
官方博客
介绍和idea
开篇说明了用了什么技术,并且取得了新的SOAT

博客提供了个表格,确实看出来在众多任务上GPT更好。
核心方法:先无监督大量训data,然后出来单独微调

这个工作是在这篇工作上进行的,他们在这篇工作发现无监督训练data很奏效。sentiment neuron

他们的idea很直白

结果当然是发现这个方法非常有效果。
相关工作

方法是一样的,但是第一个工作是在lstm的一个task文档分类上用的这种半监督方法。
第二个工作也是差不多思路,就是一个task的训练集先训练,训练之后微调然后在各种文档分类task都得到了好成绩。
第三个是个github项目似乎,openai也是强调了自己的gpt在task的泛化上更好,性能更优。
可见作者认为gpt的工作核心就是利用了半监督的方式应用在了transformerbased的模型上,而且任务泛化性很强。
最后作者发现效果特别好,而且在一些知识理解推理的能力提升特别好。认为可以按照这条路走下去。
Why unsupervised learning?
那个年代大多数的成功是因为有监督学习还有高质量标注的数据集,但是随着计算能力还有更多没标注的data,作者认为无监督学习能很好的消除有监督学习的劣势

各种无监督方法提升能力的案例
 后面解释了预训练模型就算不微调也能有task解决能力但是比较差,而且一个随机初始化的模型基本上没有解决问题的能力
后面解释了预训练模型就算不微调也能有task解决能力但是比较差,而且一个随机初始化的模型基本上没有解决问题的能力
Drawbacks
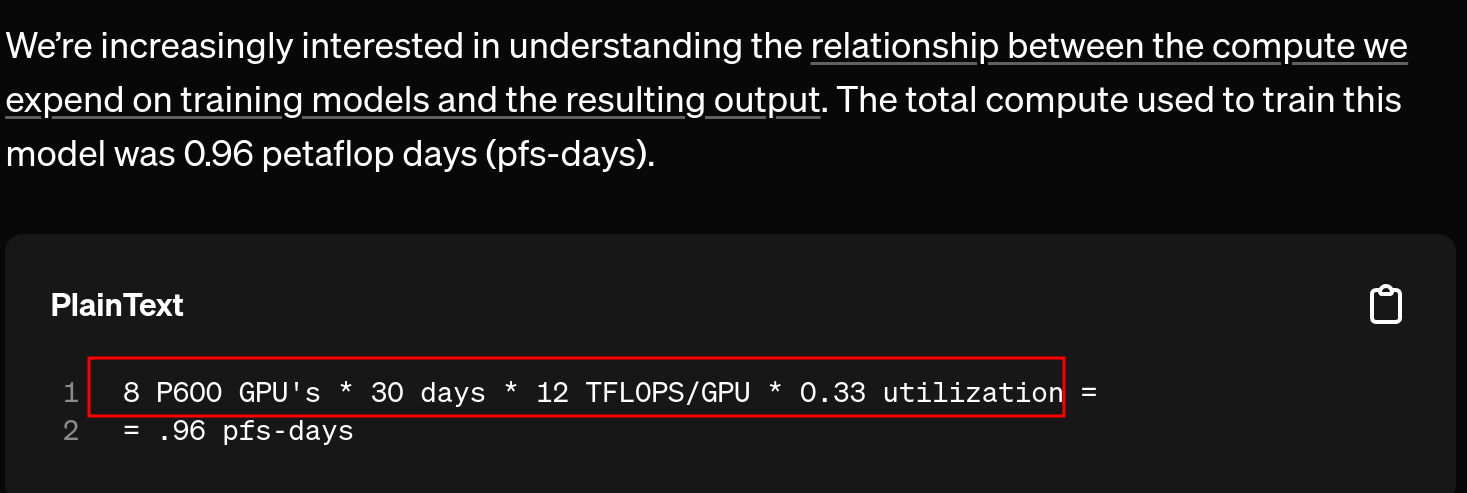
Compute Requirements
他们用了8个gpu训练了一个月(当时的大模型),作者认为这种模型训练非常昂贵,他们开放出来参数供大家观看。
The limits and bias of learning about the world through text
Recent work(opens in a new window) has shown that certain kinds of information are difficult to learn via just text and other work(opens in a new window) has shown that models learn and exploit biases in data distributions
文本不能完全反应现实世界,而且文本中能学习到很多偏见
Still brittle generalization
泛用性还是不是特别好,而且作者无法解释一些模型的反直觉行为。
Future
Scaling the approach
scaling law的前身?作者前瞻地提出了加大算力和数据的方式。

Improved fine-tuning
这个里面有更好的微调技术,作者还没用(那个年代)

Better understanding of why generative pre-training helps
一些可解释性的方向,到底是什么让gpt奏效?
什么能力的提升会让gpt更强?

appendix
介绍了数据集还有算力,看看那个年代的算力
论文
中文版博客
前面还是差不多的内容
看看具体细节
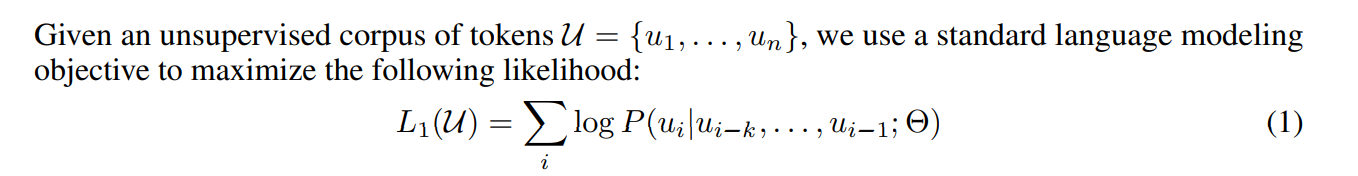

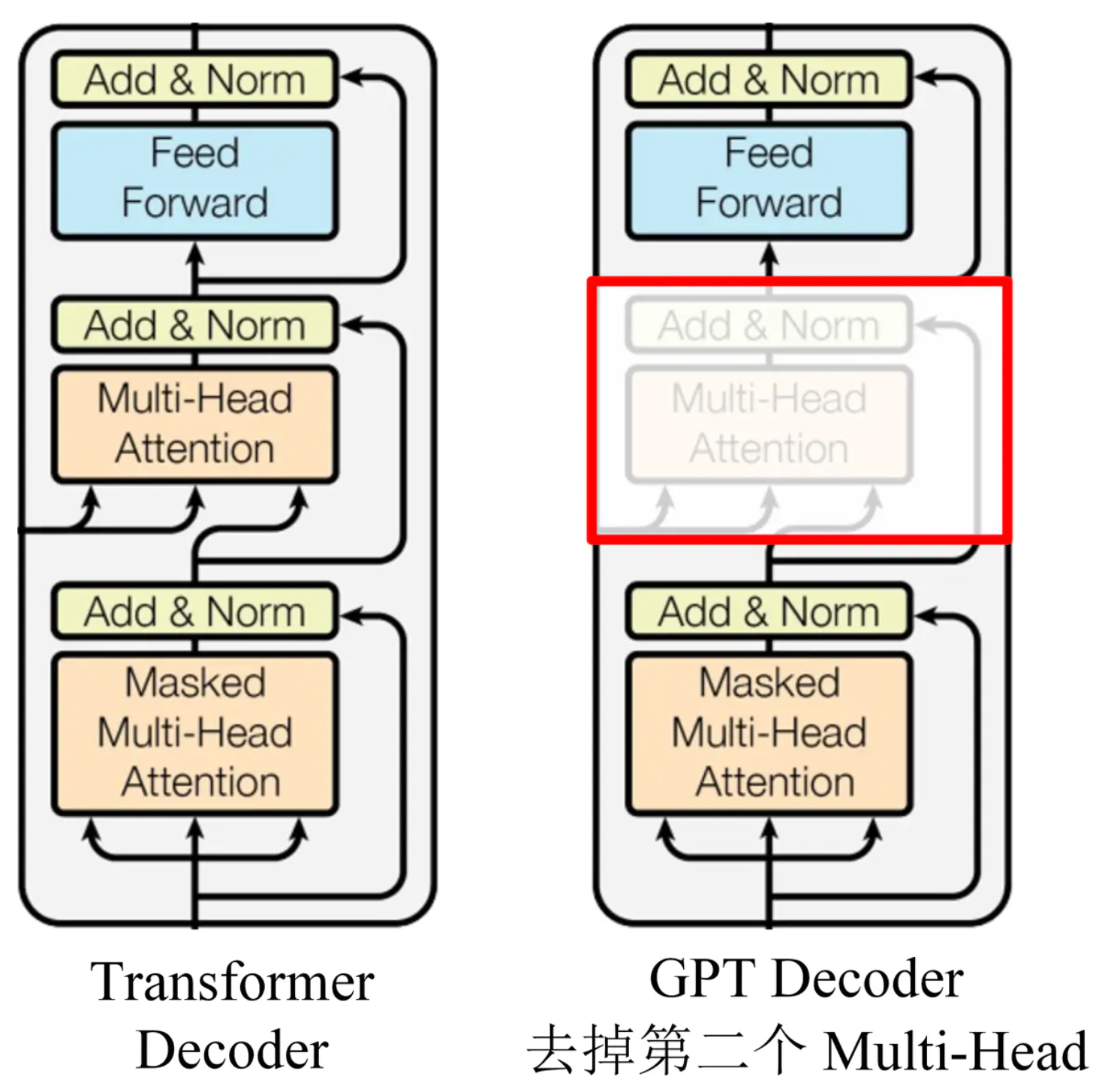
GPT中语言模型使用多层的Transformer decoder,是transformer的变种。该模型在上下文token上使用多头自注意力操作,接一个逐位置的前馈层来生成目标字符的分布输出(比原本少了一个多头自注意力):
分析
层数的迁移学习影响 从预训练到微调迁移学习过程中,如下表在MultiNLI和RACE上的性能随着层数的变化而变化。作者观察标准结果,在MultiNLI上转移embedding能提升结果,每一层Transformer层能带来9%额外的提升。这表明预训练模型中的每一层都包含了解决目标问题有用的功能。
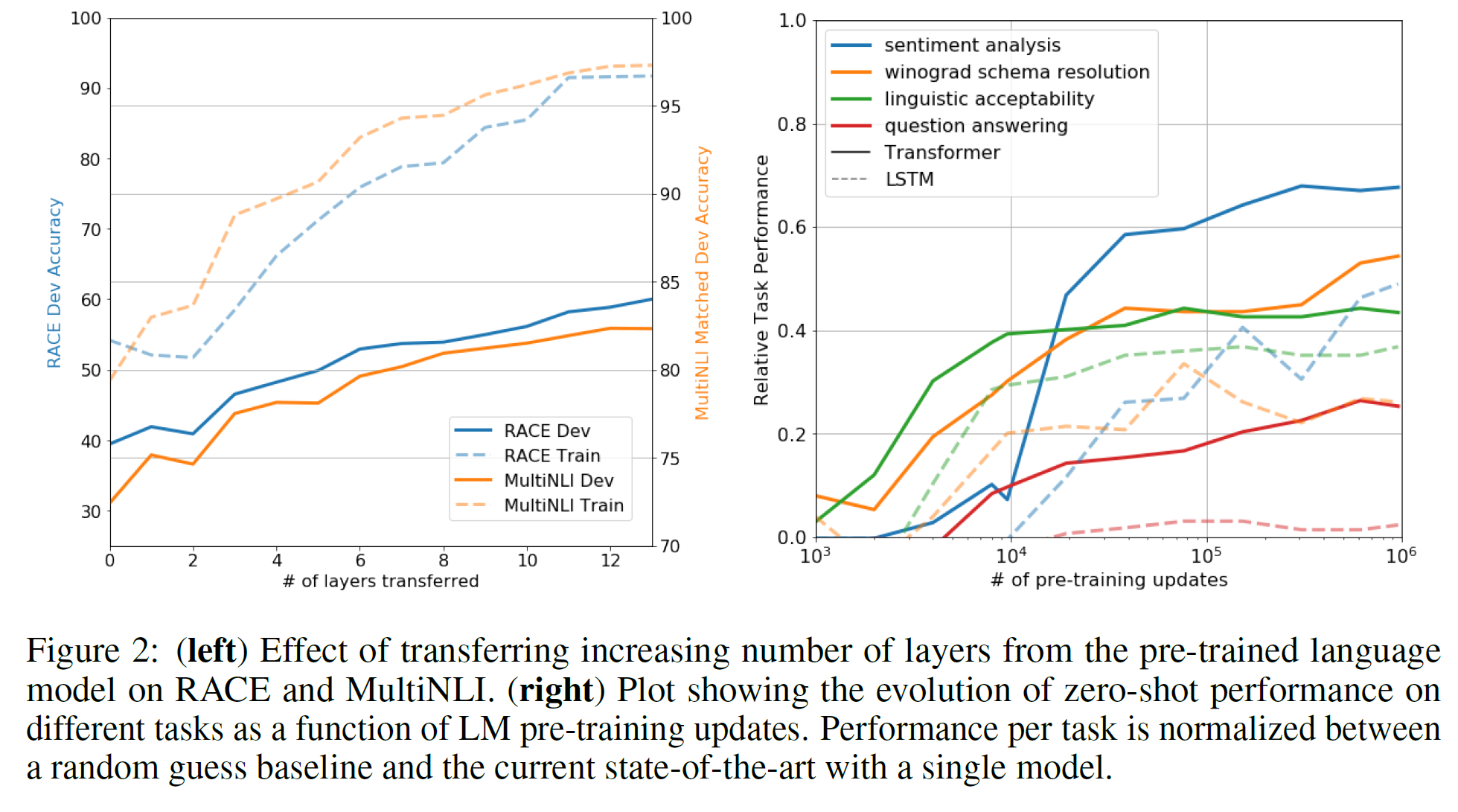
零样本表现 最好要弄清楚为什么预训练模型会有效?一种假设是,与LSTMs相比,潜在生成式模型(underlying generative model)在应用到很多任务时可以提高语言建模的能力并且transformer更具结构化的注意力记忆(attentional memory)有助于迁移。在零样本上,LSTM表现高方差,表明在迁移中,Transformer架构导入偏差是有帮助的。
总结
方法清晰,效果很好,但是实现细节上我还是没完全理解,这篇文章里的数学公式描述应该是有行业内的一些普遍共识的,而且我没看出来gpt怎么描述只是在decoder上面去掉multihead的。