self-attention简介
Input
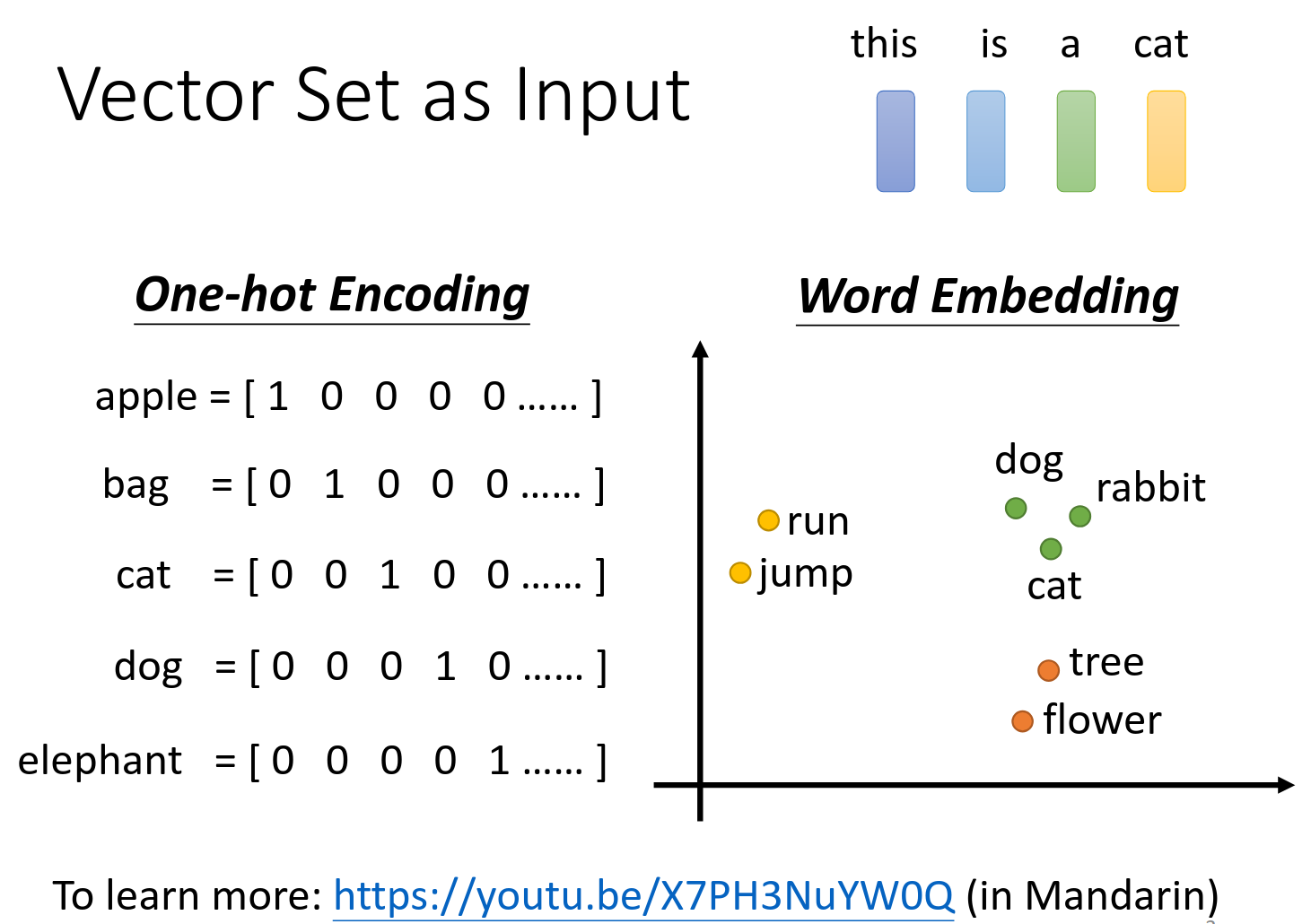
word embedding不是今天的重点
输入可以是很多东西,都可以作为一组向量输入。
What is output?
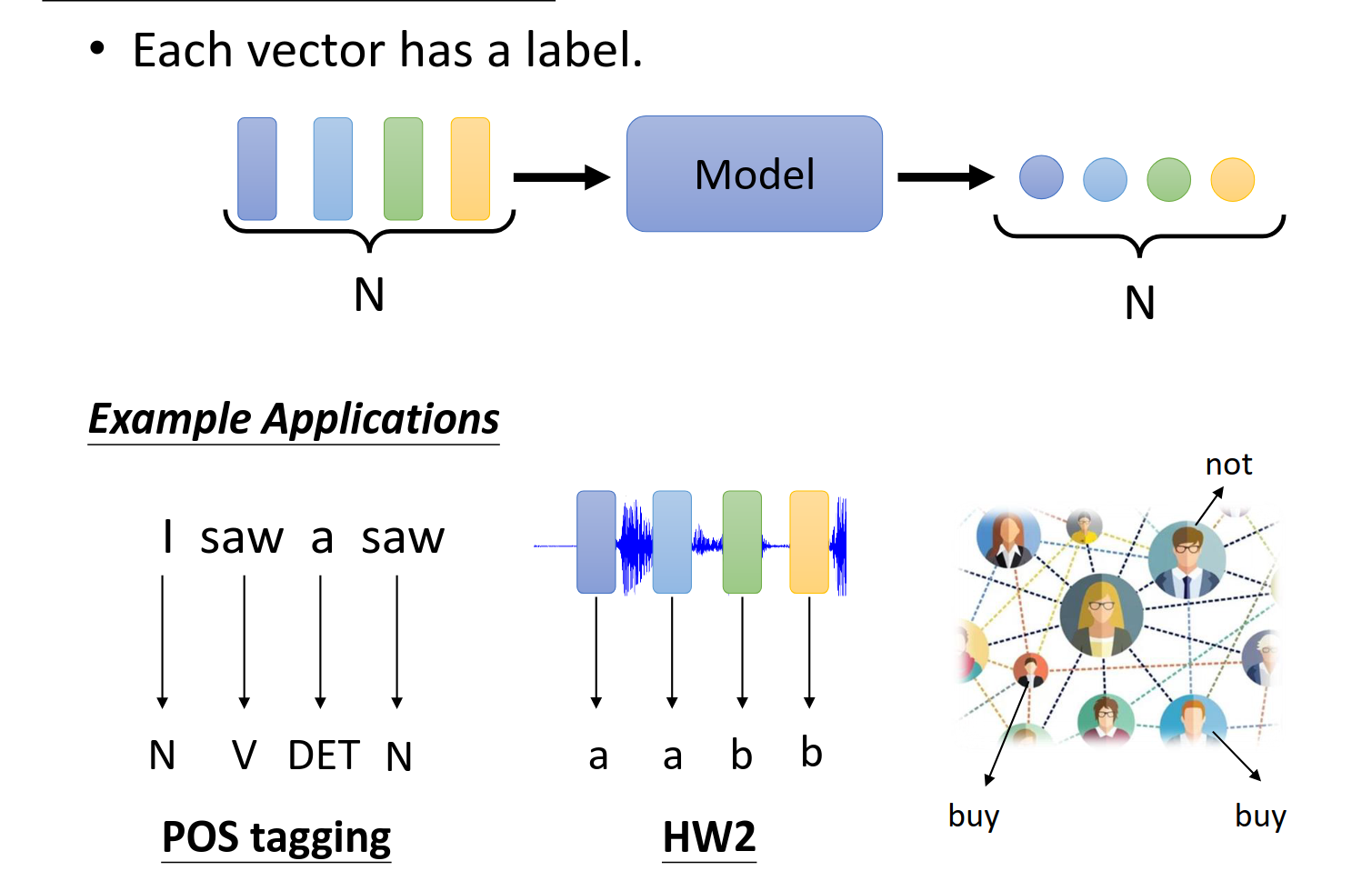
每一个输入的向量都有一个对应的输出,一一对应,这种输入输出可以有下面三种应用场景
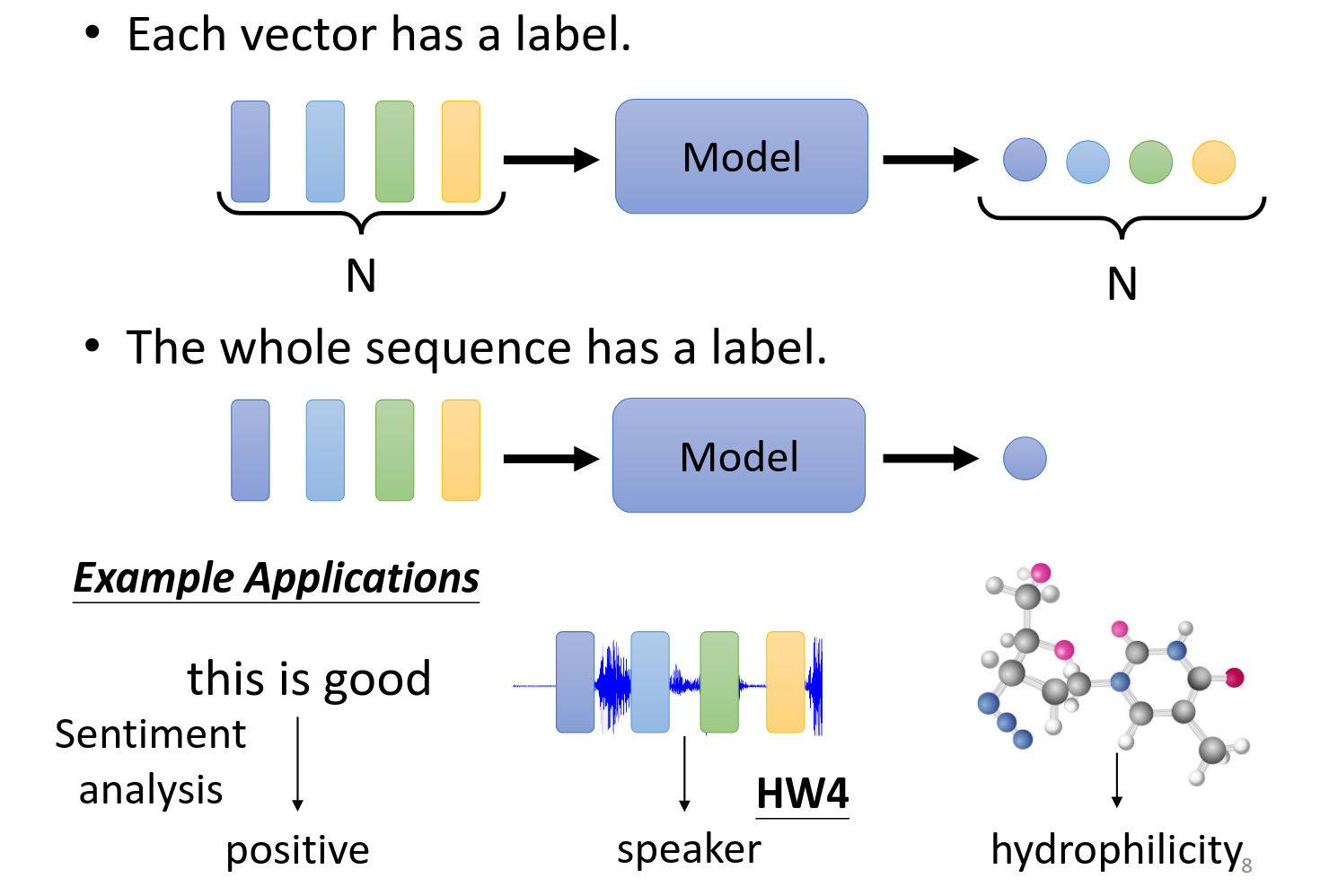
第二种场景就是整个片段对应出来一个标签,例如判断句子情感,判断一段话是谁说的,判断分子的属性等等。
第三种是输入和输出不是一一对应的,同时也不是多个对一个的,输出多少要机器自己来判断。
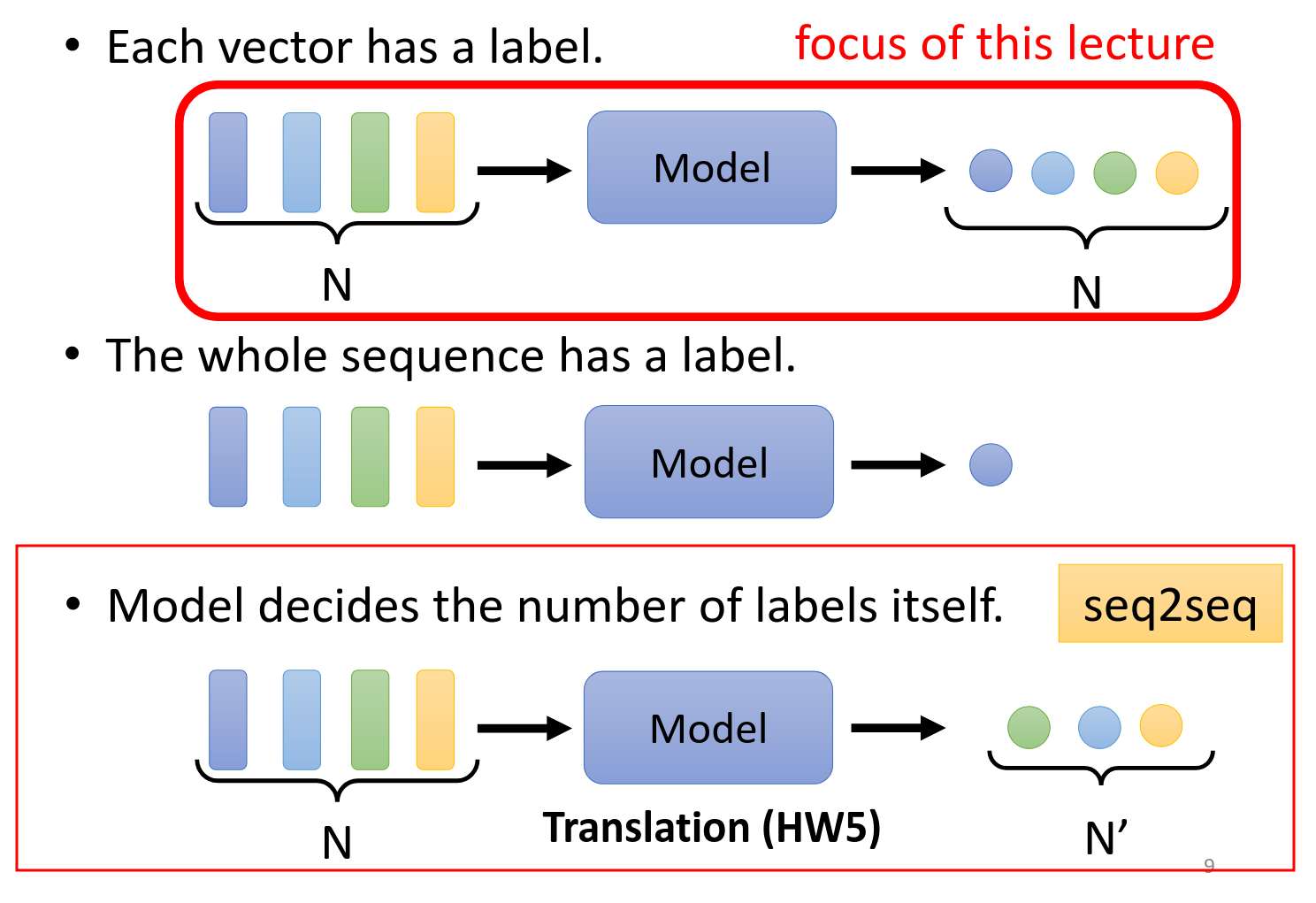
Sequence Labeling
question
下面是一个词性判断task,如果只用全连接网络,那么相同的输出应该是相同的输出,就是两个saw无法分辨他们之间的区别。
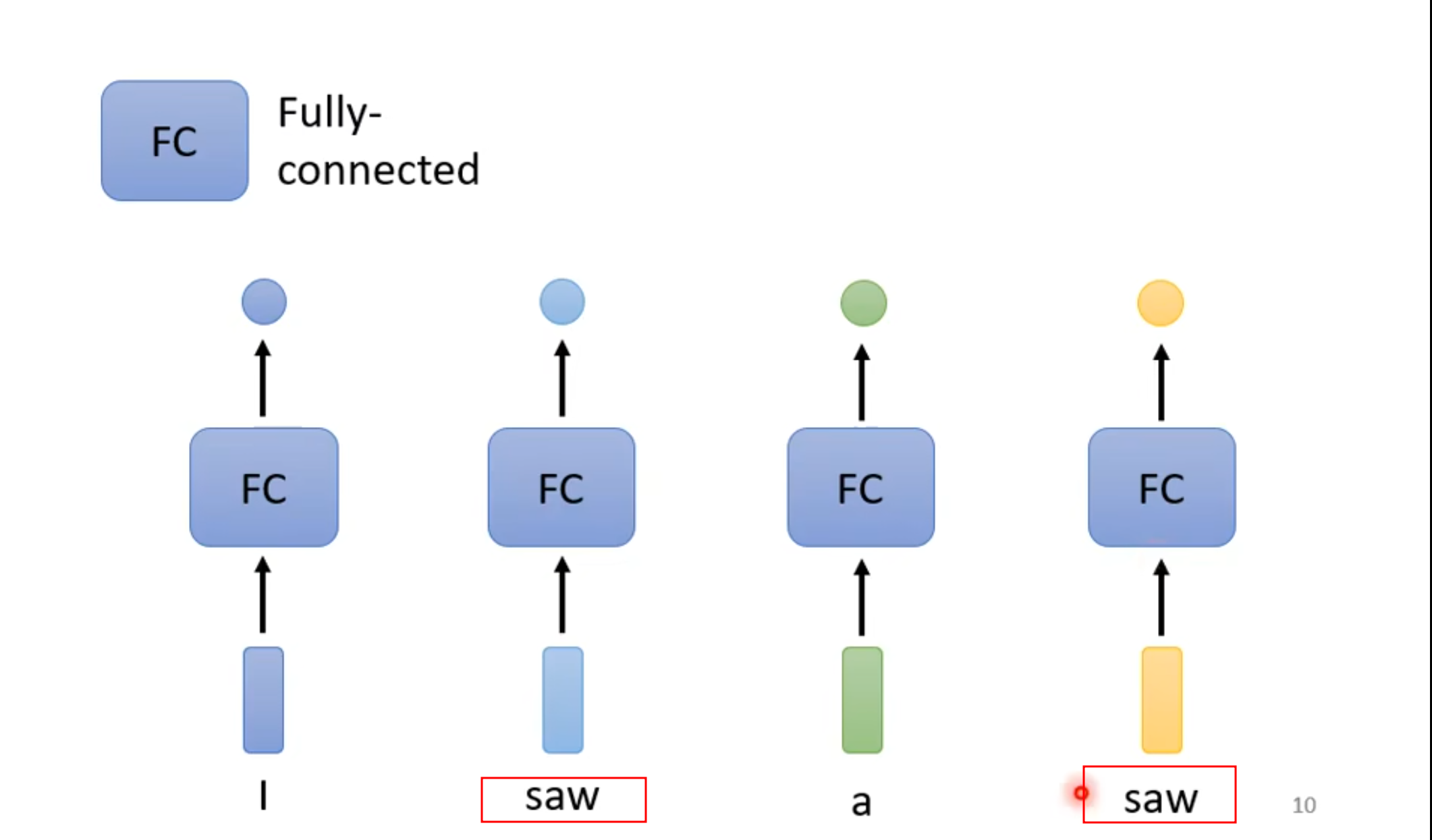
answer
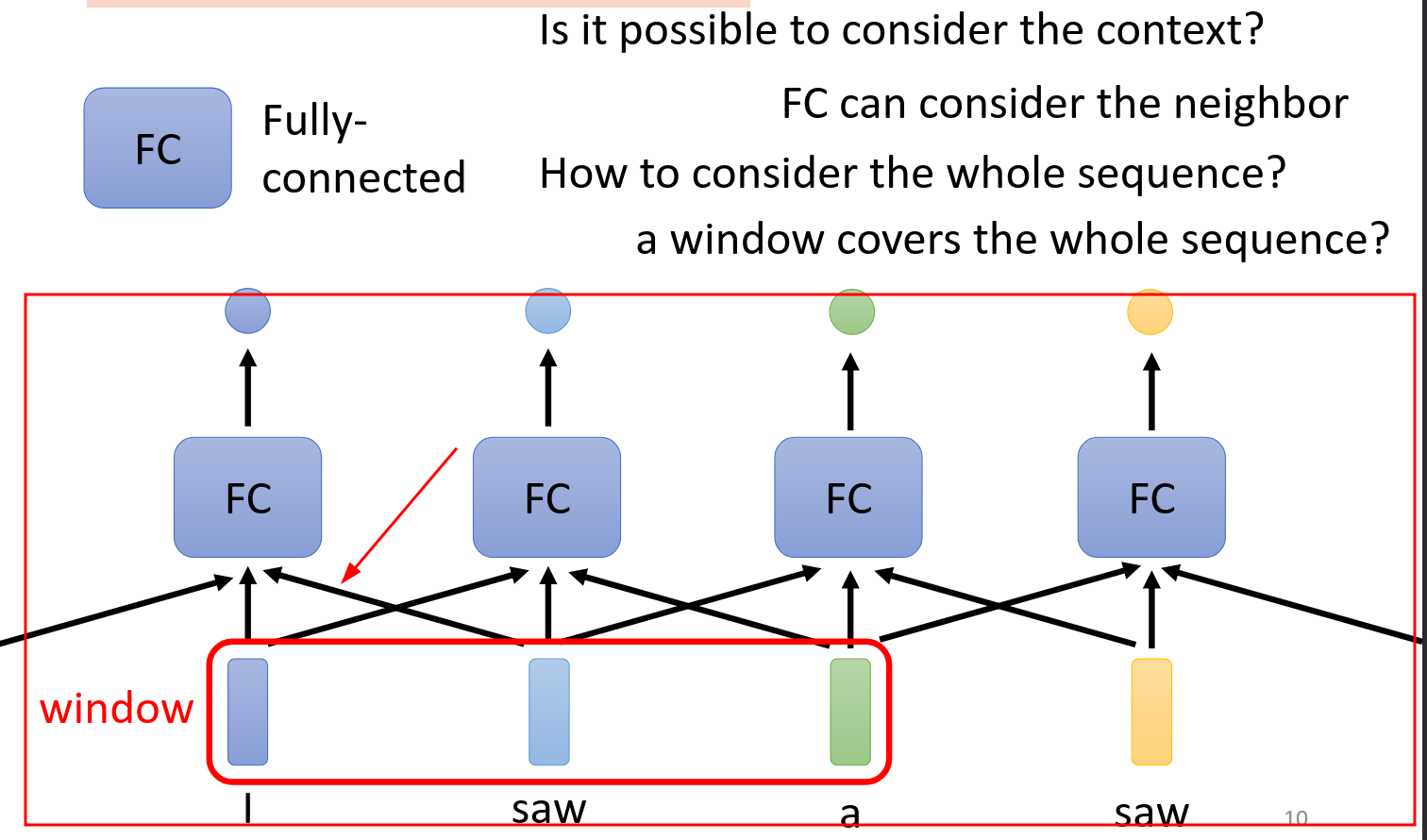
通过考虑上下文的信息,我们把前后文的几个向量串联起来,然后输入到全连接网络,于是我们采取下面的解决方式,考虑的上下文范围就是window.但是他仍有问题
1.比如说task必须考虑整个sequence才能,那么这个时候window开多大呢?
2.就算统计好了,全连接网络的计算也是非常大的。
这个方案我们要舍弃。
self-attention
我们采用这个方法之后,self-attention的输出带有黑框,他们是考虑整个句子考虑之后输出的内容。
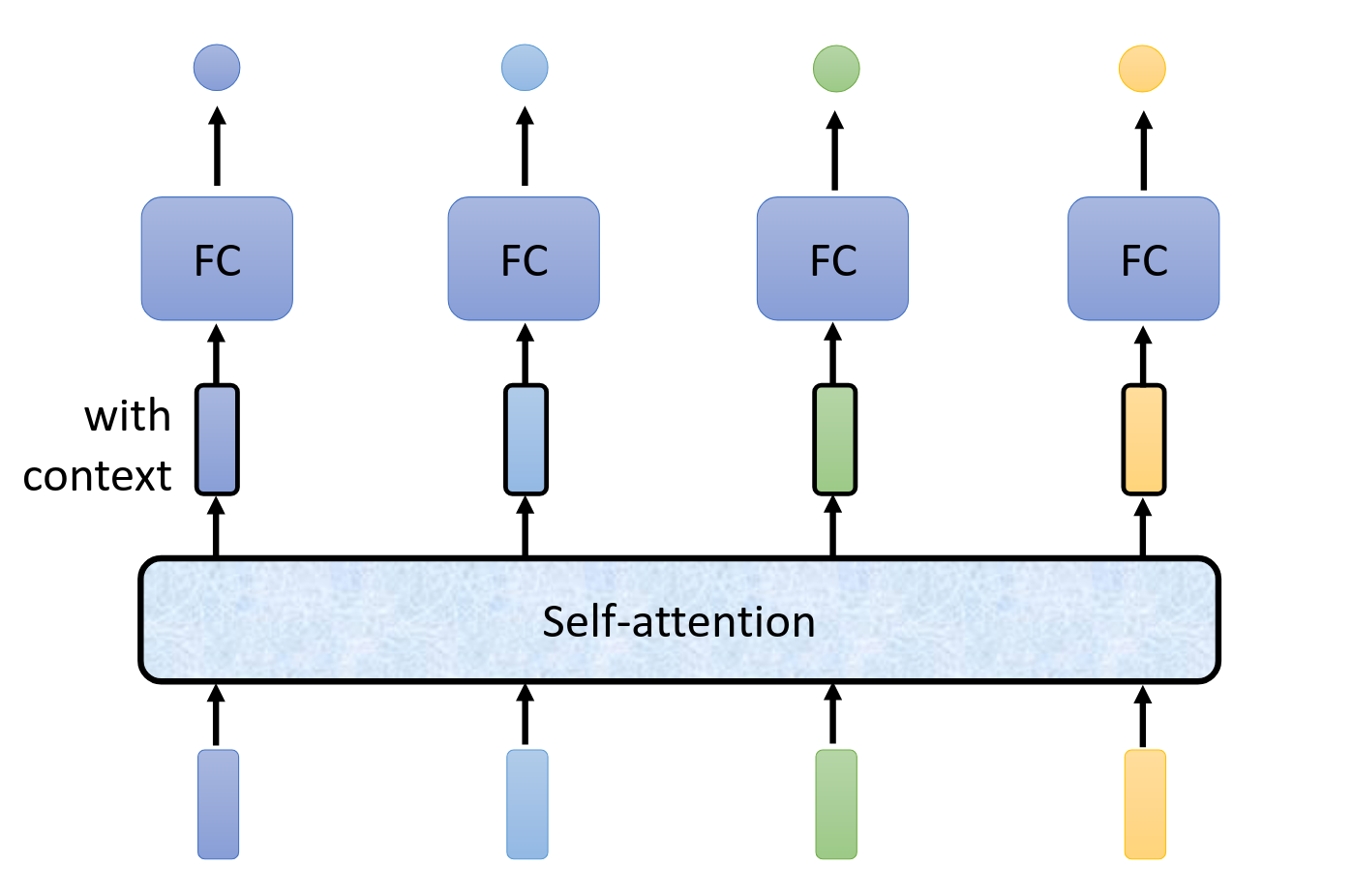
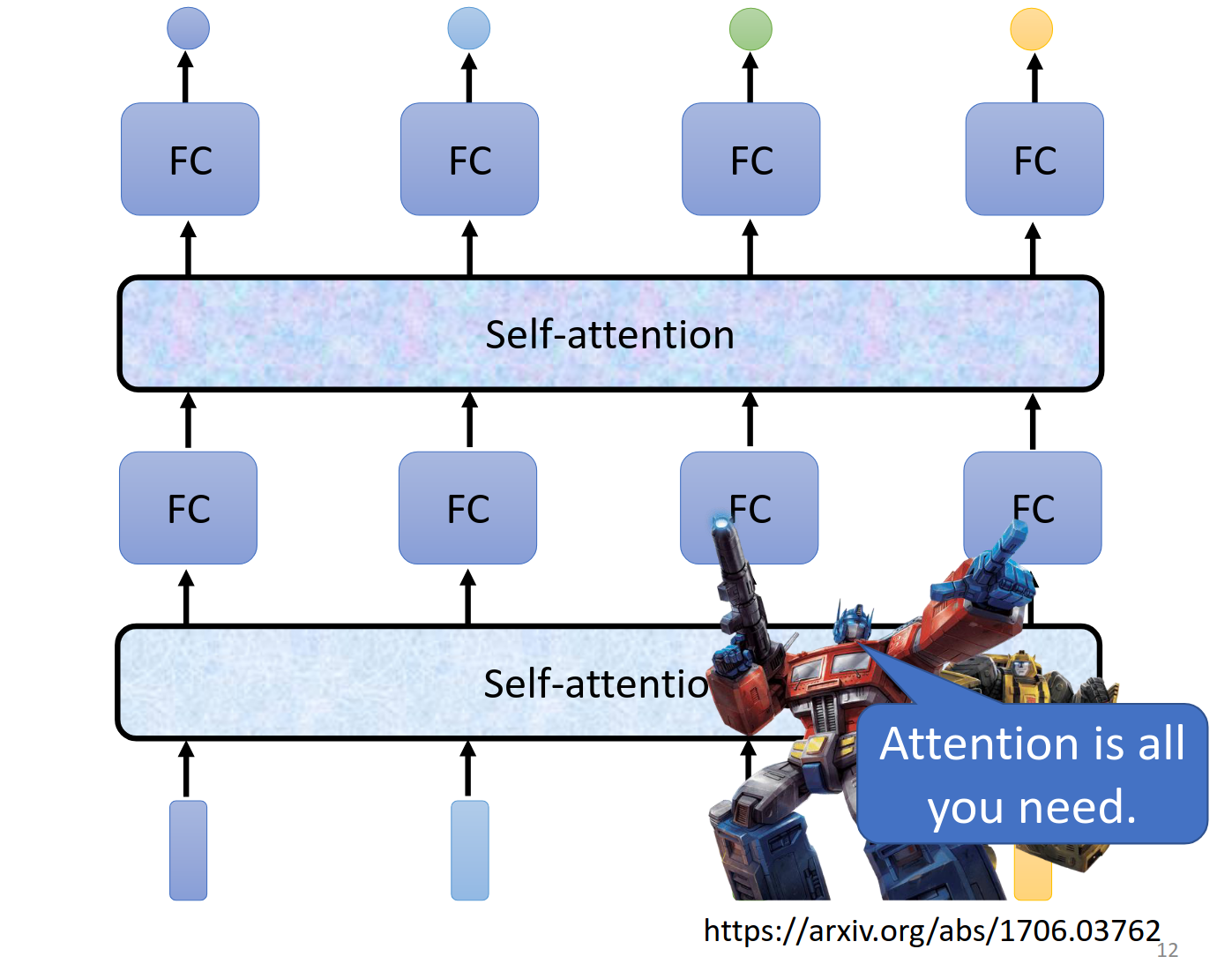
接下来我们采用FC与self-attention相互交替的办法来实现了transformer
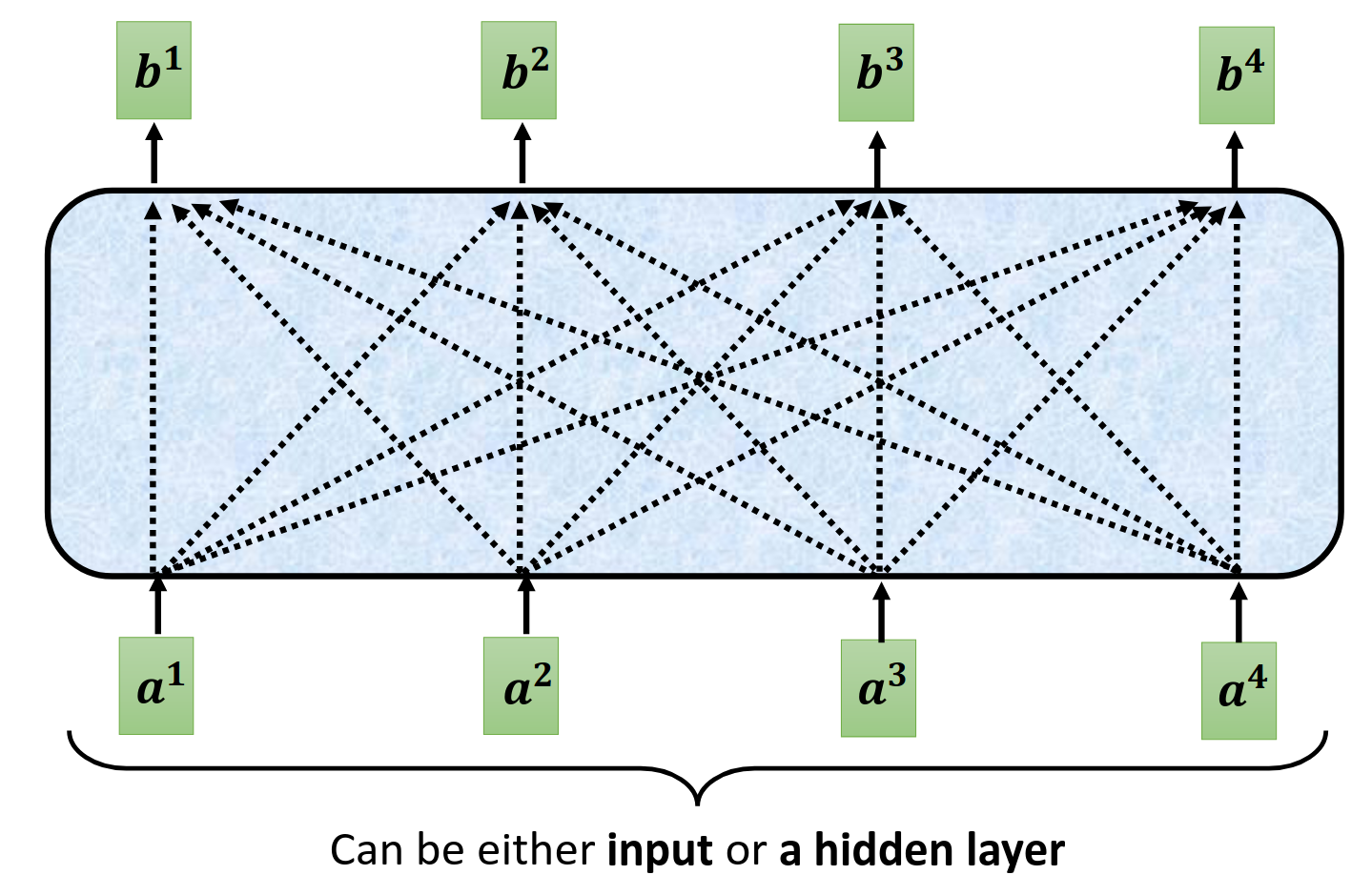
How Self-attention works?
input是一串向量,每一个输出全部是考虑了所有的输入才产生的。
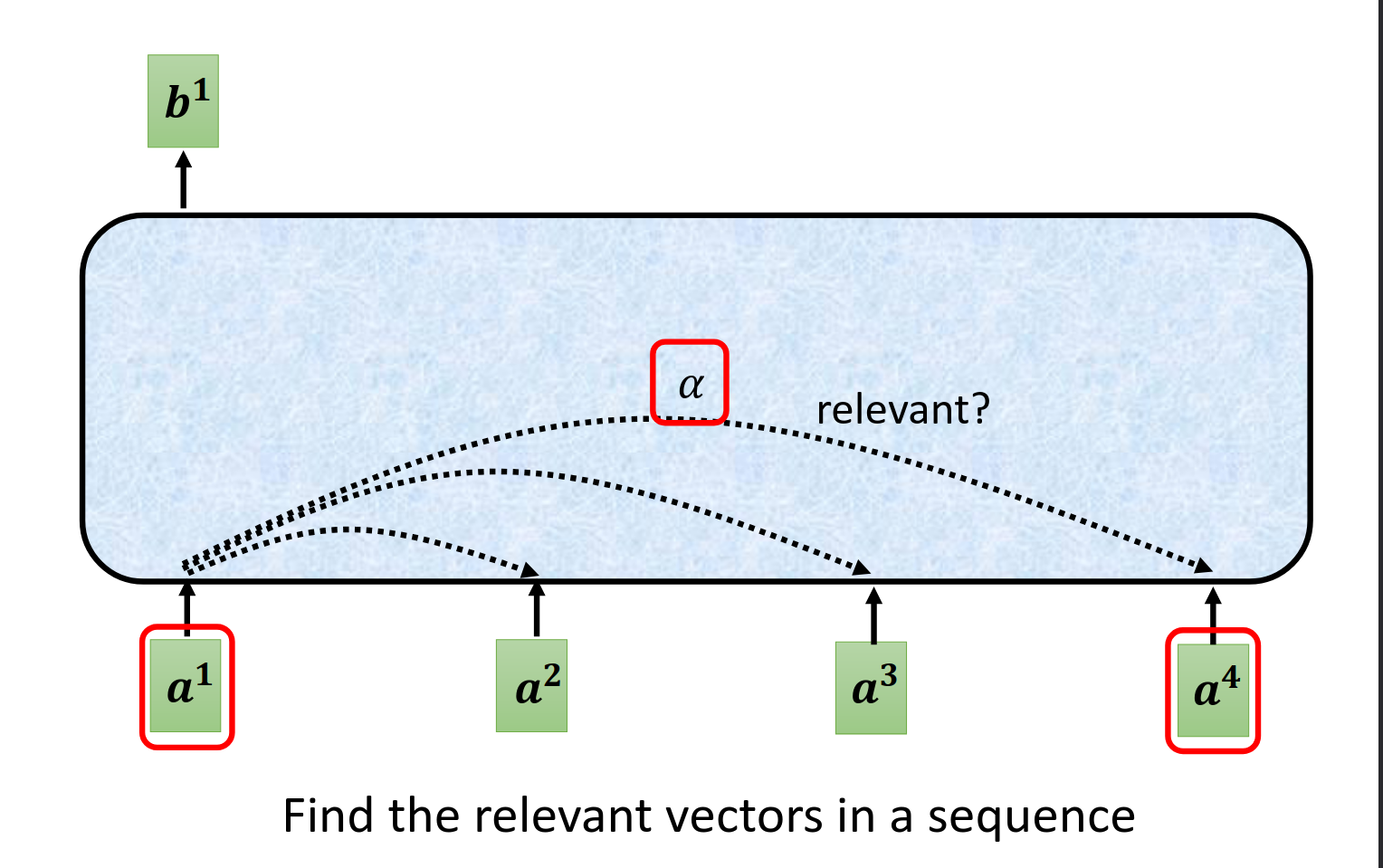
begin
判断哪些向量是有关系的,关联程度用
两种计算方法我们用左边的方法。
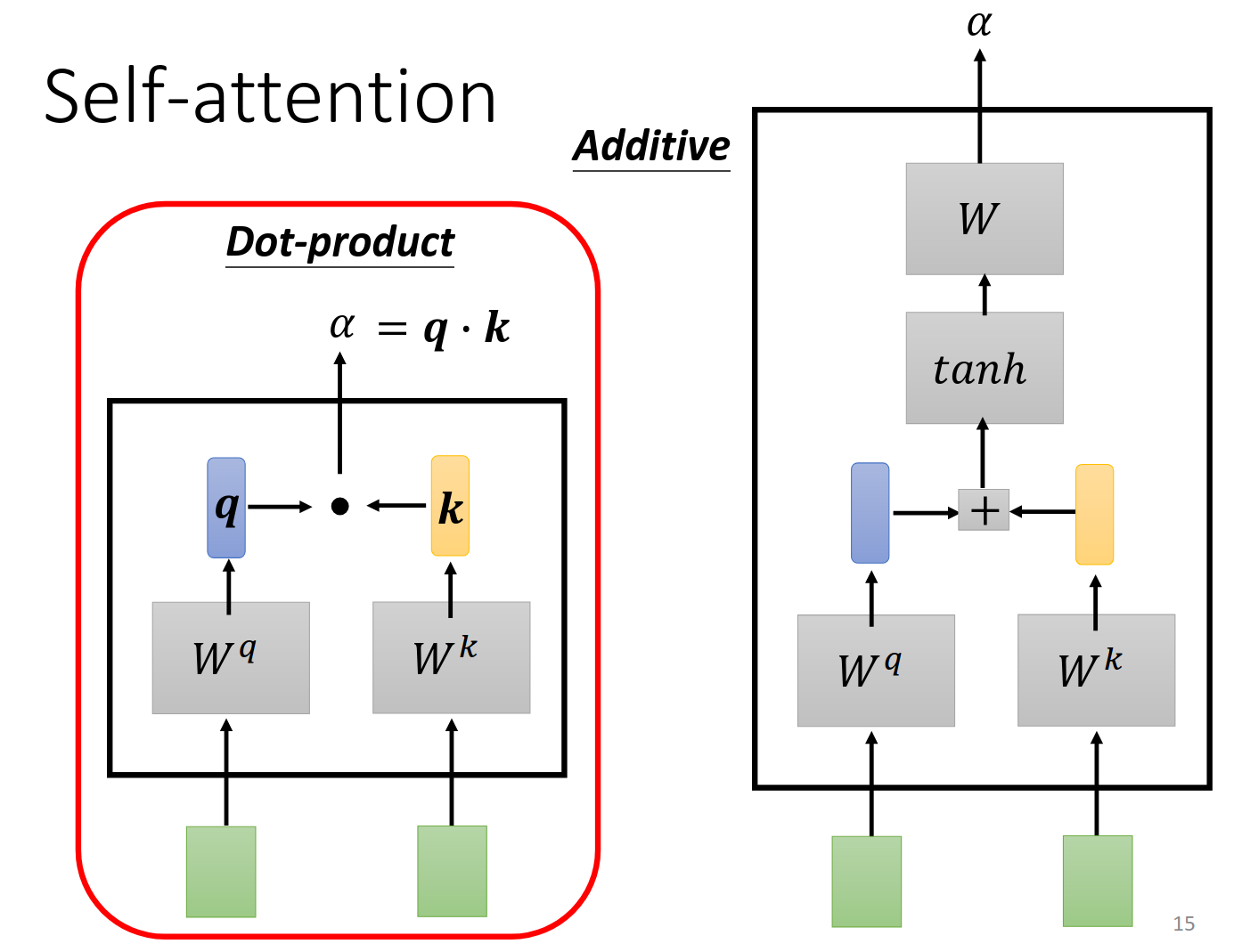
详细的描述,softmax层没有理由,更换成其他似乎也可以
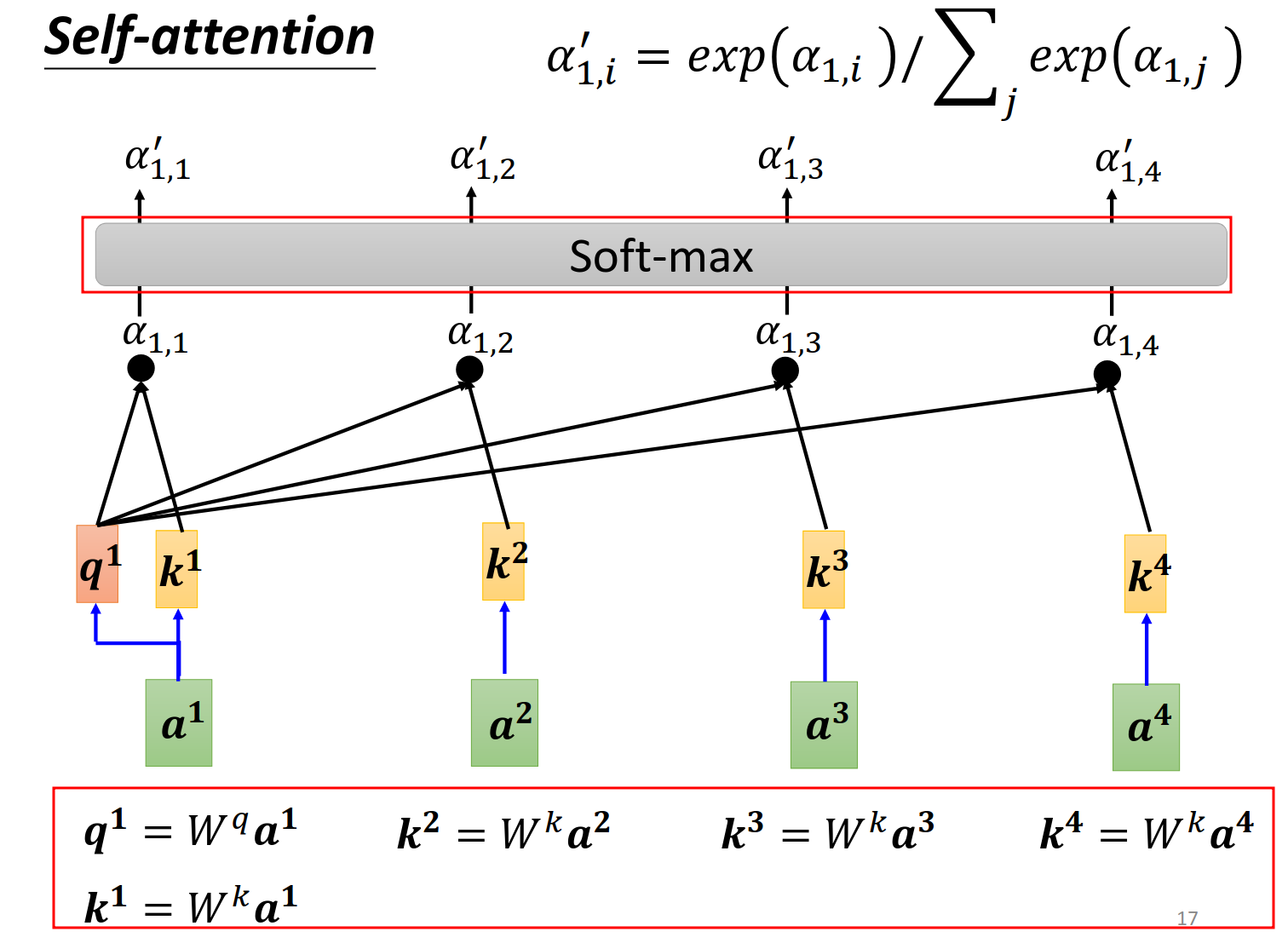
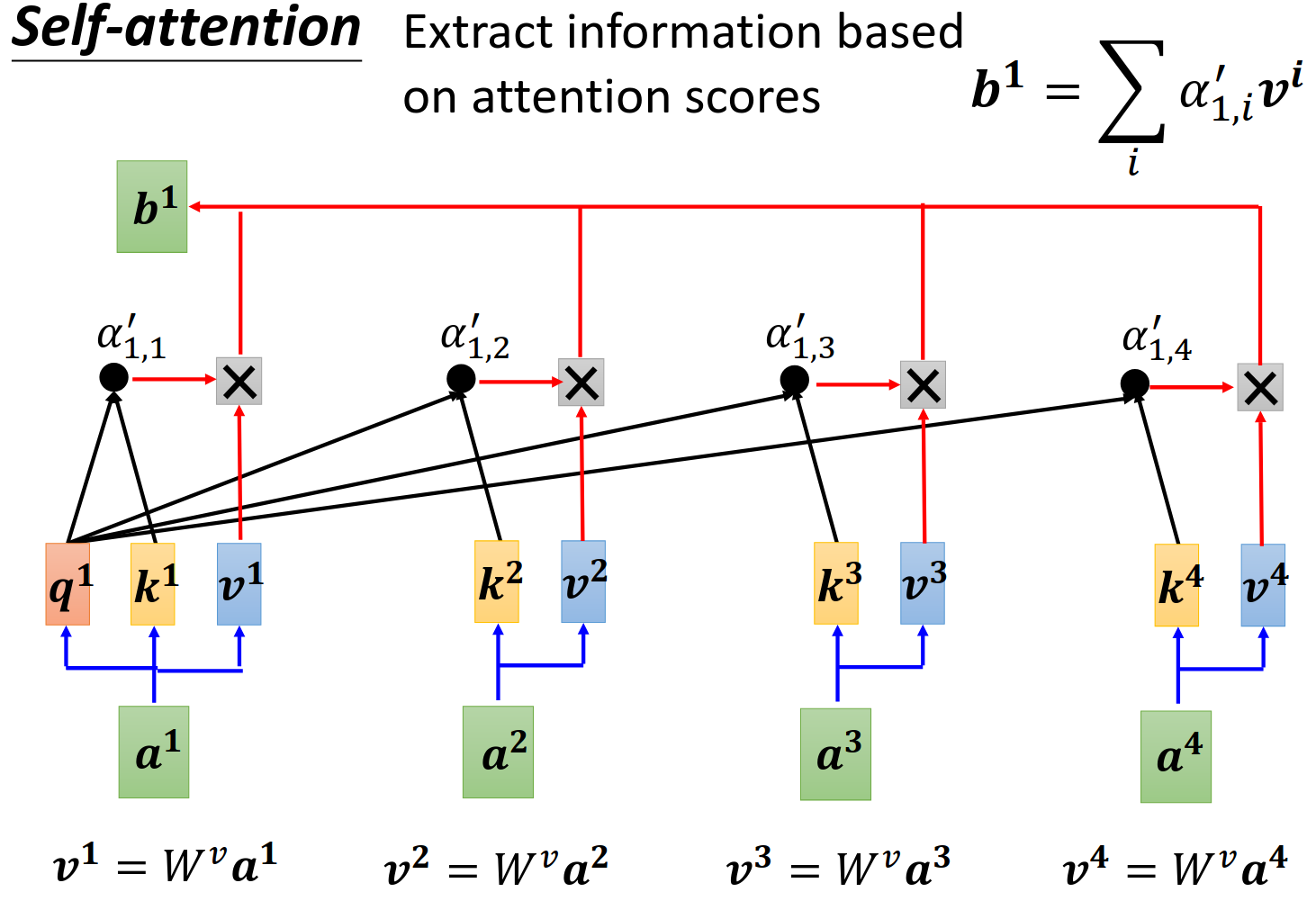
output的计算
谁的
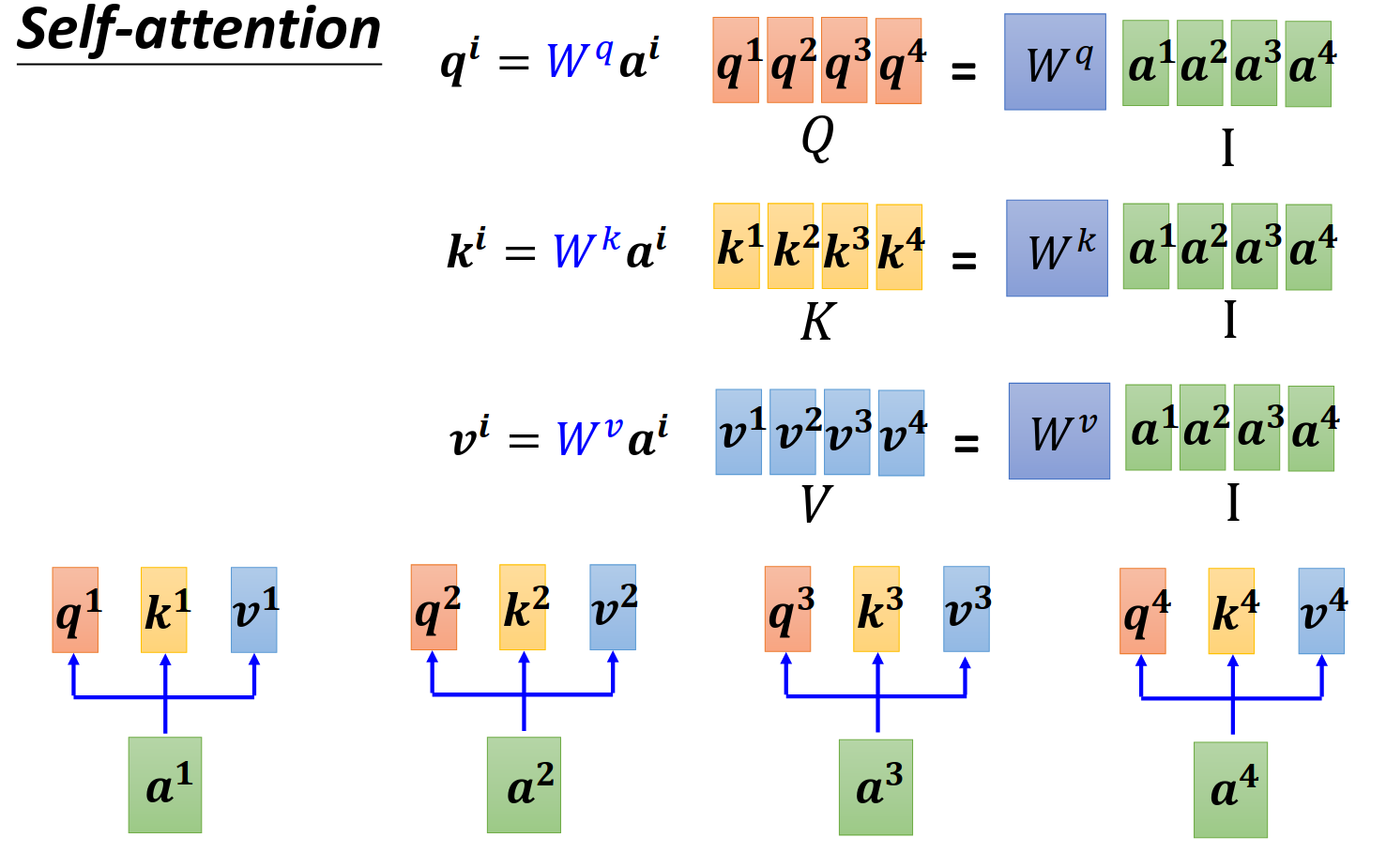
矩阵乘法角度来看
这里面讲解了
更加详细的视角,因此这些
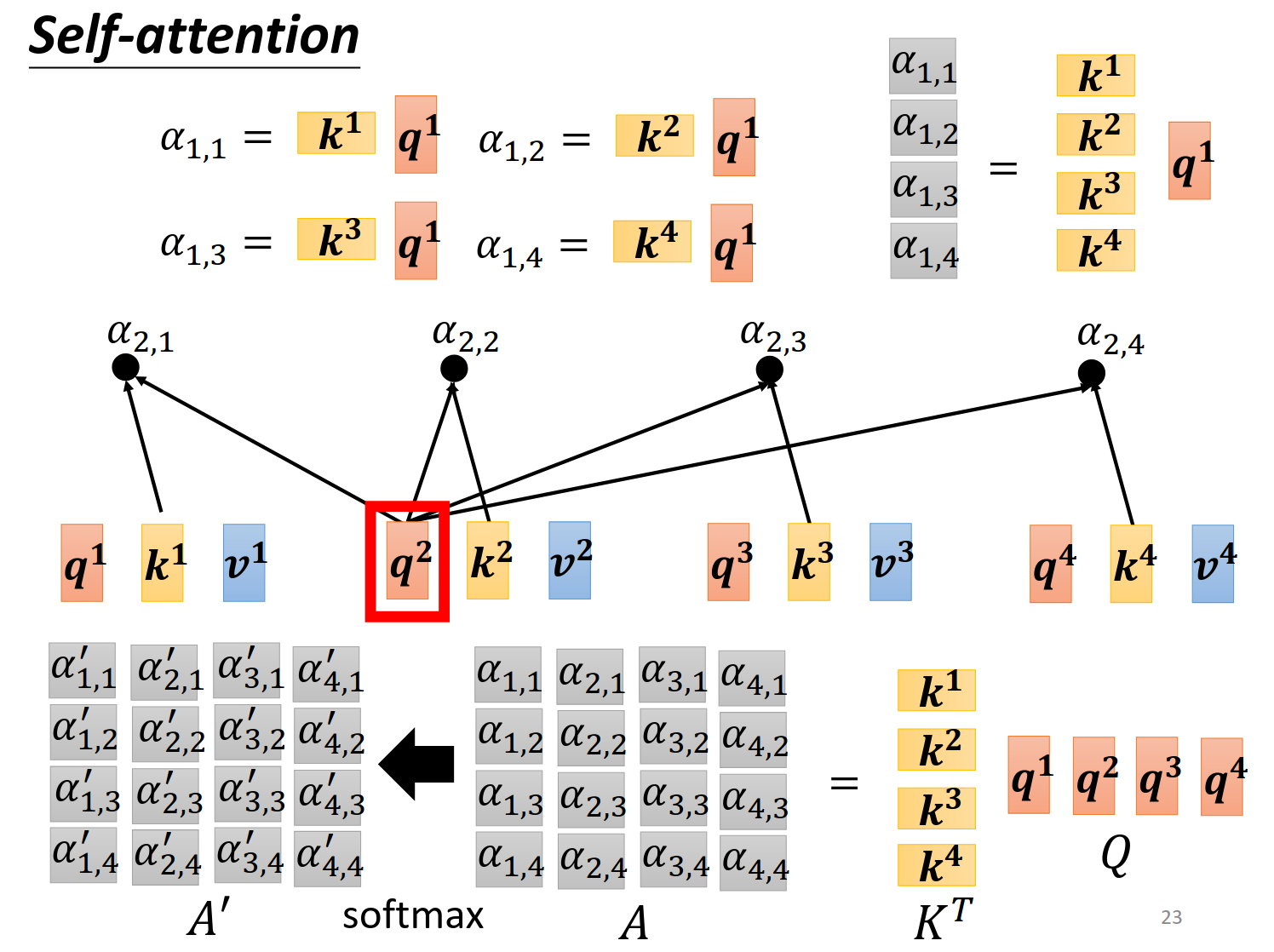
接下来把上一步的输出继续操作。
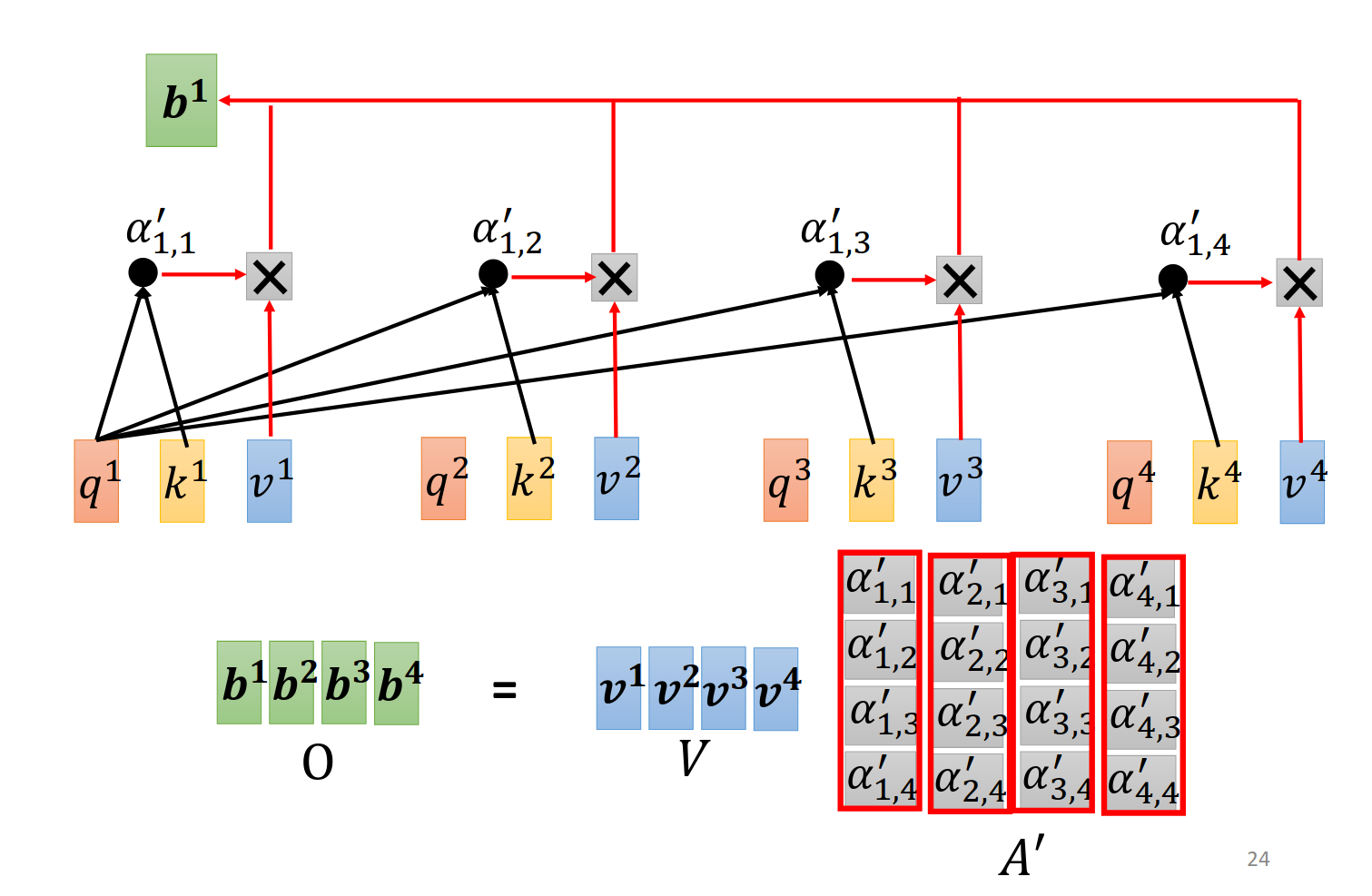
总结一下,只有红色圈出来的地方是我们要机器学习来寻找的参数。
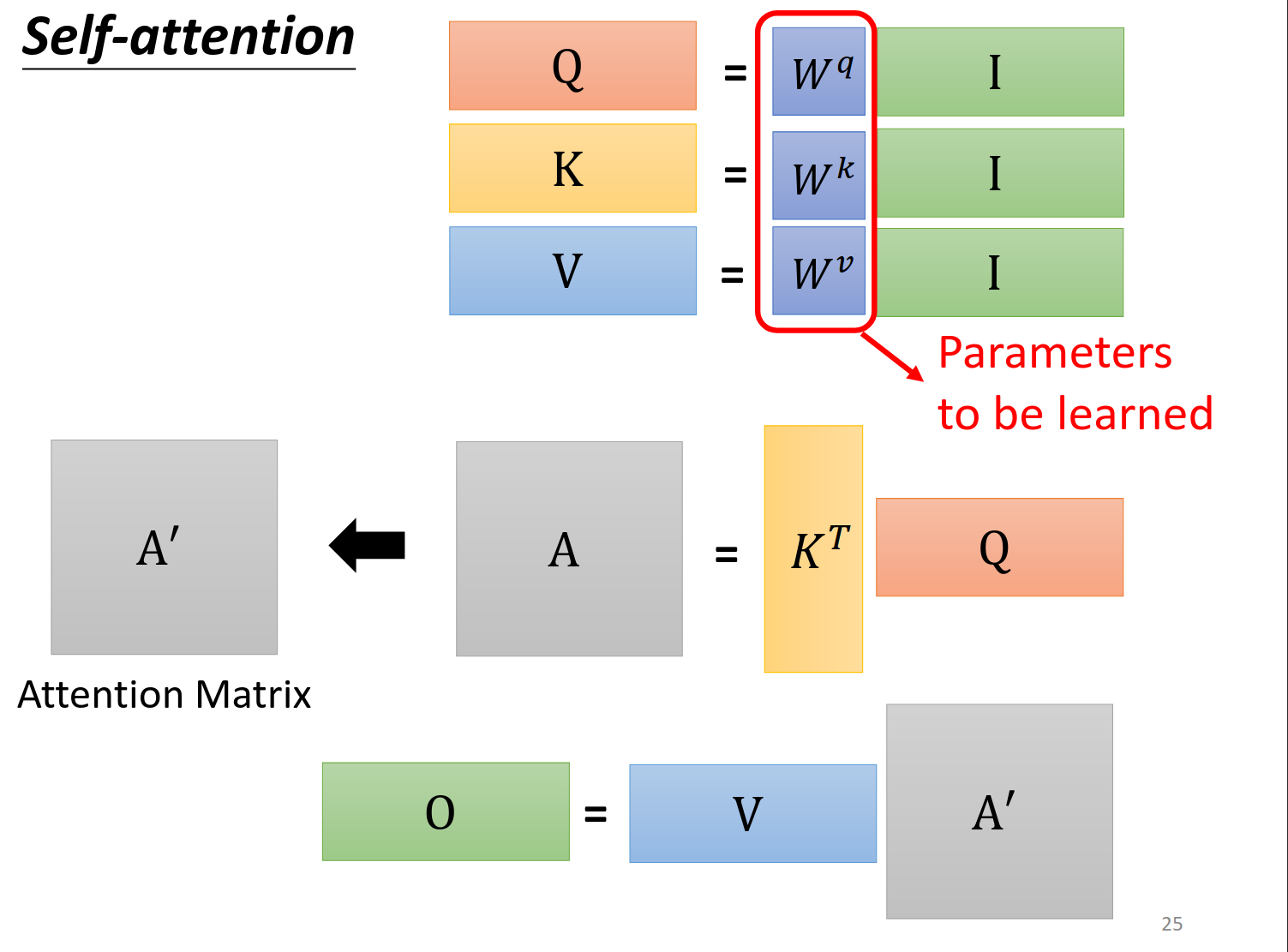
Multi-head Self-attention
进阶版本
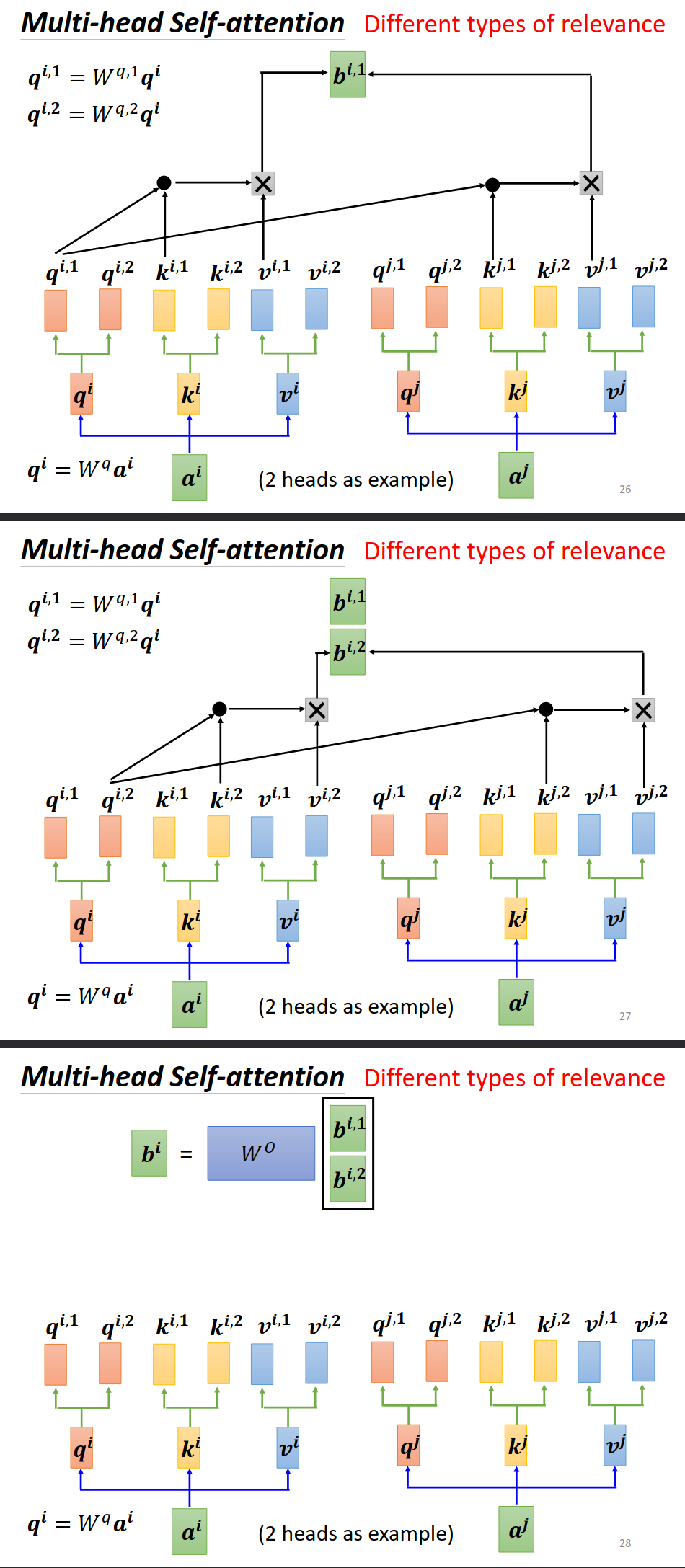
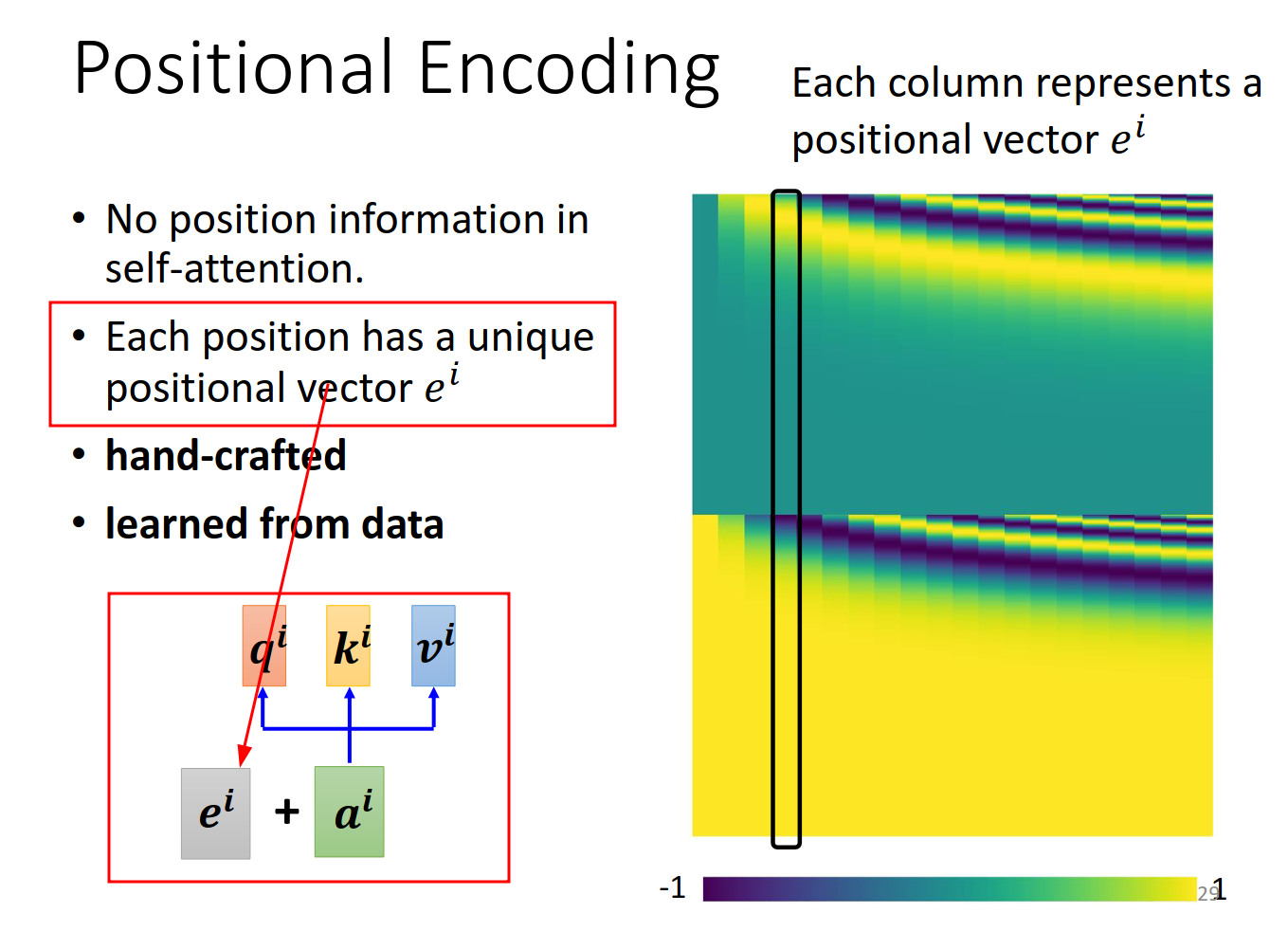
Positional Encoding
之前的selfattention完全没有考虑位置的信息。如何把这个信息也考虑进去呢?
解决方式
positional encoding部分尚待研究https://arxiv.org/abs/2003.09229
Many applications …

Transformer https://arxiv.org/abs/1706.03762
BERT https://arxiv.org/abs/1810.04805
Self-attention for Speech
https://arxiv.org/abs/1910.12977
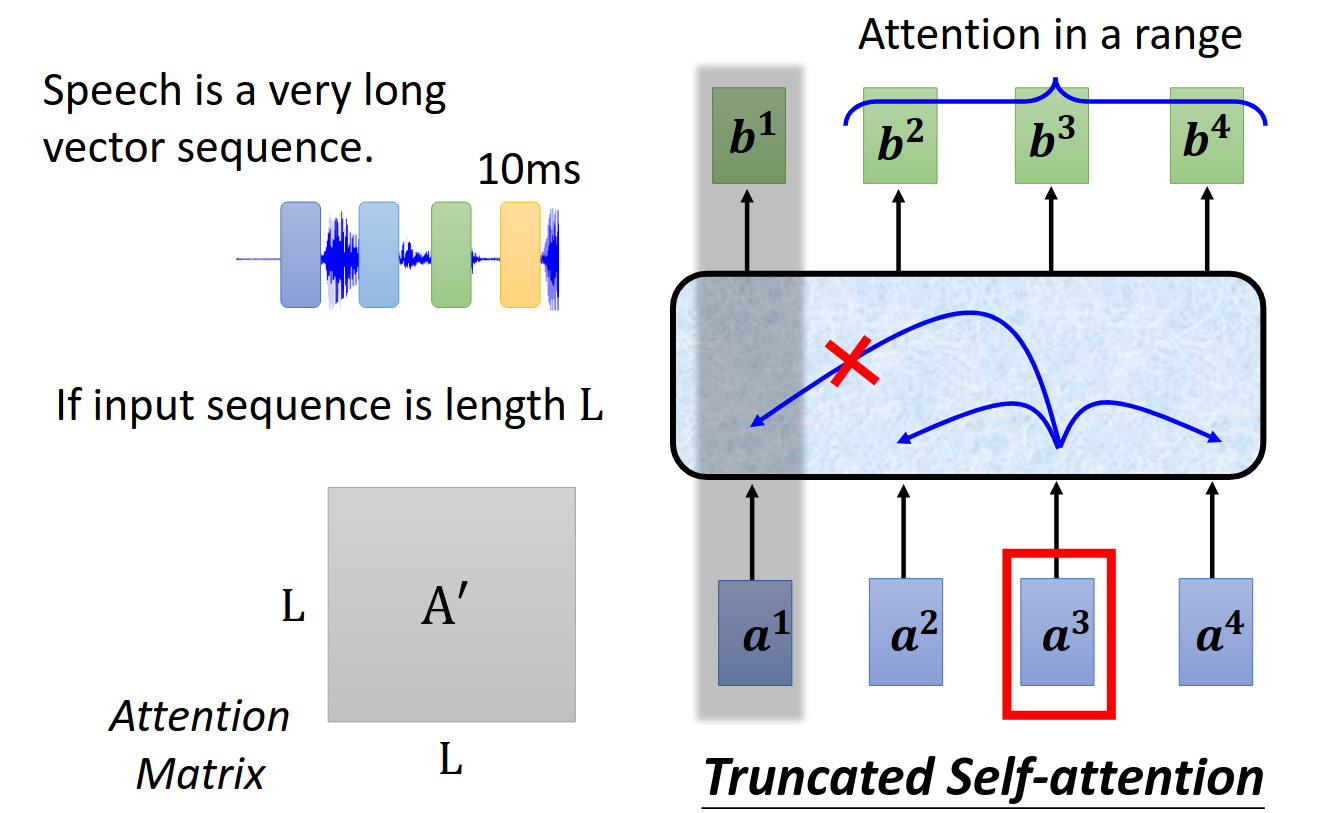
speech信息分割之后特别长,需要memory和compute太多。
所以改进版本就是关联只看一个小范围,而不是所有input vector。这个只是这篇论文的task的解决方案,不一定适用于其他的task。
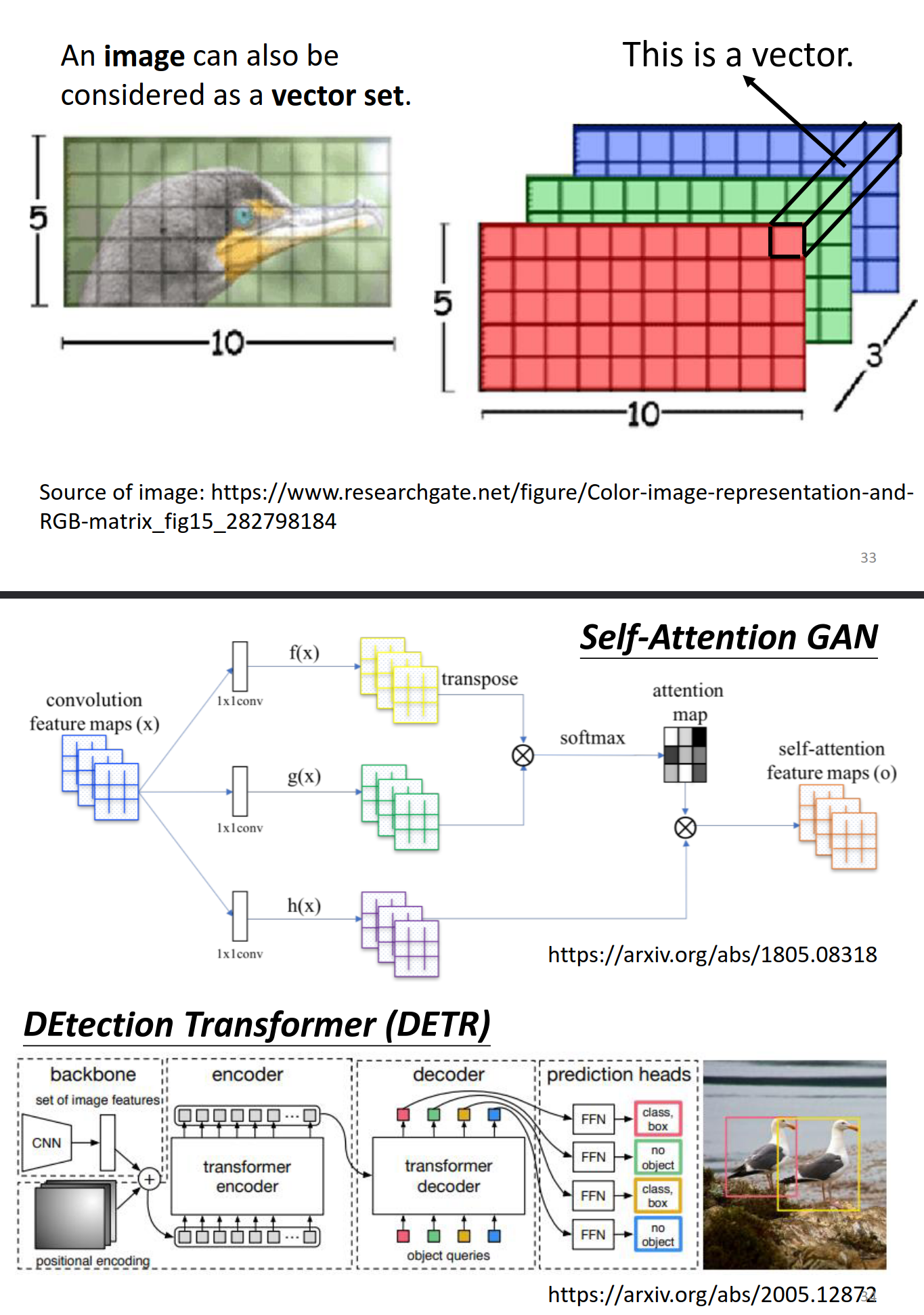
Self-attention for Image
https://arxiv.org/abs/2005.12872
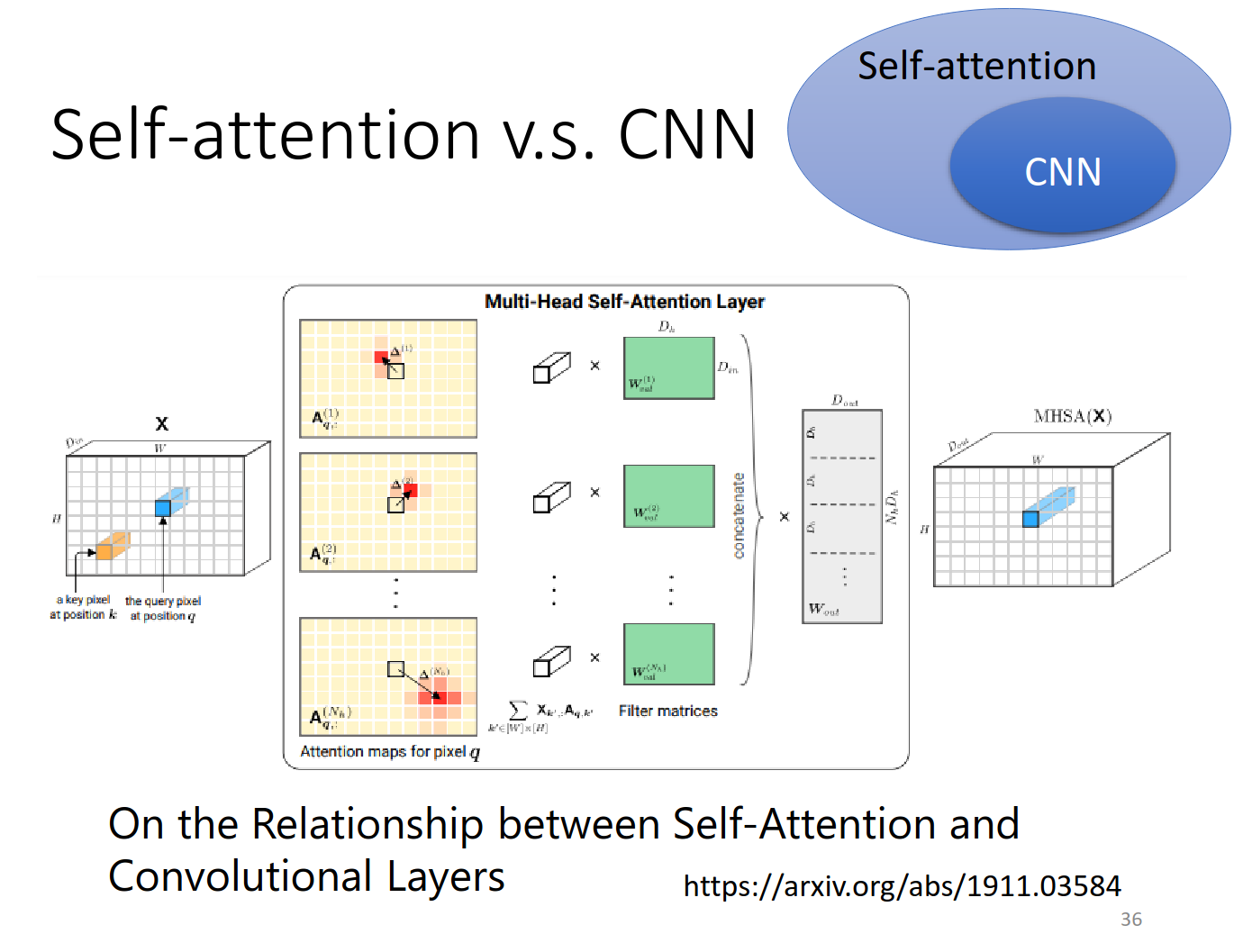
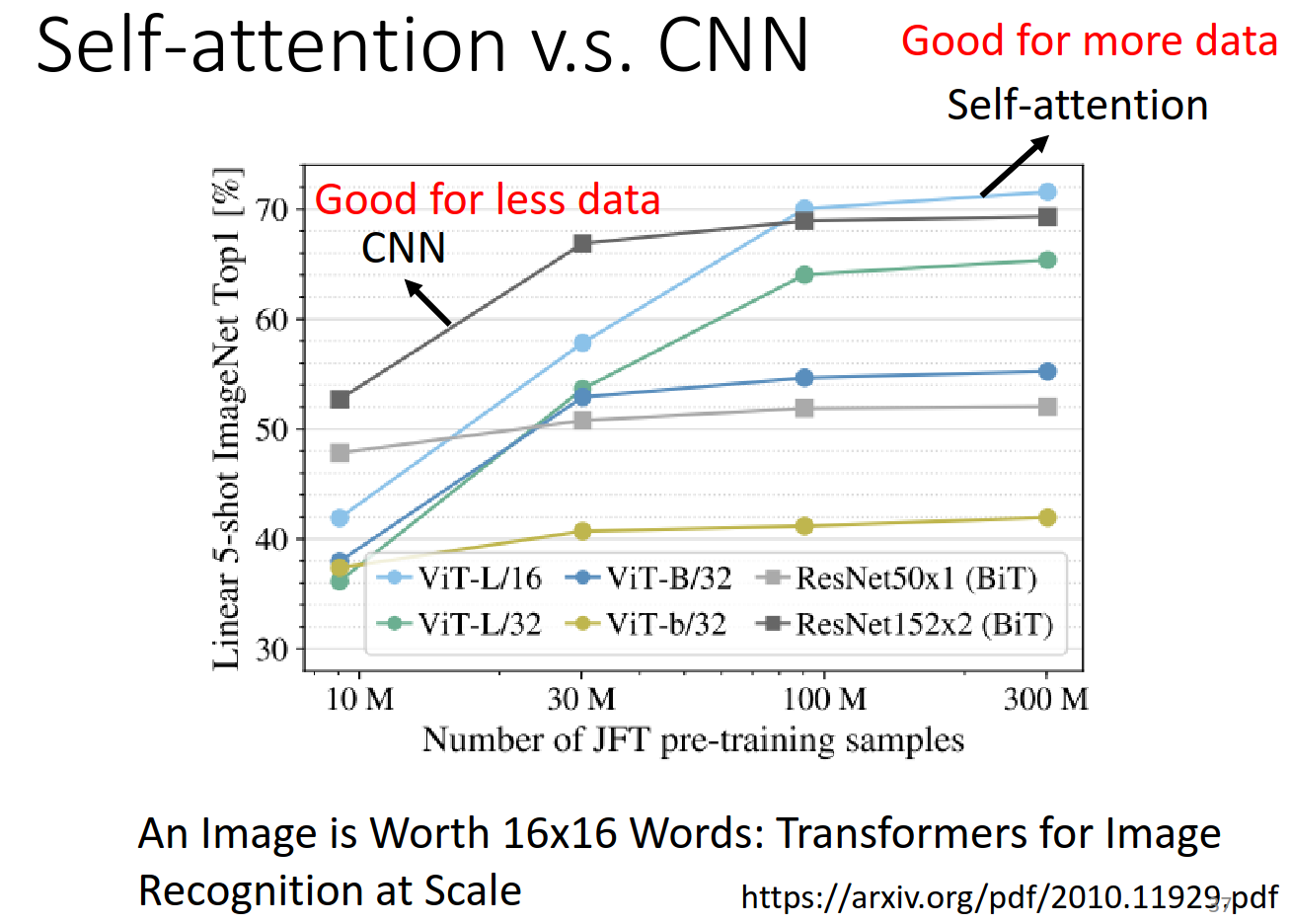
Self-attention v.s. CNN
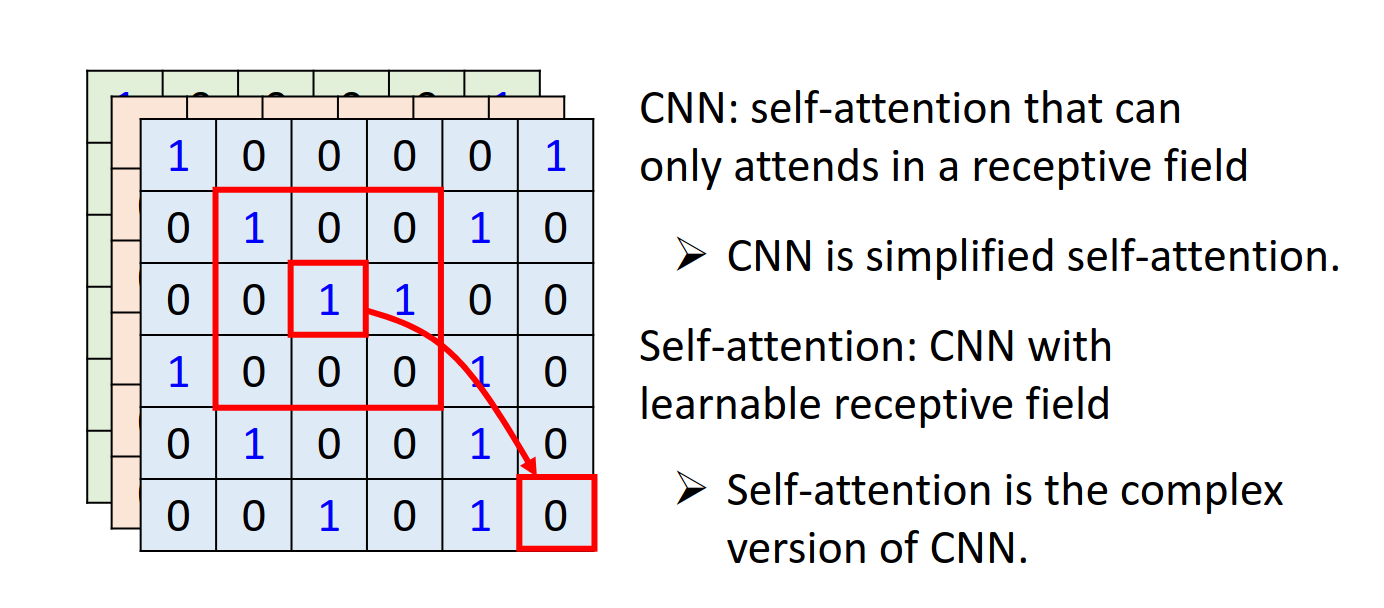
CNN是简化版本的Self-attention!考虑的范围不一样
https://arxiv.org/abs/1911.03584 这个论文数学角度讲解了self-attention是包含CNN的
https://arxiv.org/pdf/2010.11929.pdf
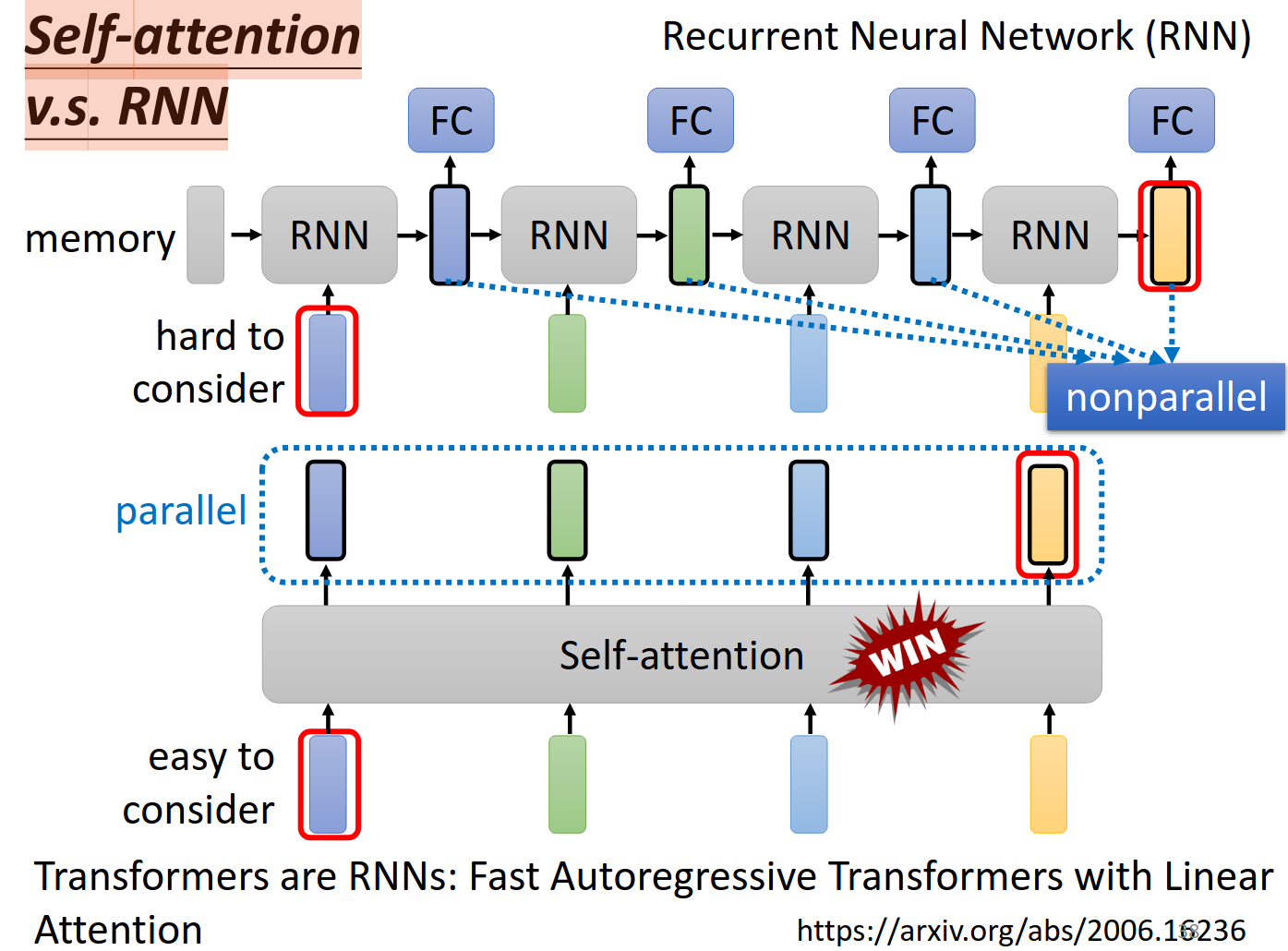
Self-attention v.s. RNN
https://arxiv.org/abs/2006.16236
https://youtu.be/xCGidAeyS4M more about rnn
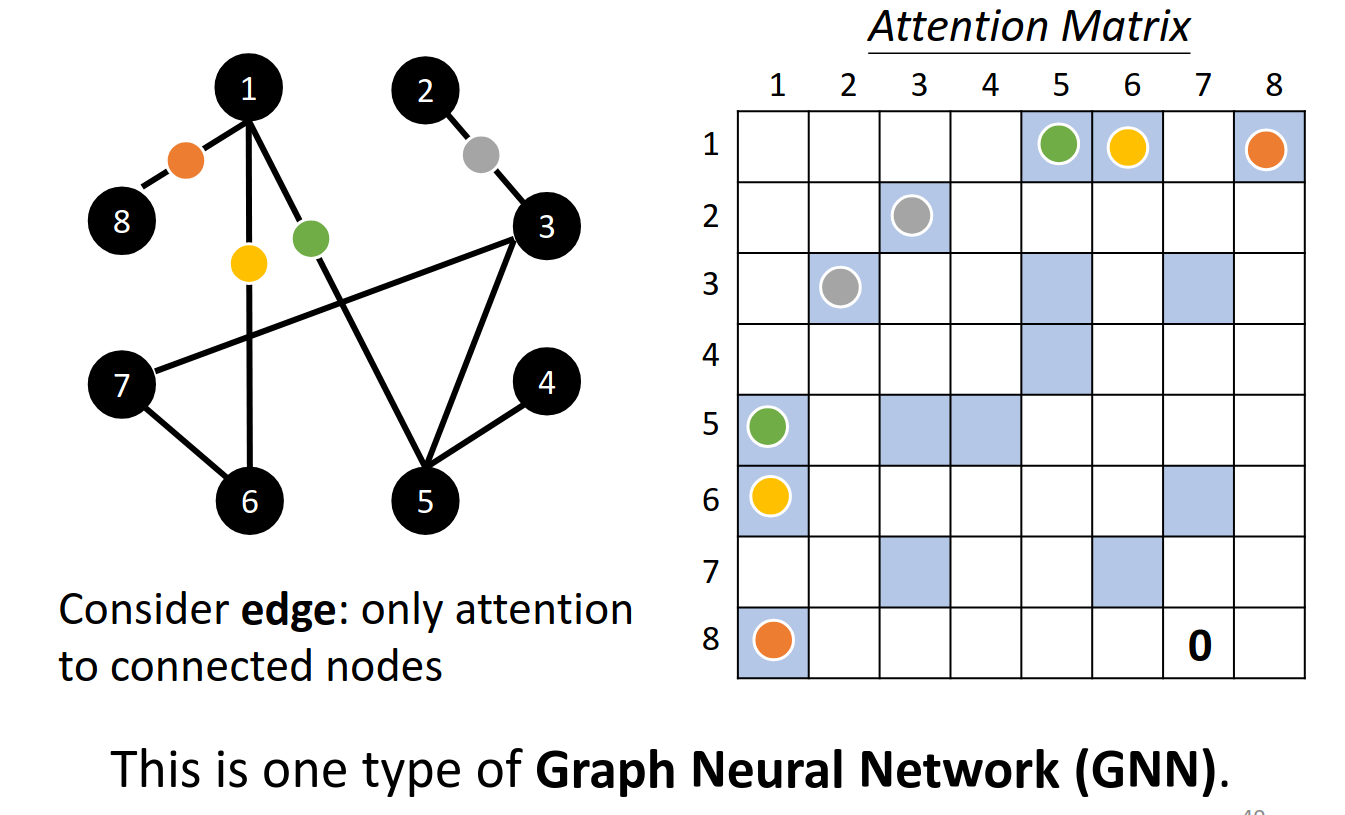
Self-attention for Graph
https://youtu.be/eybCCtNKwzA
https://youtu.be/M9ht8vsVEw8
To Learn More …
selfattention有各种变形
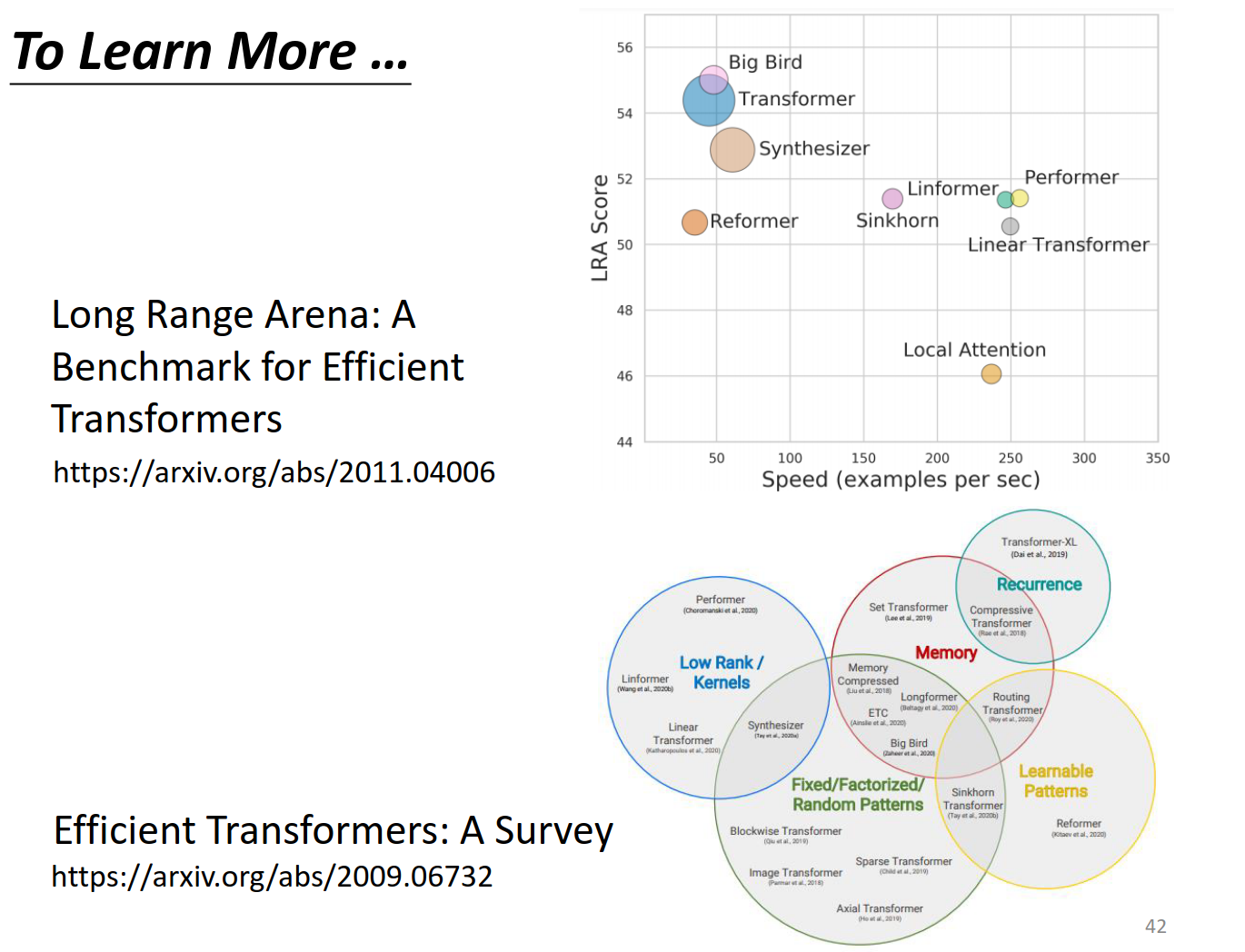
Long Range Arena: A Benchmark for Efficient Transformers介绍了各种变形
https://arxiv.org/abs/2011.04006
Efficient Transformers: A Survey 各种变形
https://arxiv.org/abs/2009.06732