Transformer
Sequence-to-sequence (Seq2seq)
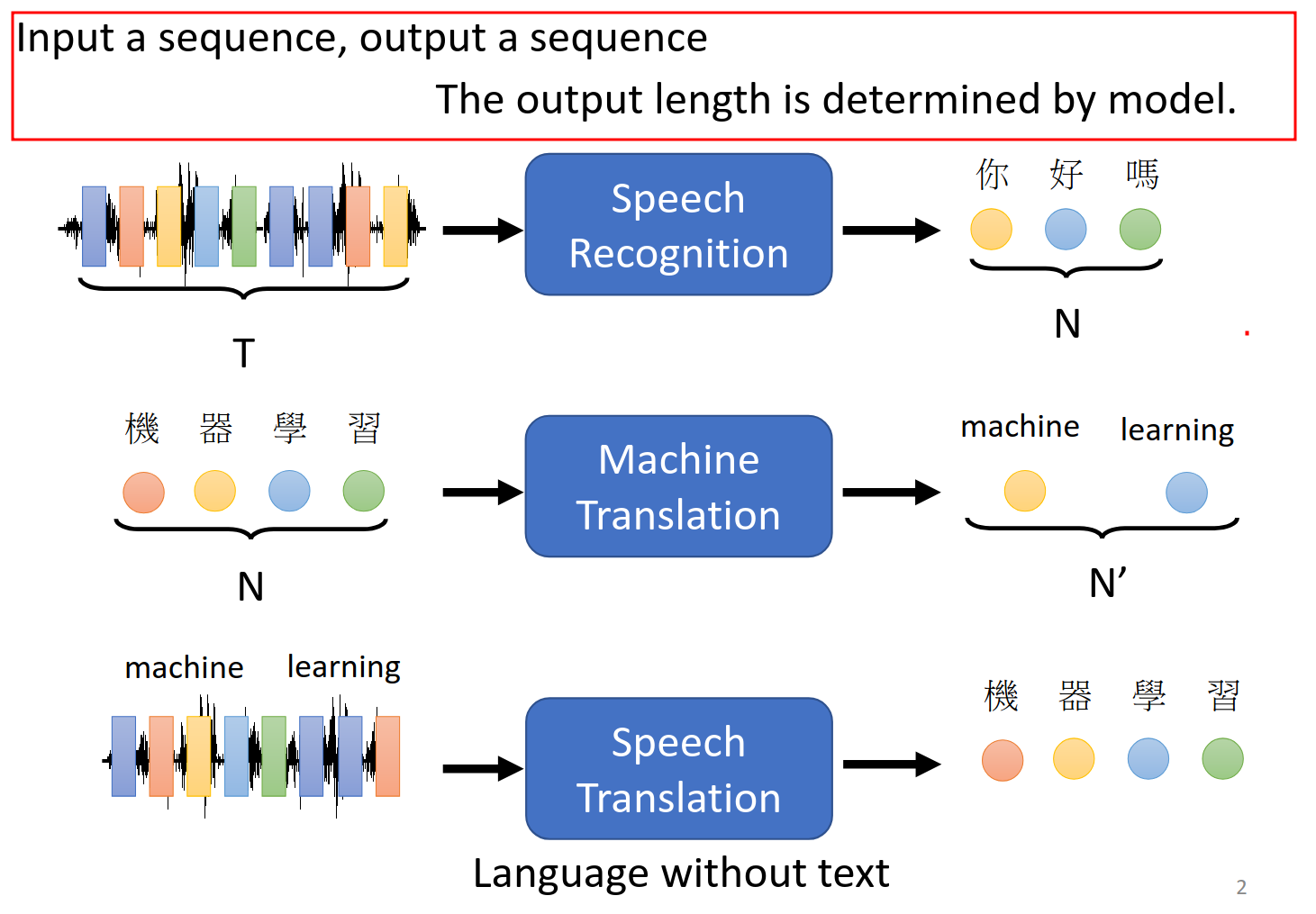
注意输入输出长度是不一样的,输出长度是模型自己判断出来的。就是把输入的和输出的准备好然后直接给机器让他训练。似乎有点像端到端的概念。
各种应用
大多数应用都可以变成seq2seq的问题。
https://arxiv.org/abs/1806.08730
https://arxiv.org/abs/1909.03329
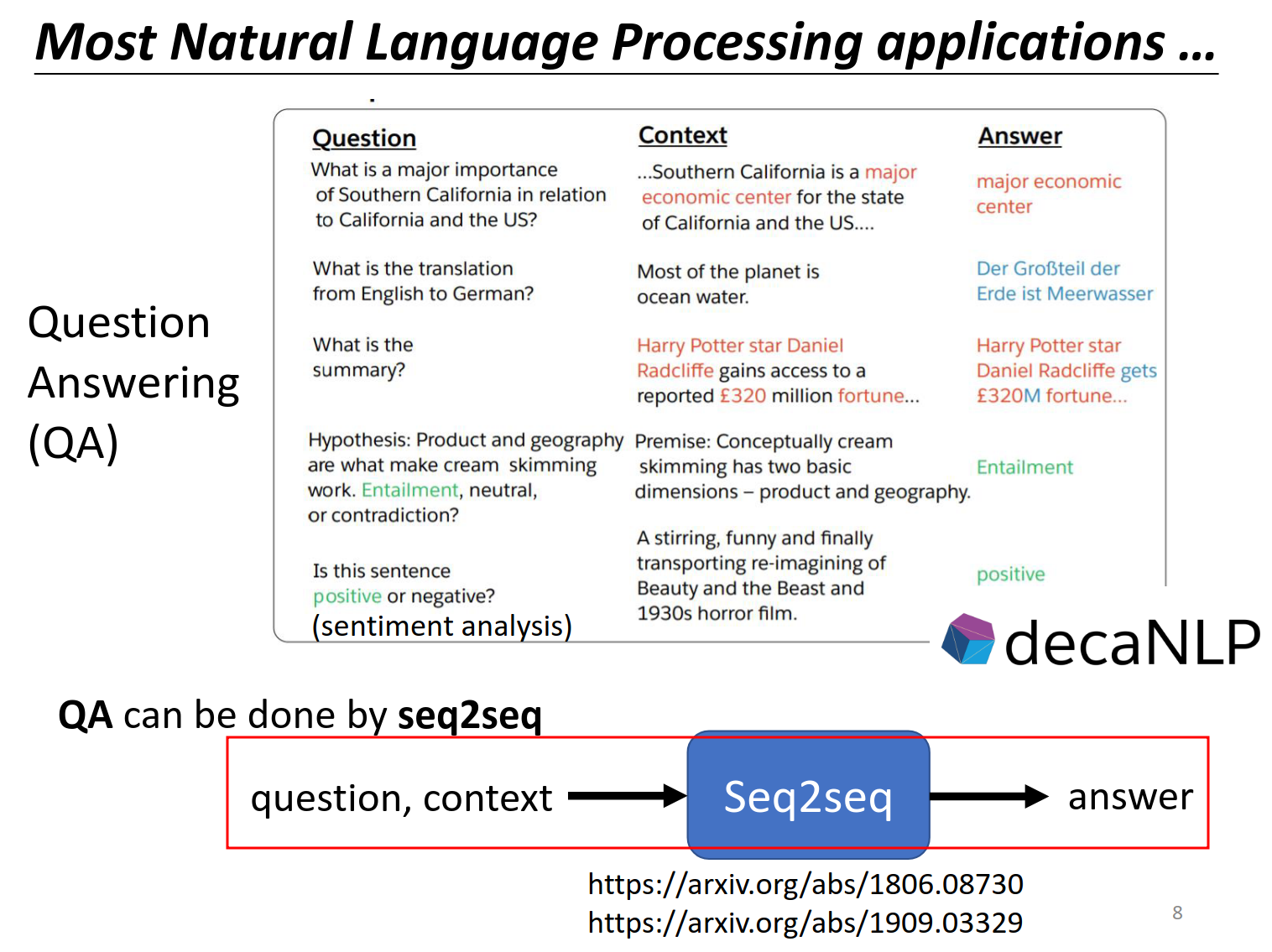
关于NLP更多内容去这里学习,本课程不仔细讲解。
Source webpage: https://speech.ee.ntu.edu.tw/~hylee/dlhlp/2020-spring.html
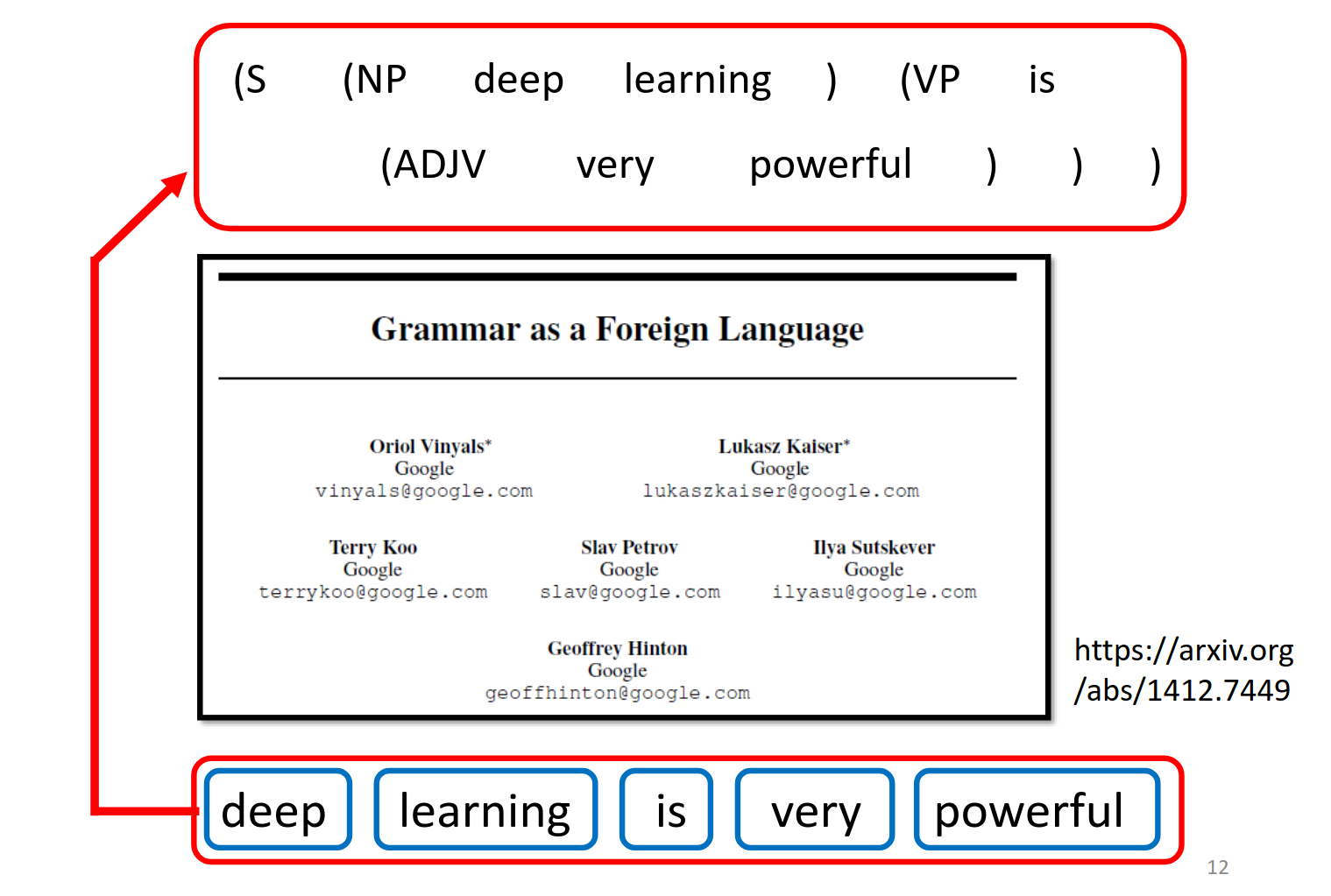
Seq2seq for Syntactic Parsing
https://arxiv.org/abs/1412.7449
把语法解析当作另外一种语言,直接来做机器翻译
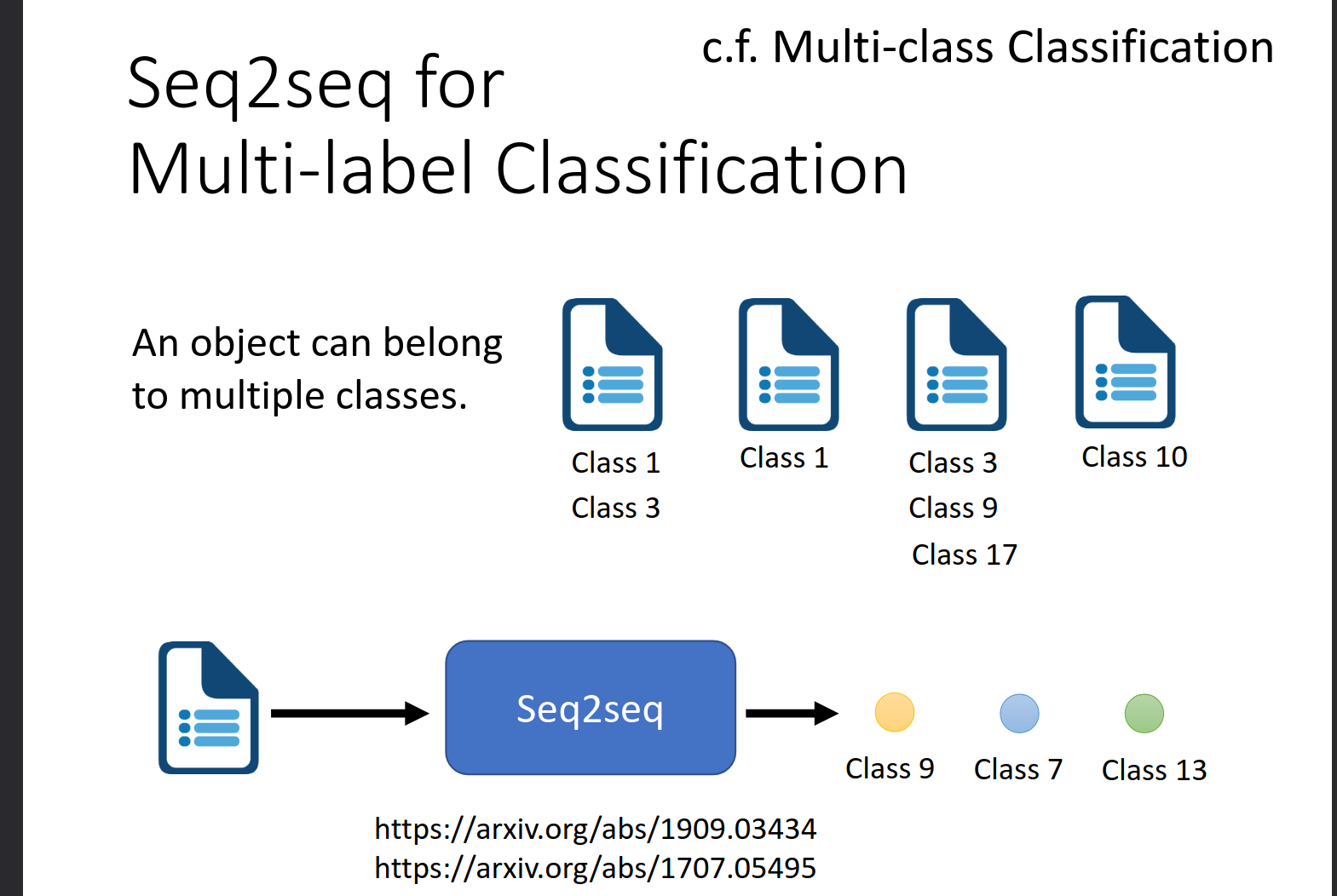
Seq2seq for Multi-label Classification
https://arxiv.org/abs/1909.03434
https://arxiv.org/abs/1707.05495
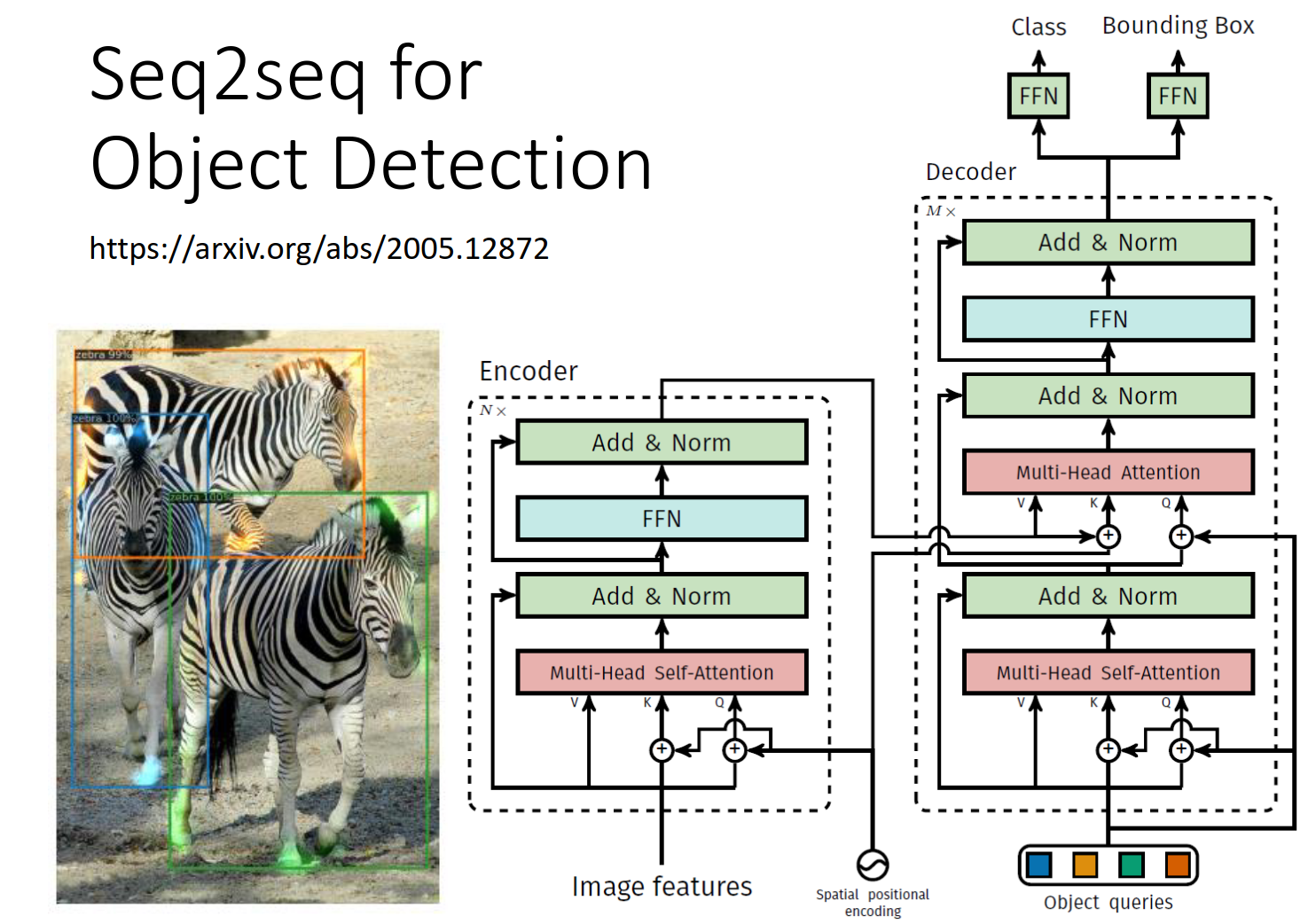
Seq2seq for Object Detection
https://arxiv.org/abs/2005.12872
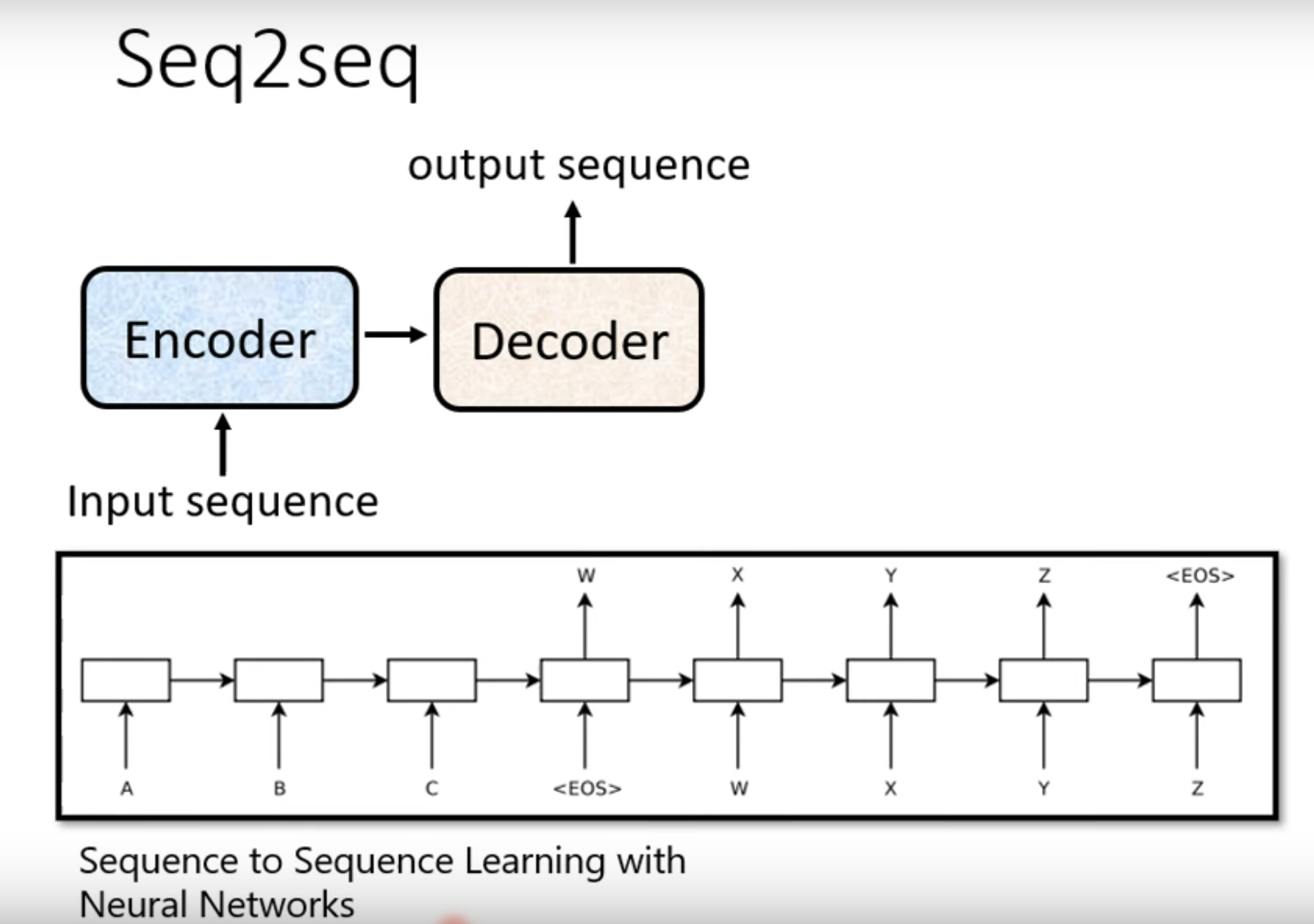
Seq2Seq的结构
https://arxiv.org/abs/1409.3215
这篇论文最早提出了这个s2s
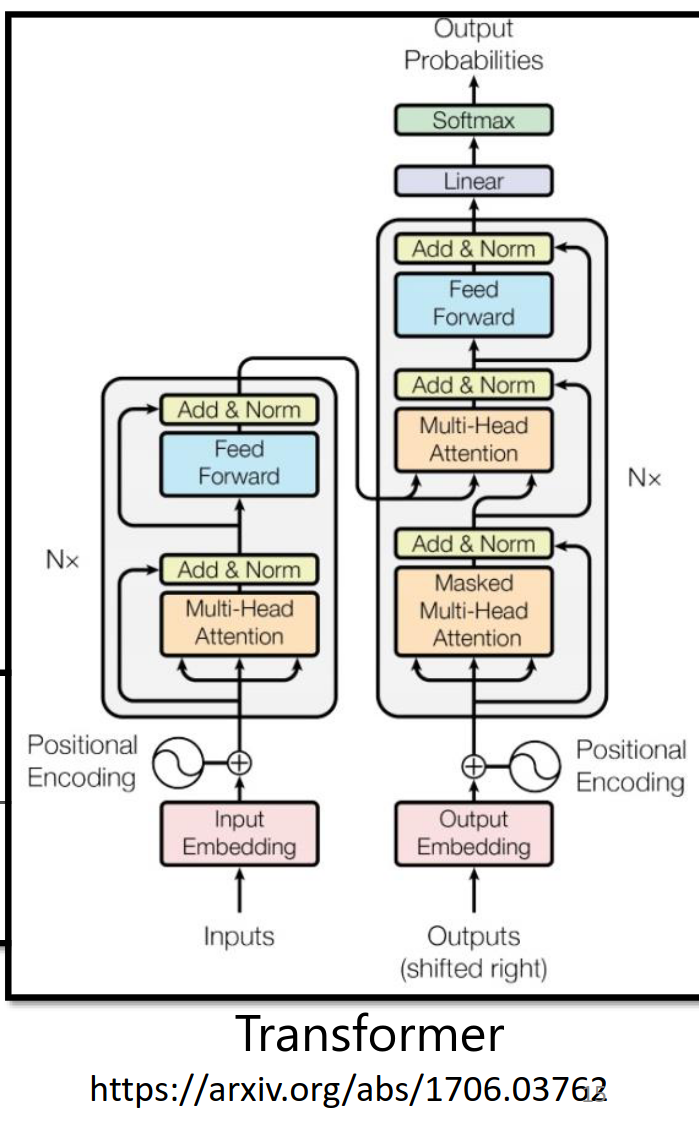
但是我们更熟悉 https://arxiv.org/abs/1706.03762
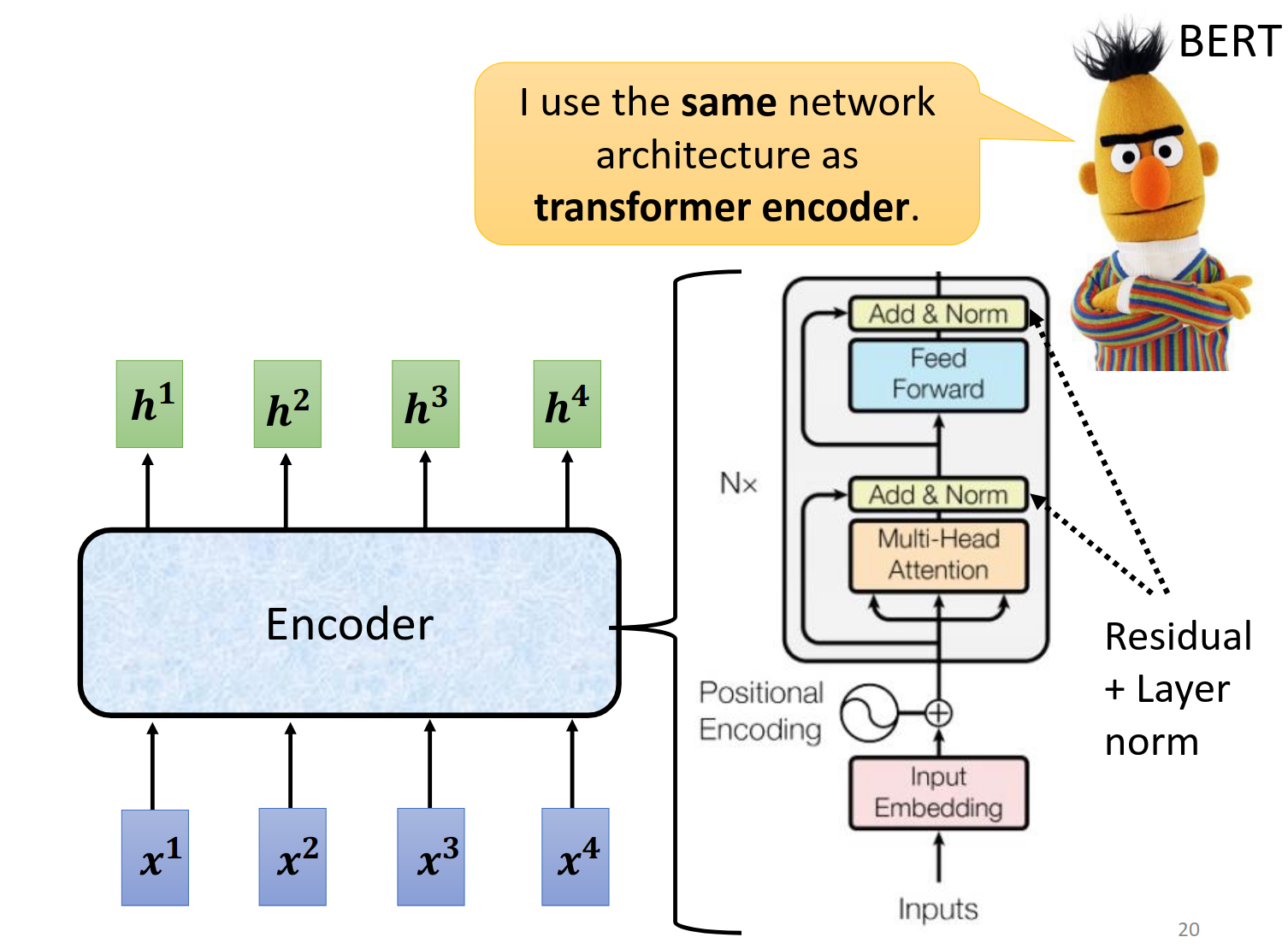
Encoder
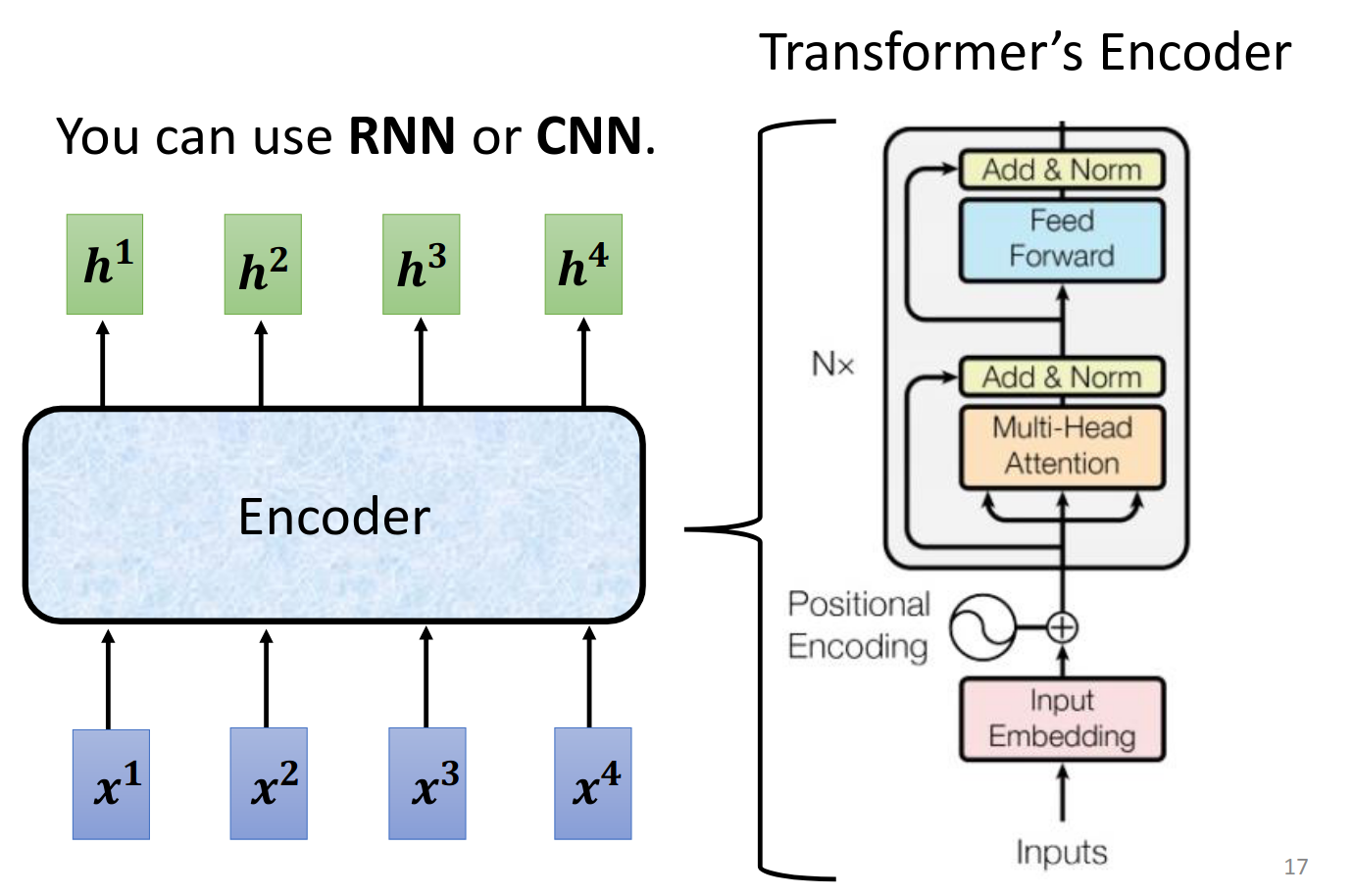
我们先来看一个简要介绍(注意他不是transformer里的真实结构)
其中输入进入Block,然后得到输出,注意一个Block里面有很复杂的结构
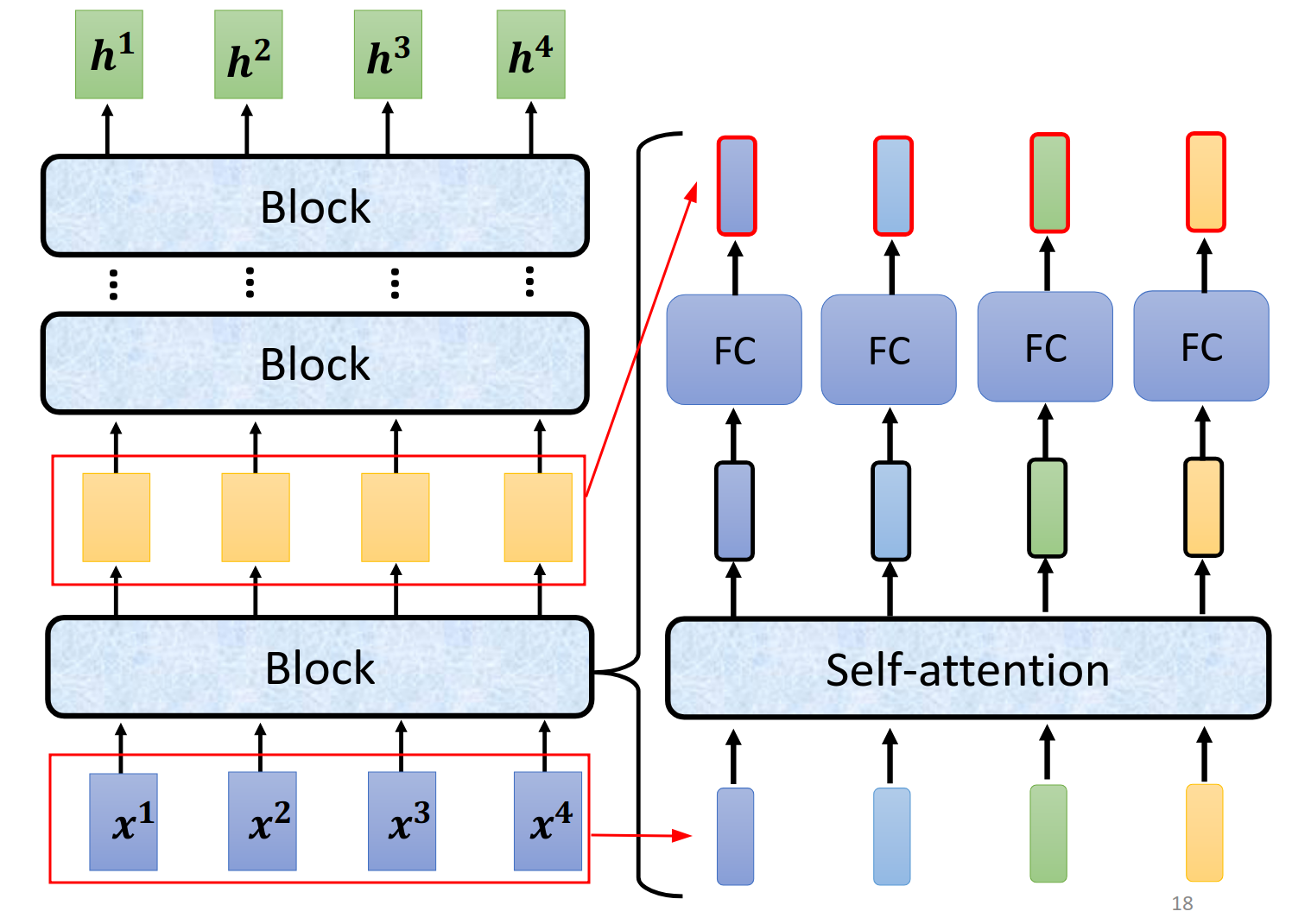
真正的transformer是下面这样的结构,注意红线连接的两个部分是同一个。右边的红色框部分才是最后的输出。
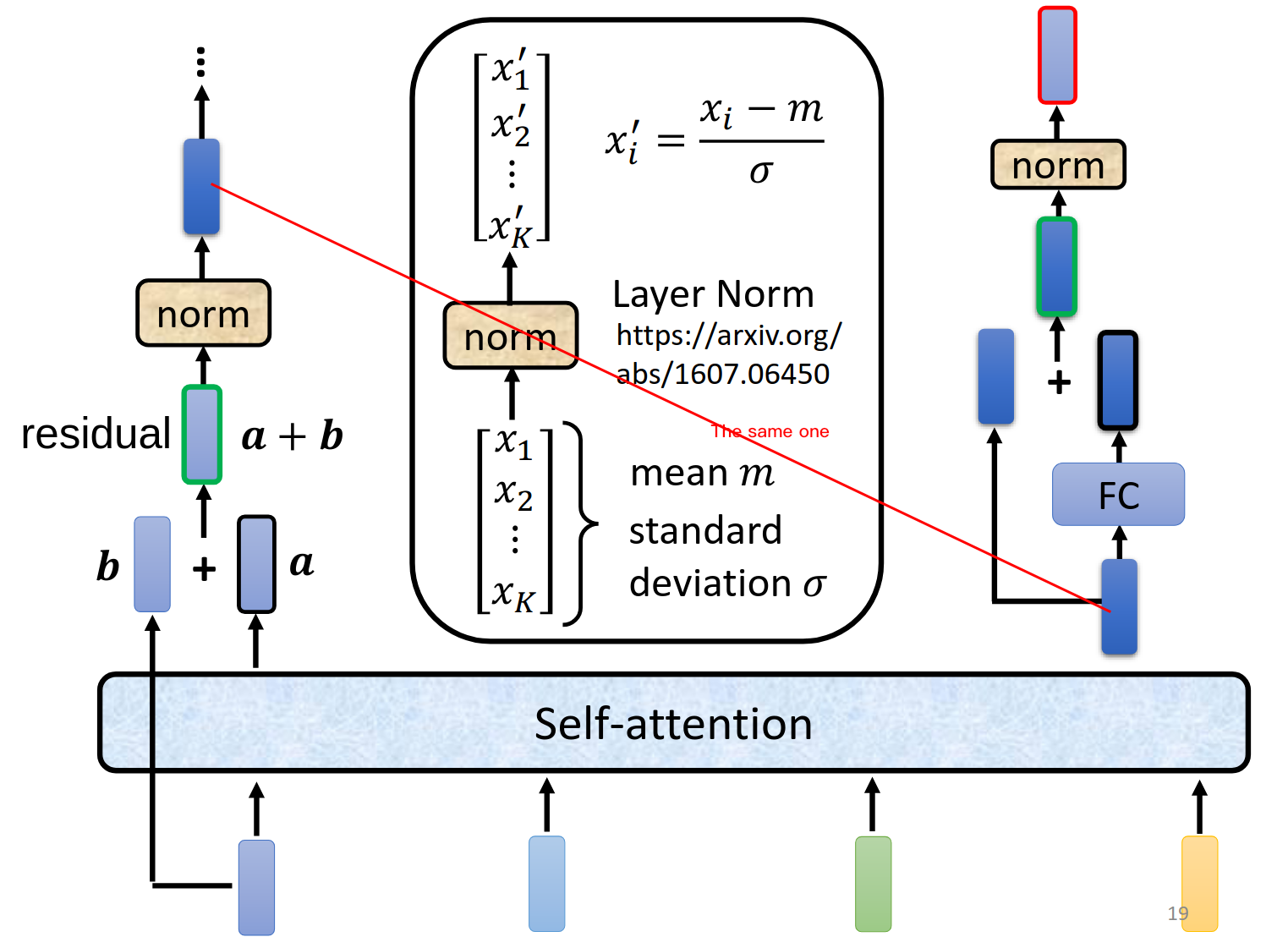
这个结构是原论文设计的,不一定非要这样才好
On Layer Normalization in the Transformer Architecture
https://arxiv.org/abs/2002.04745
PowerNorm: Rethinking Batch Normalization in Transformers
https://arxiv.org/abs/2003.07845
Decoder
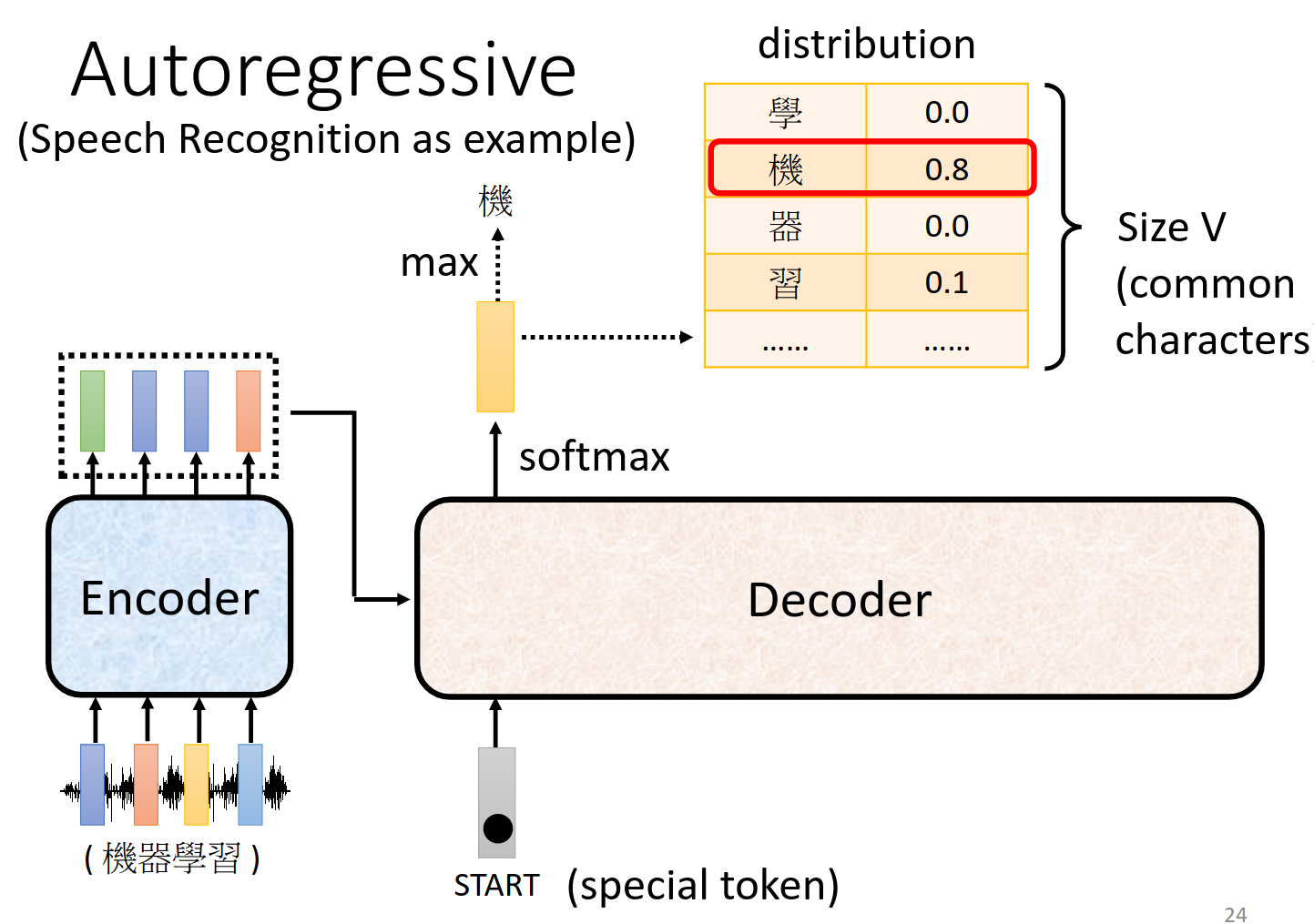
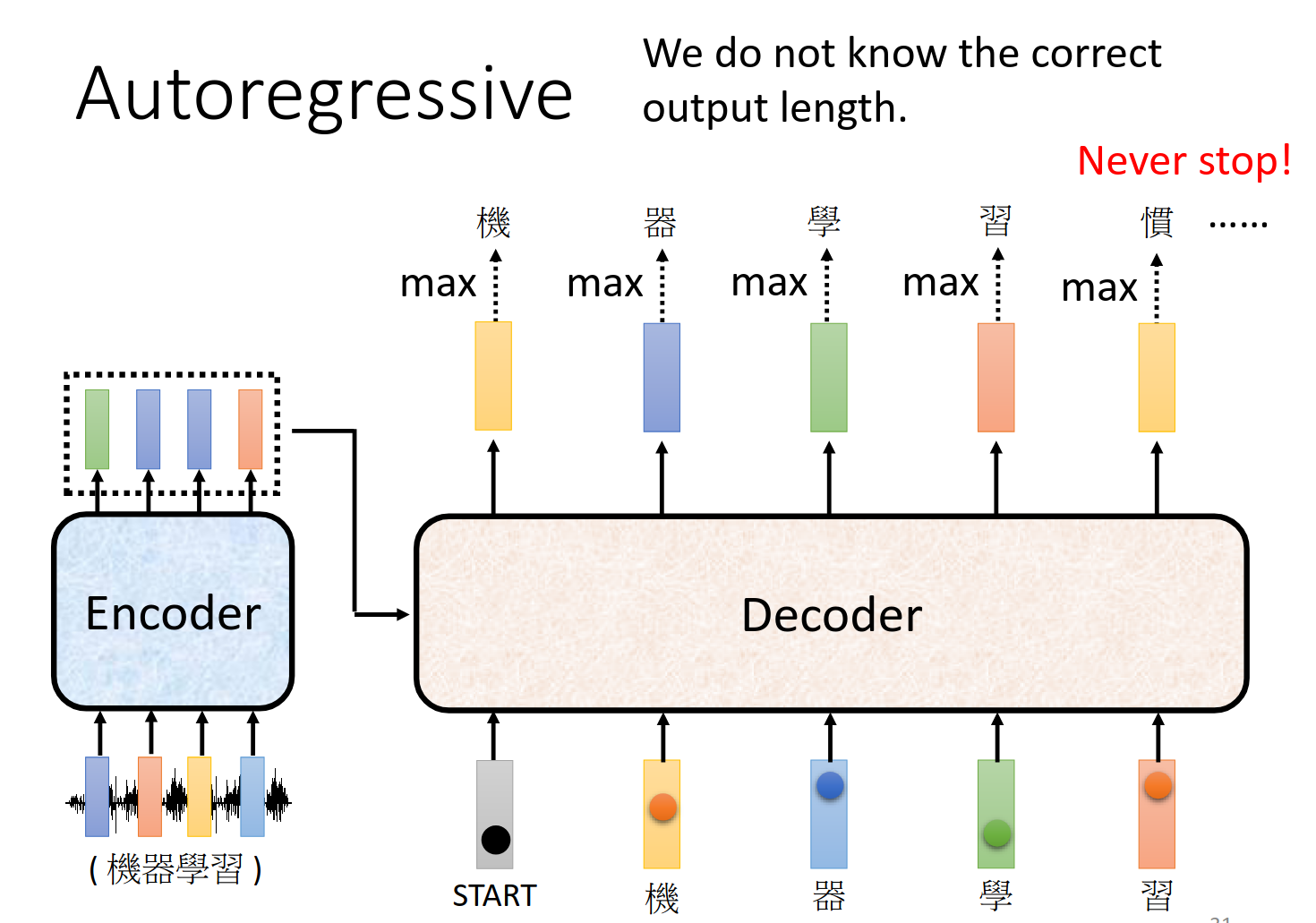
大体过程 Autoregressive (AT)
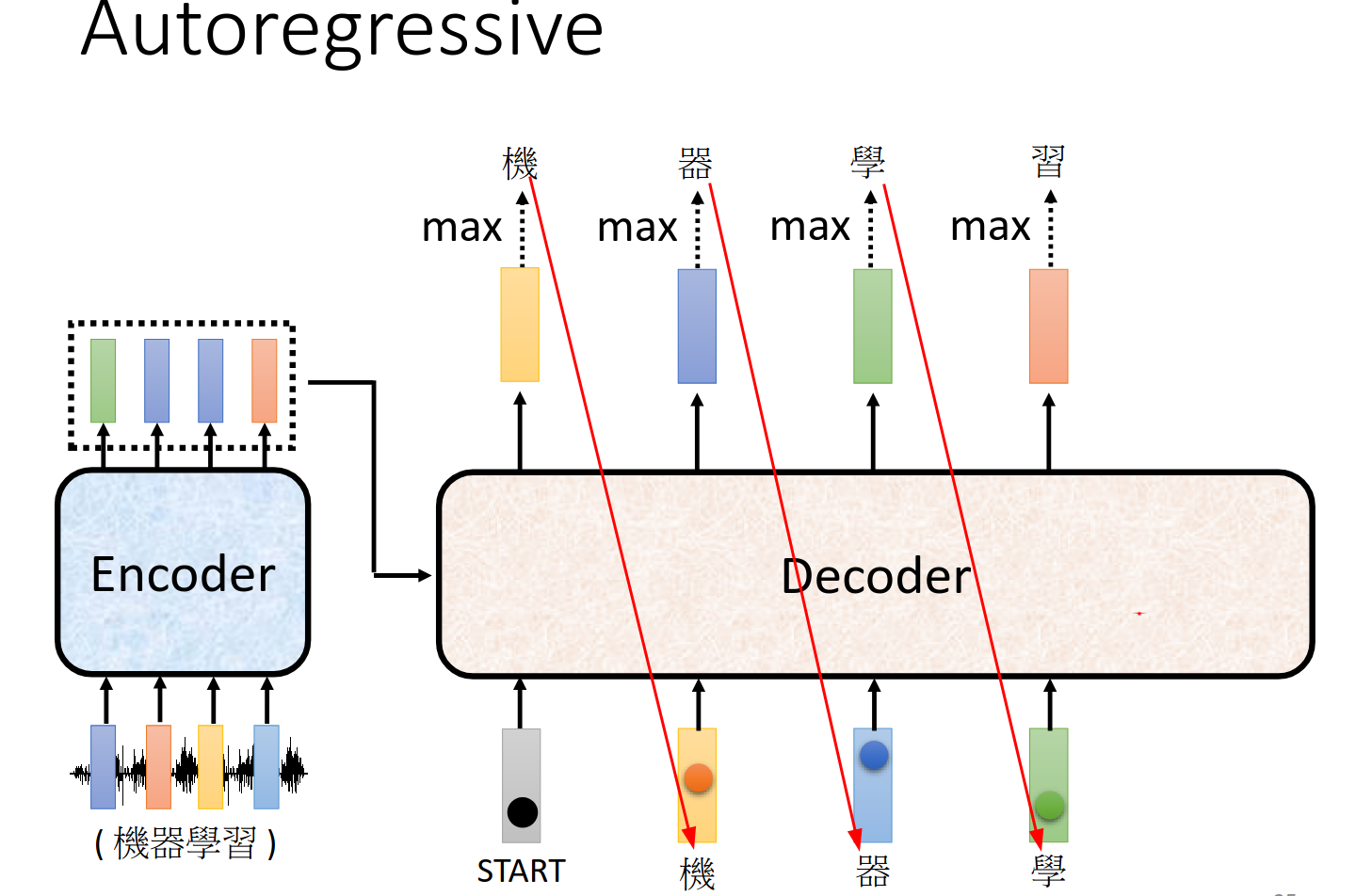
具体结构
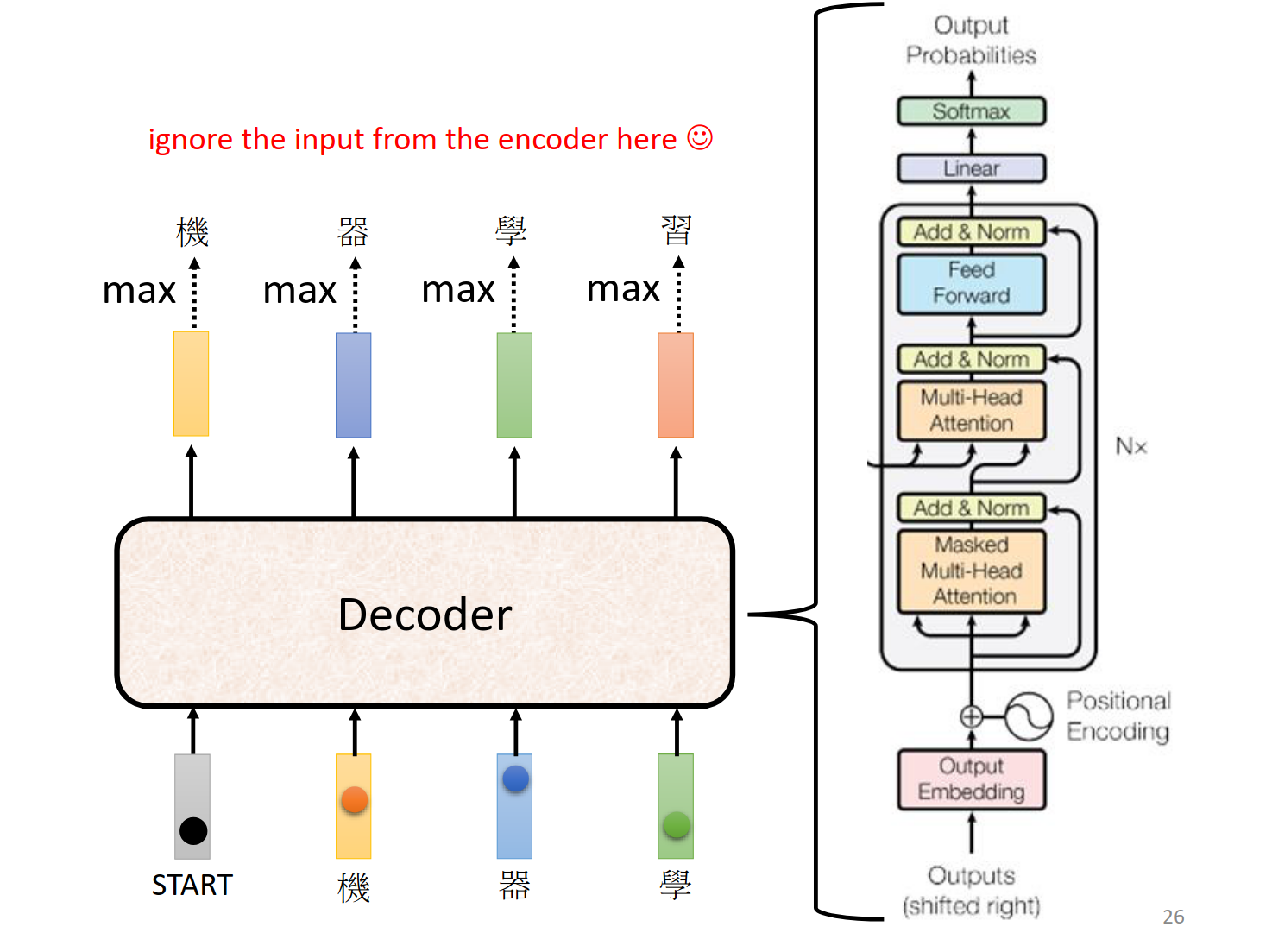
对比,可以看到除了盖住的部分整体结构差不多。其中Masked的描述我们接下来讲解下。
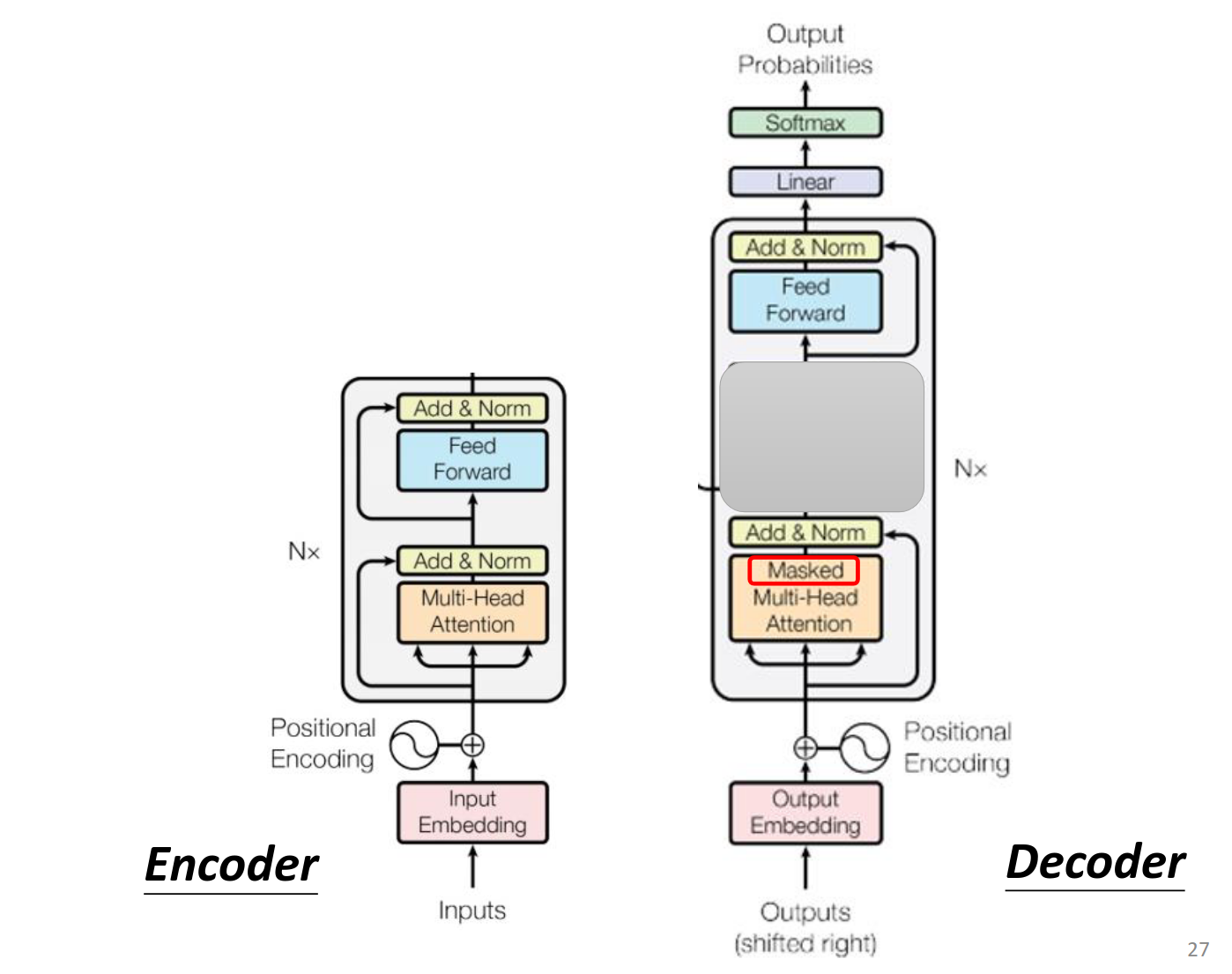
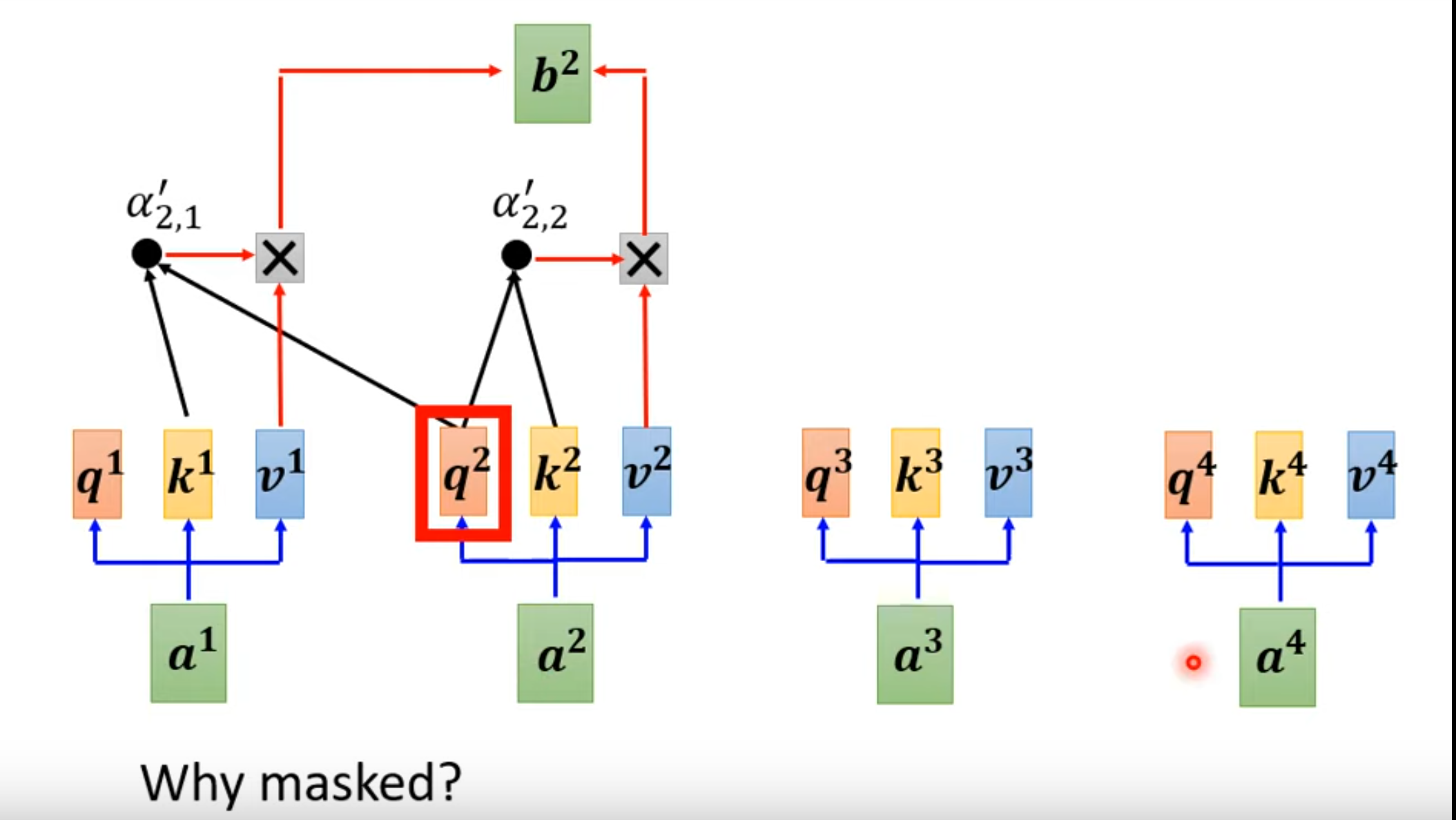
Masked self-attention
只考虑左边的输出,不考虑右边的
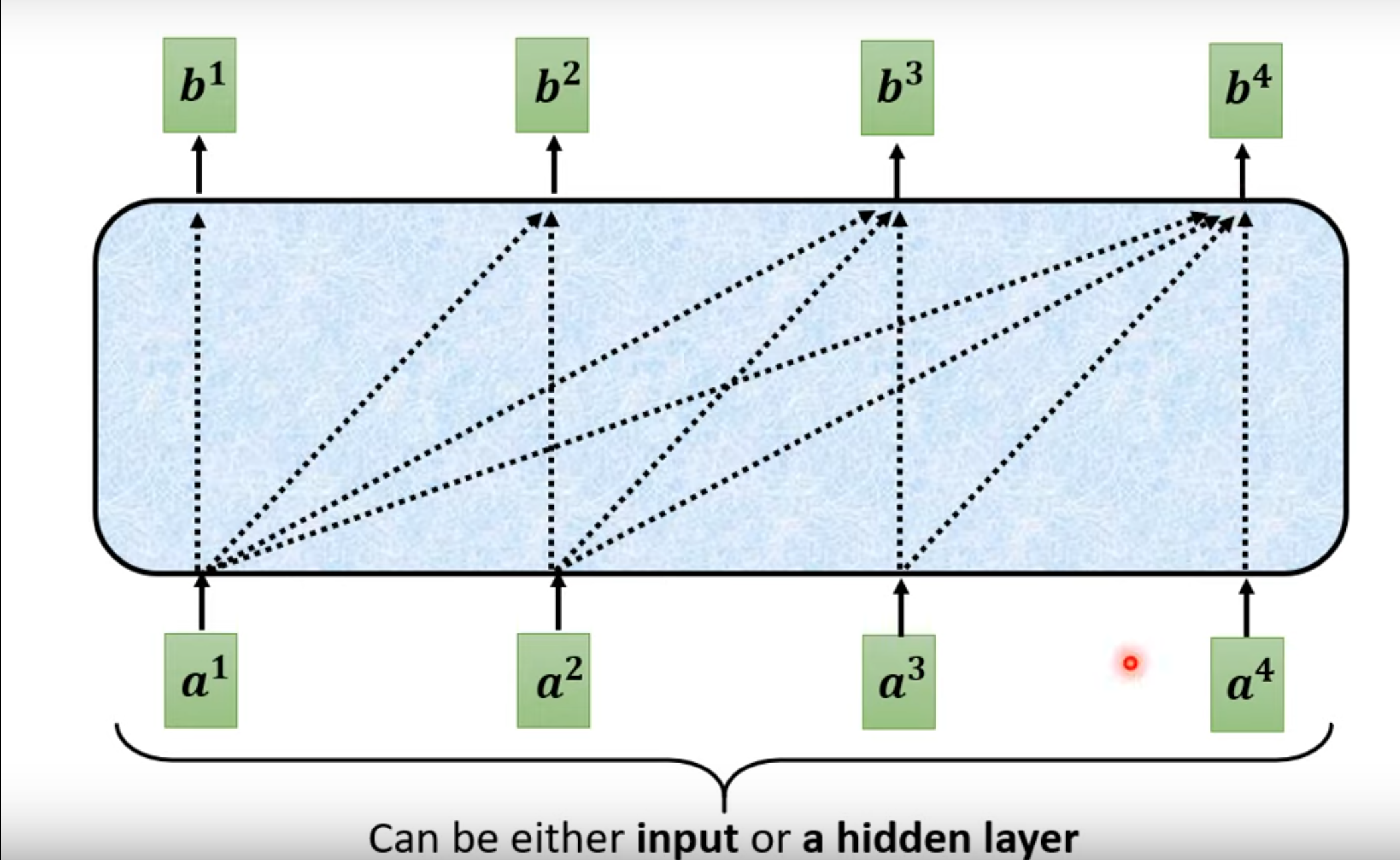
如果考虑具体的结构,那么如下,其实很好理解,token的产生是按照顺序从左到右产生的,也就是说就算像把
但是这样永远不会停歇呀!!
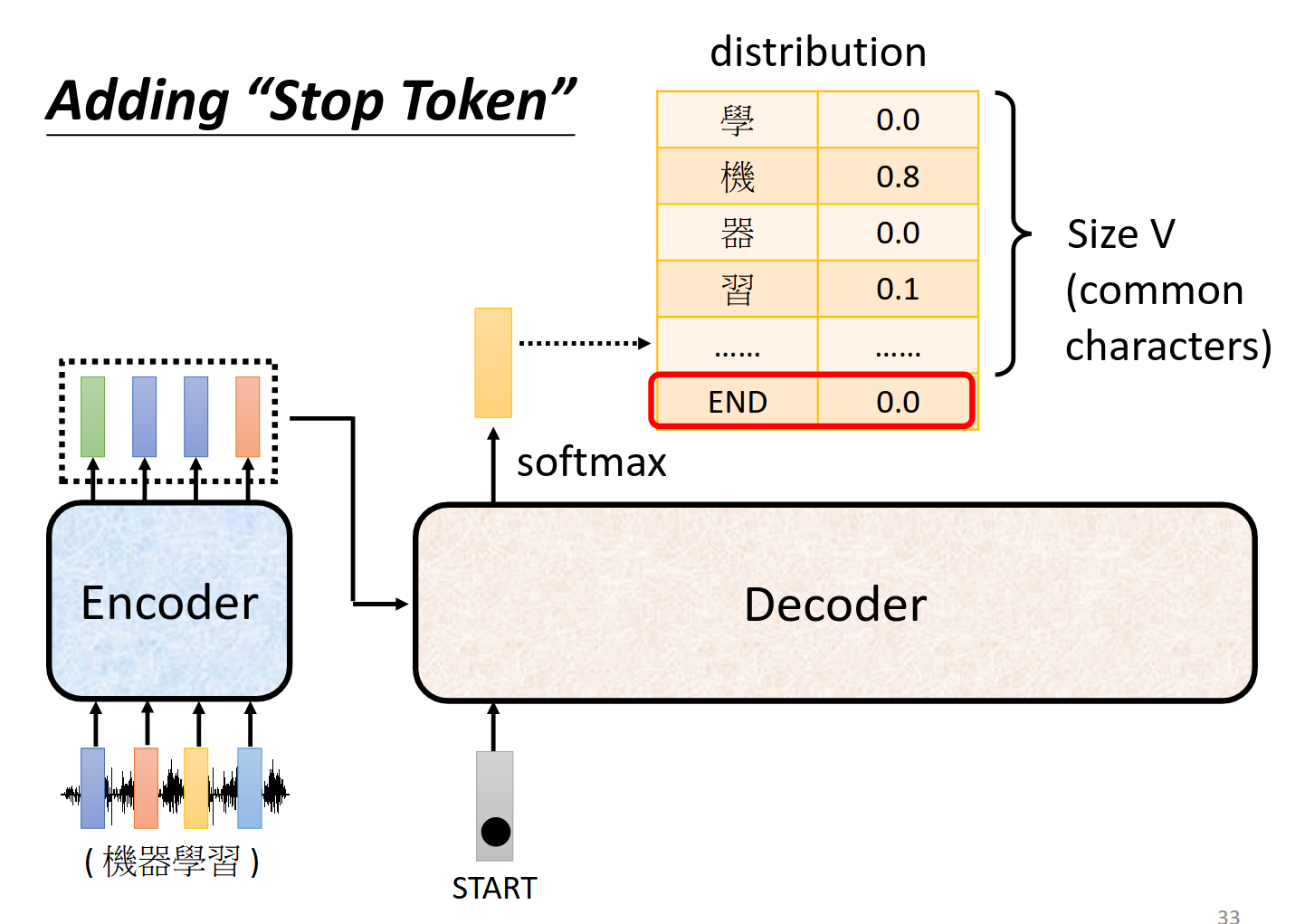
加一个end作为断,输出就stop
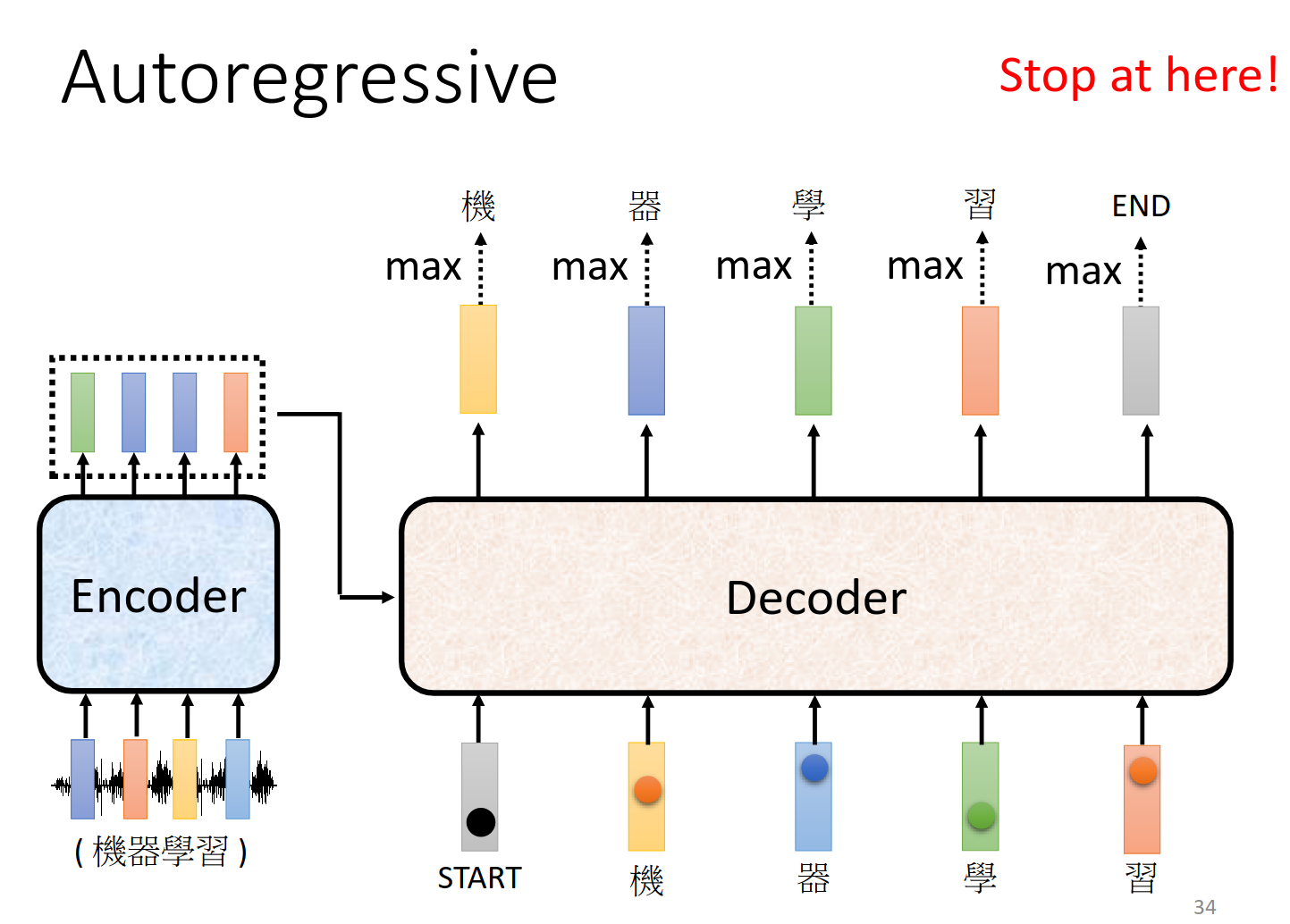
Non-autoregressive (NAT)
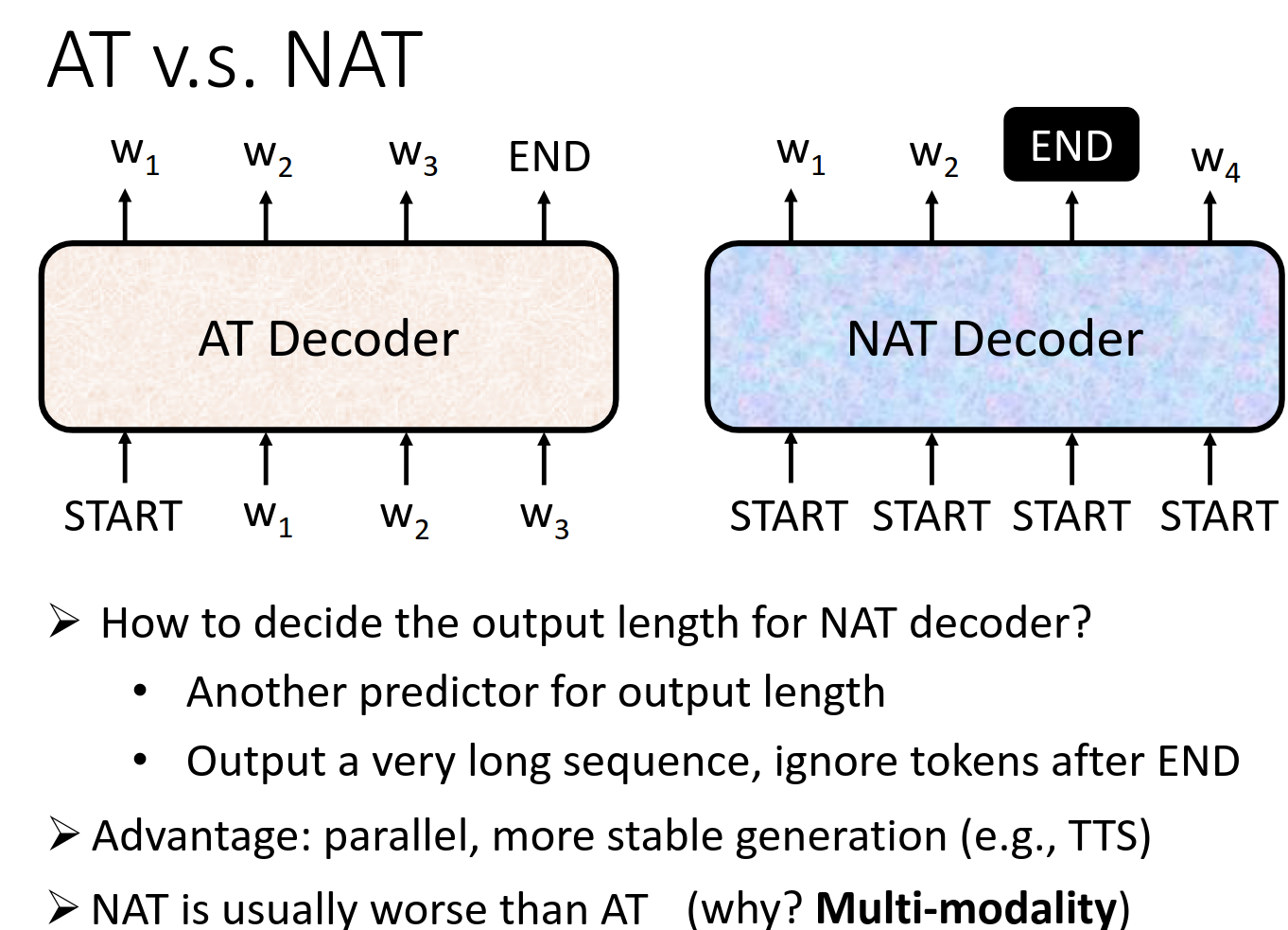
https://youtu.be/jvyKmU4OM3c for NAT
AT 解码器(自回归 Transformer)
- 顺序生成:AT 解码器按顺序逐个生成词。它从
START开始生成第一个词,然后基于 生成下一个词 ,接着依次生成 ,直到遇到 END标记,表示序列生成结束。 - 特点:每次生成的词都会依赖于之前已经生成的词,这种依赖保证了生成的连贯性和准确性,但由于是顺序执行,无法并行化,速度相对较慢。
NAT 解码器(非自回归 Transformer) - 并行生成:NAT 解码器可以同时生成所有词。它会同时生成
等多个词,减少了生成序列的时间。 - 特点:虽然并行生成大大加快了速度,但由于各个词是独立生成的,不依赖于之前的词,可能会导致生成的序列缺乏上下文连贯性,质量往往不如 AT 解码器。
NAT 解码器的优势在于并行生成,生成速度更快,尤其在一些应用场景下,如语音合成(TTS)
多模态问题(Multi-modality):由于 NAT 同时生成多个词,缺少上下文依赖,可能会导致生成结果不一致或出现歧义,特别是在面对复杂的多模态输出时。
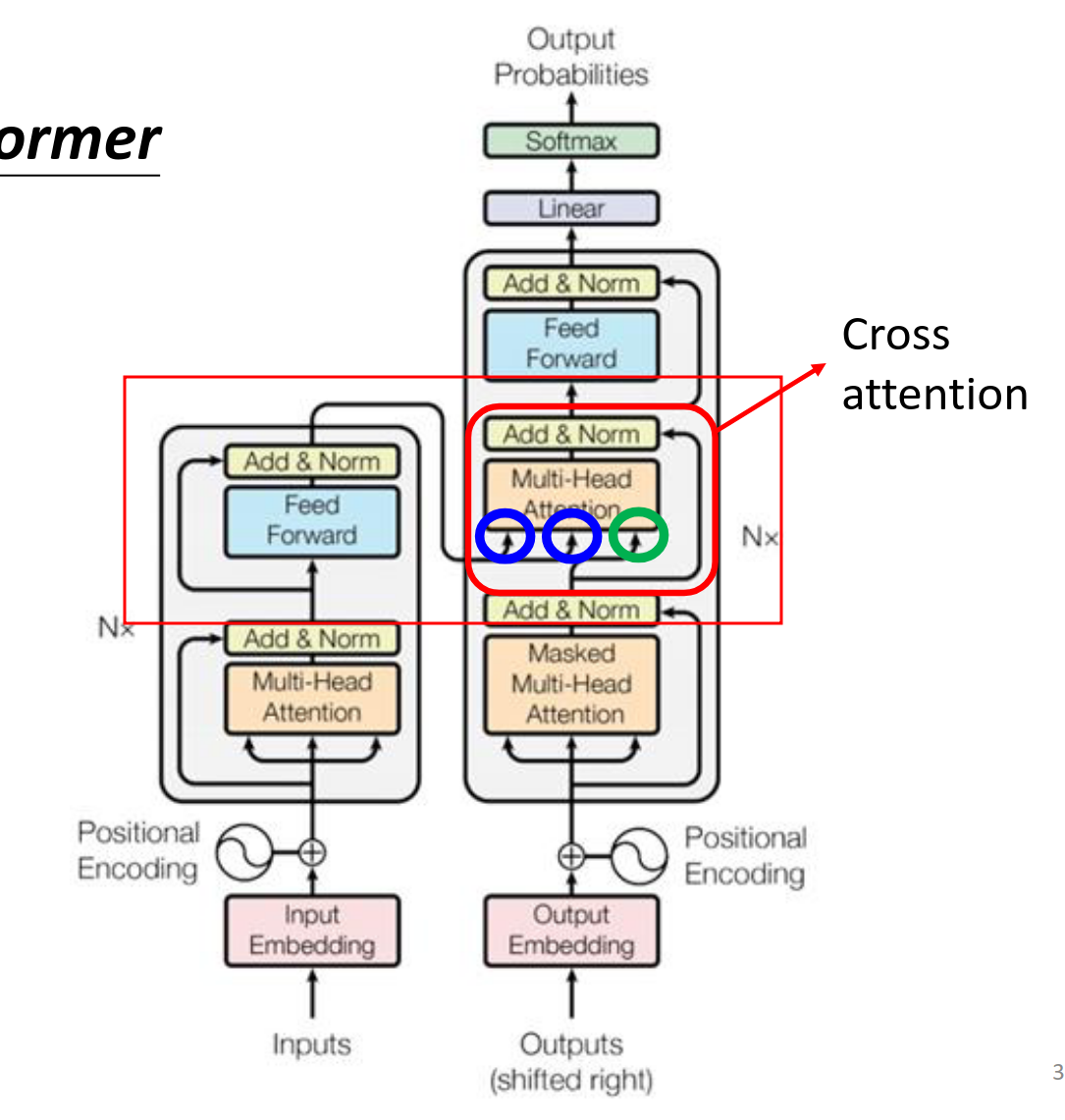
How to transfer the information between encoder and encoder
蓝色圈的是decoder给的,绿色的是encoder给的。
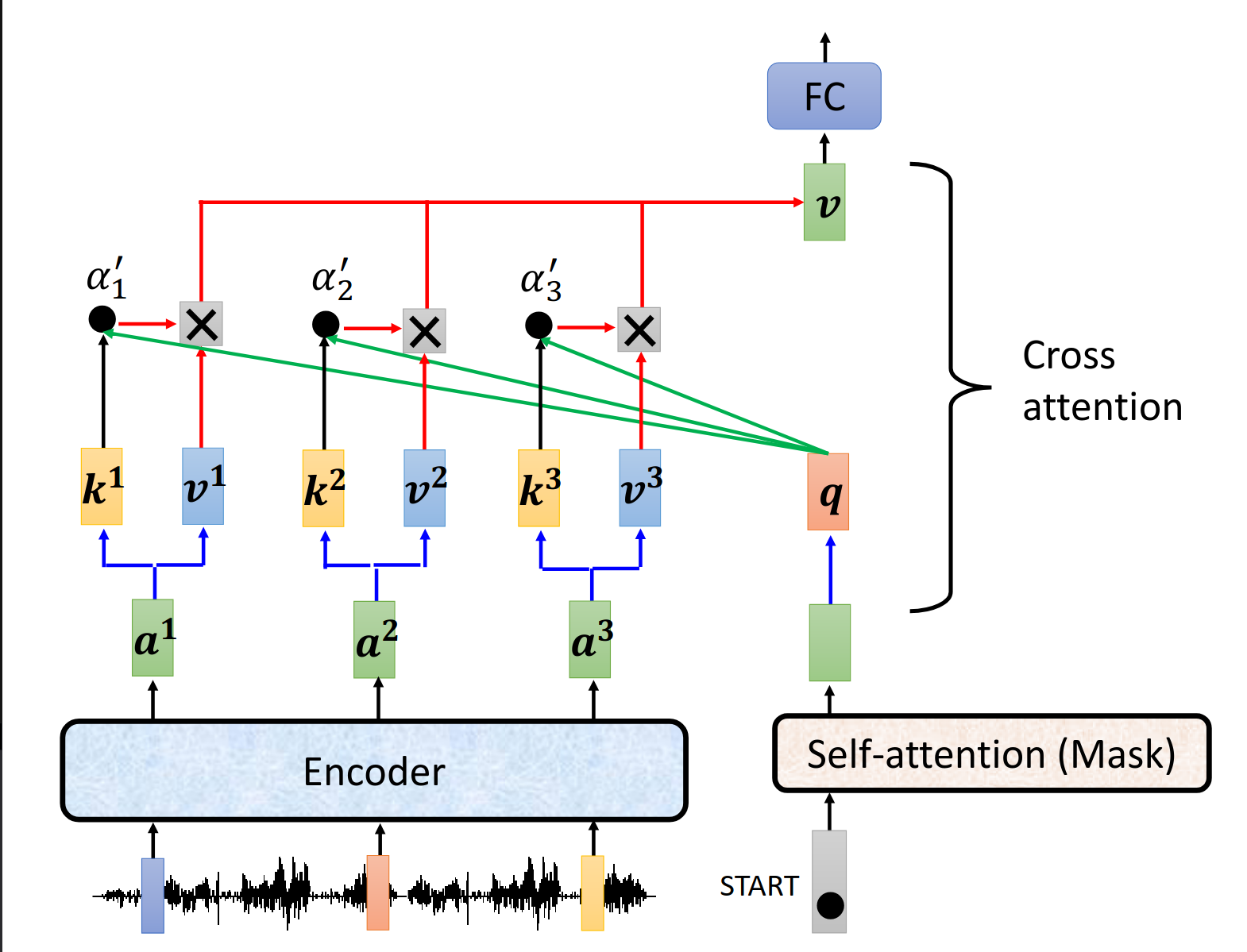
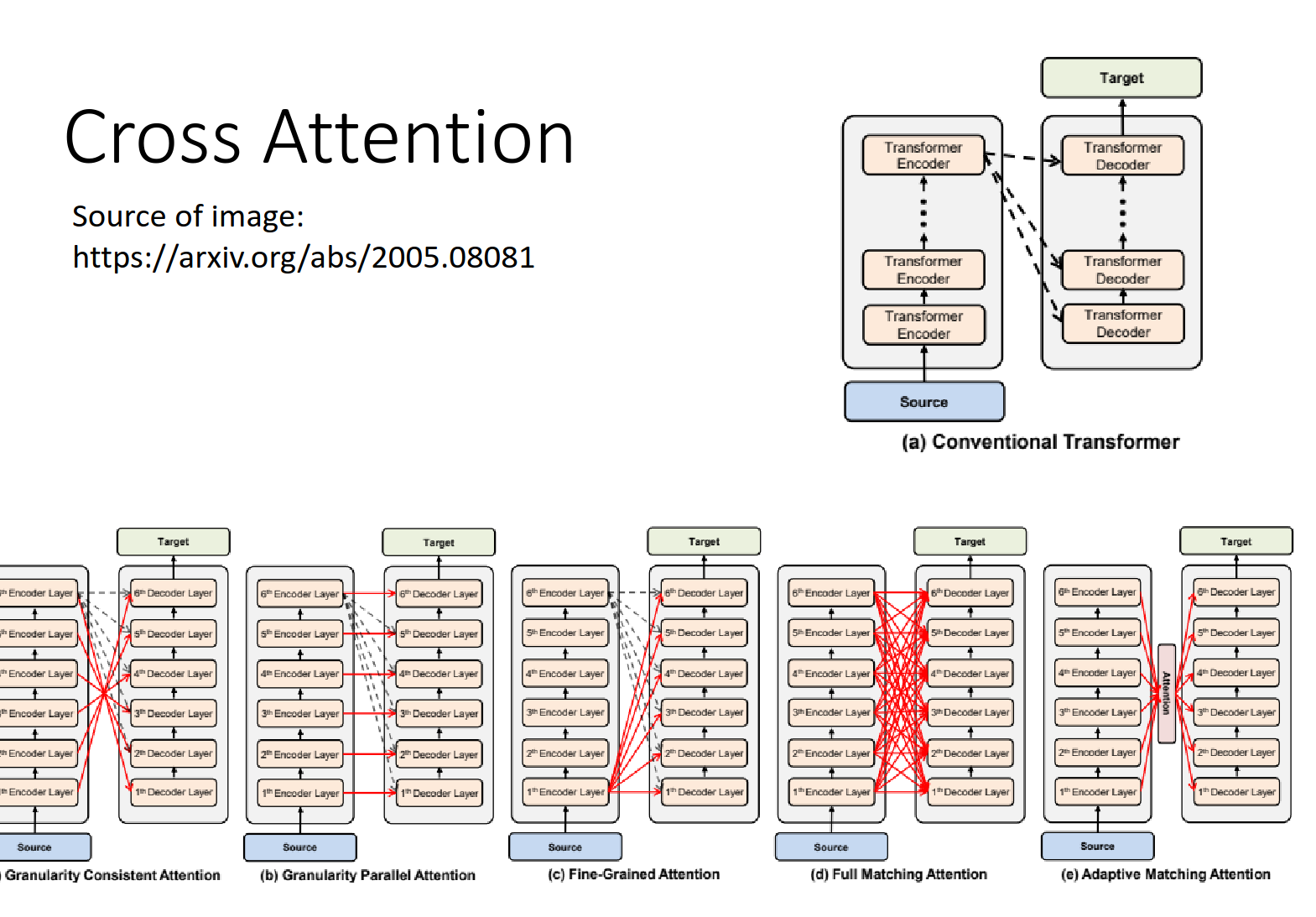
Cross attention介绍
用encoder来的信息和decoder的信息交叉操作得到输出。
下一个token输入
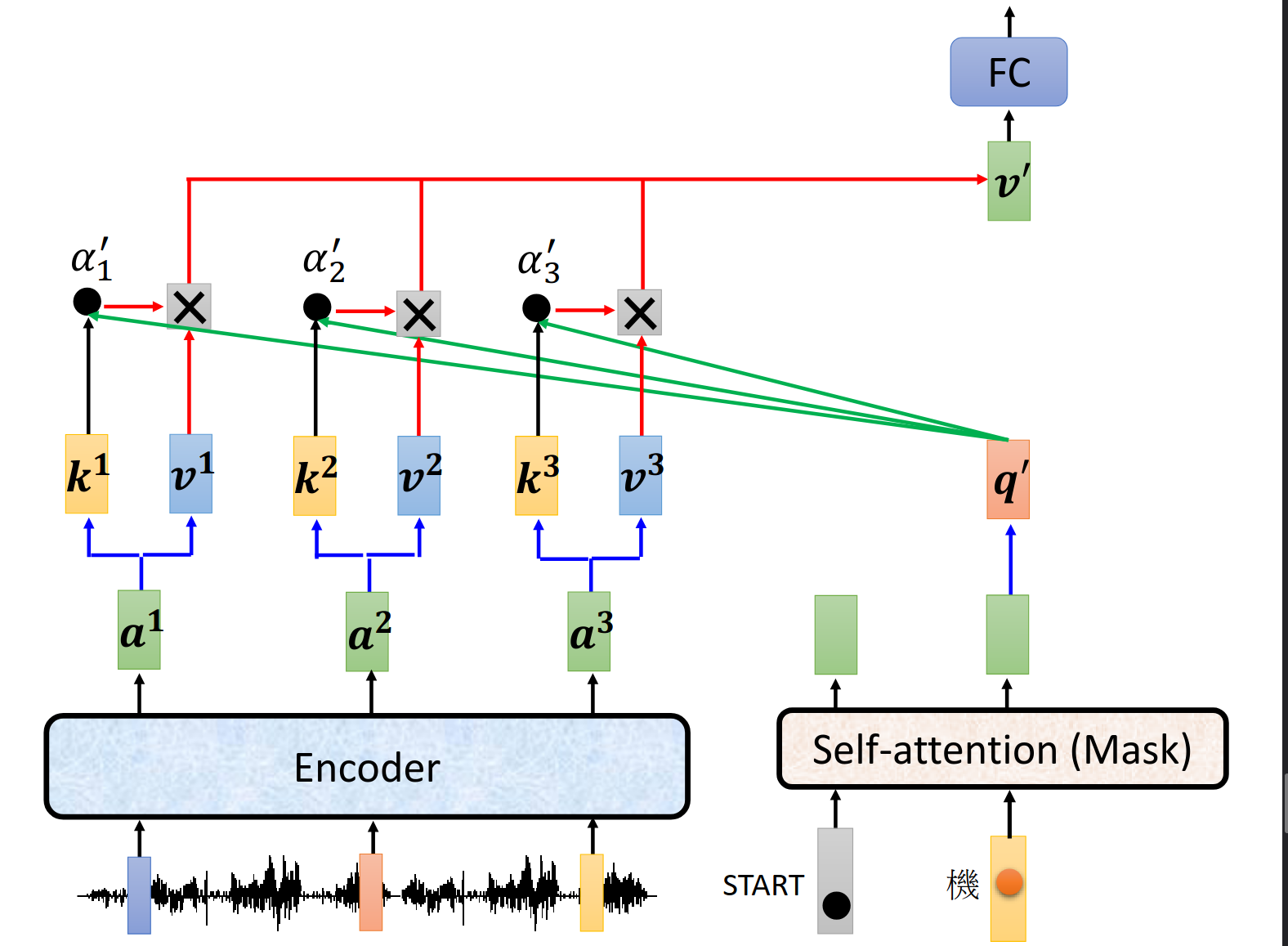
不同的cross attention的设计方式(但是就不是原来transformer里面的结构了)
https://arxiv.org/abs/2005.08081
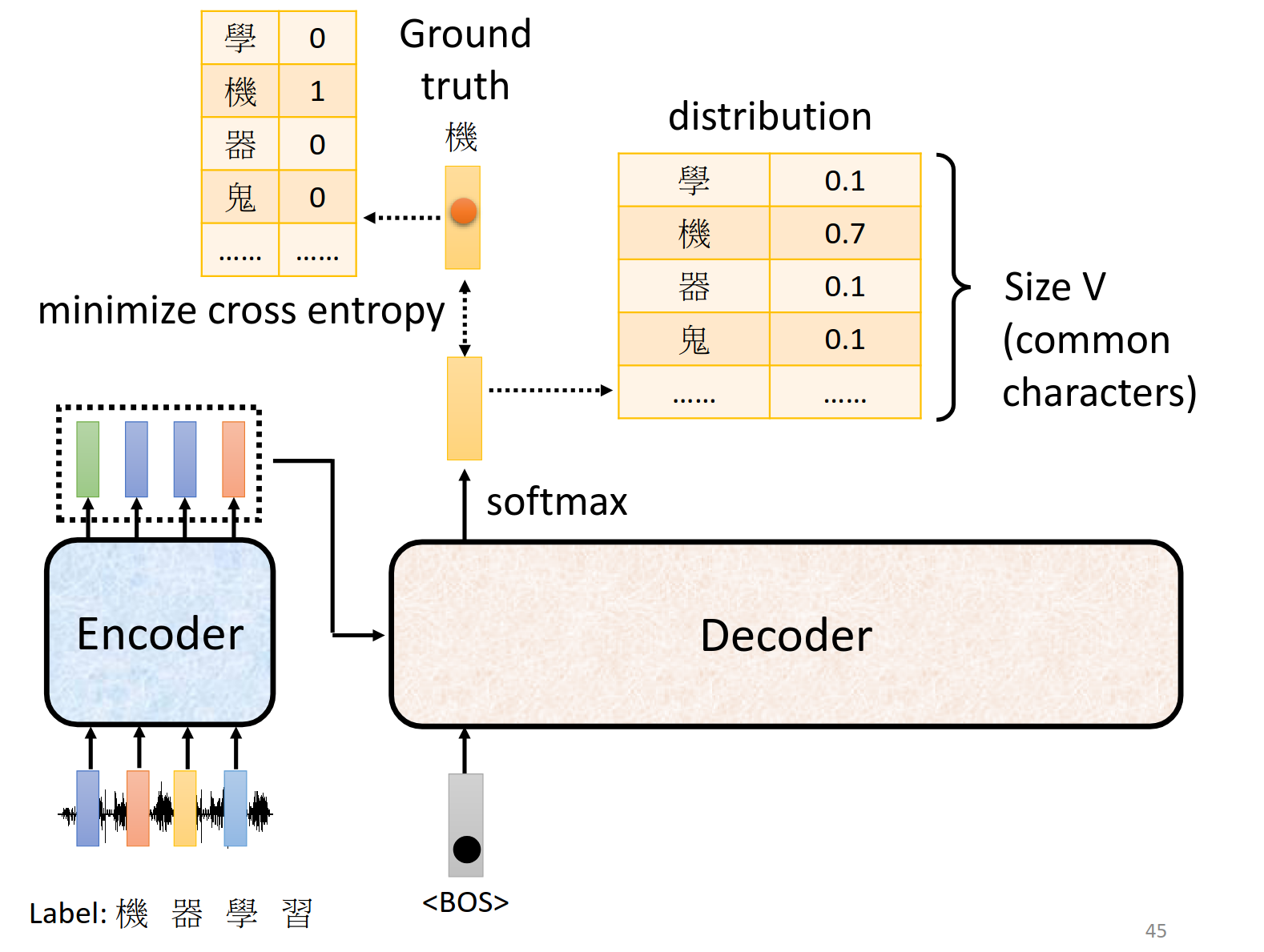
Train
onehot编码当作label,其余可以按照分类问题来解决。
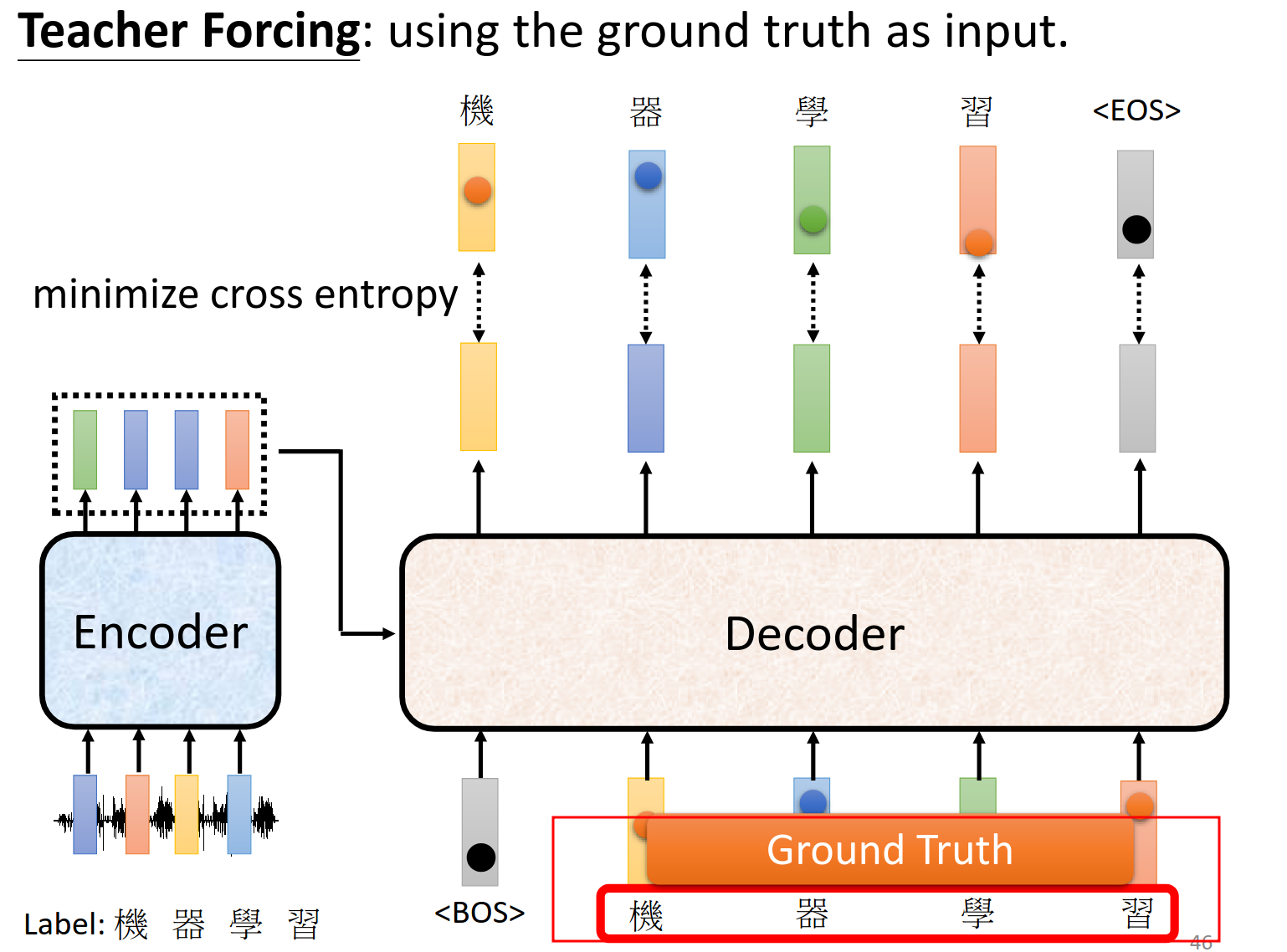
训练的时候,decoder输入是真正的输出。
Tips
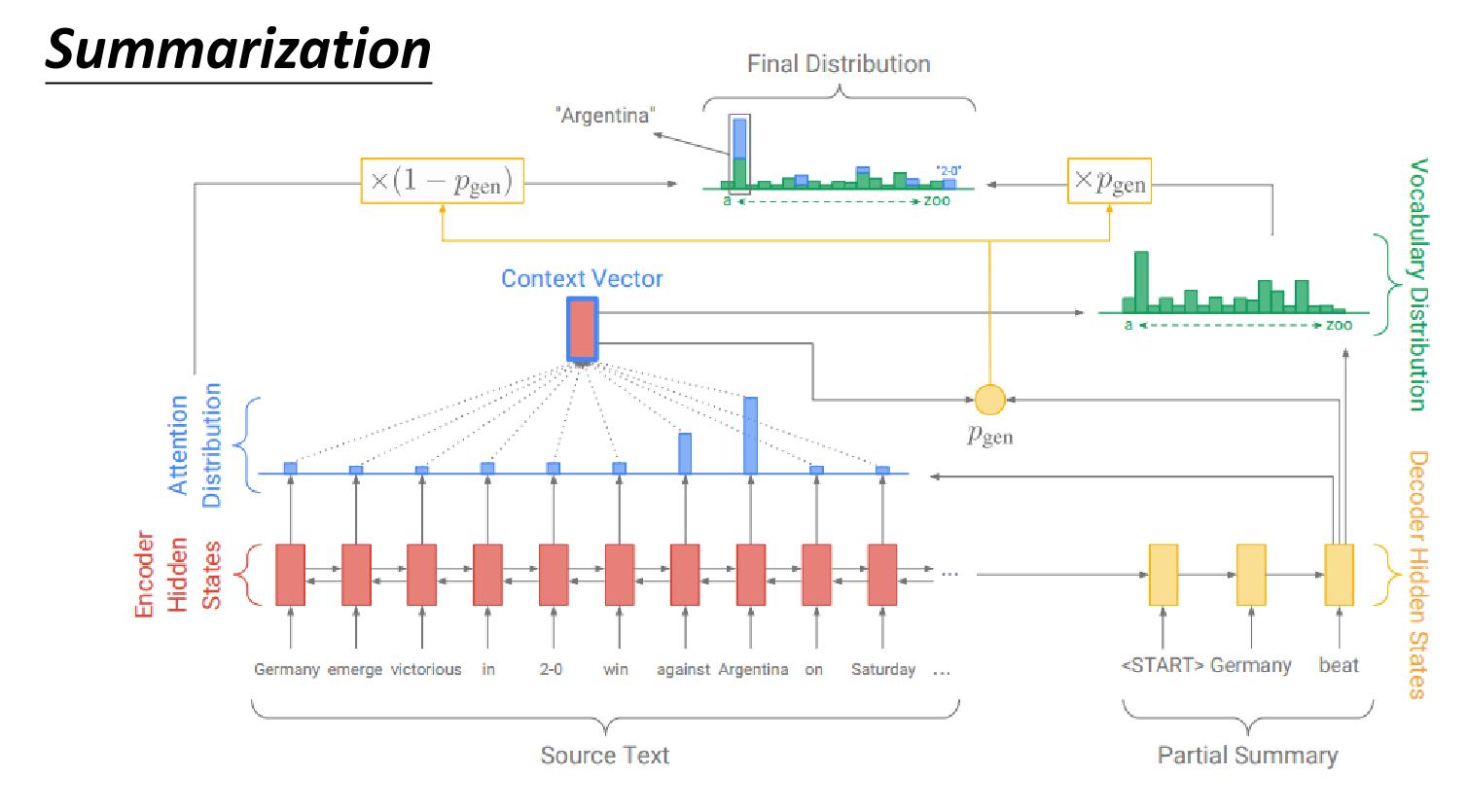
Copy Mechanism
一些内容只需要copy到输出就好

对摘要task而言这个copy能力很重要
https://arxiv.org/abs/1704.04368
https://youtu.be/VdOyqNQ9aww Pointer Network
Incorporating Copying Mechanism in Sequence-to-Sequence Learning https://arxiv.org/abs/1603.06393
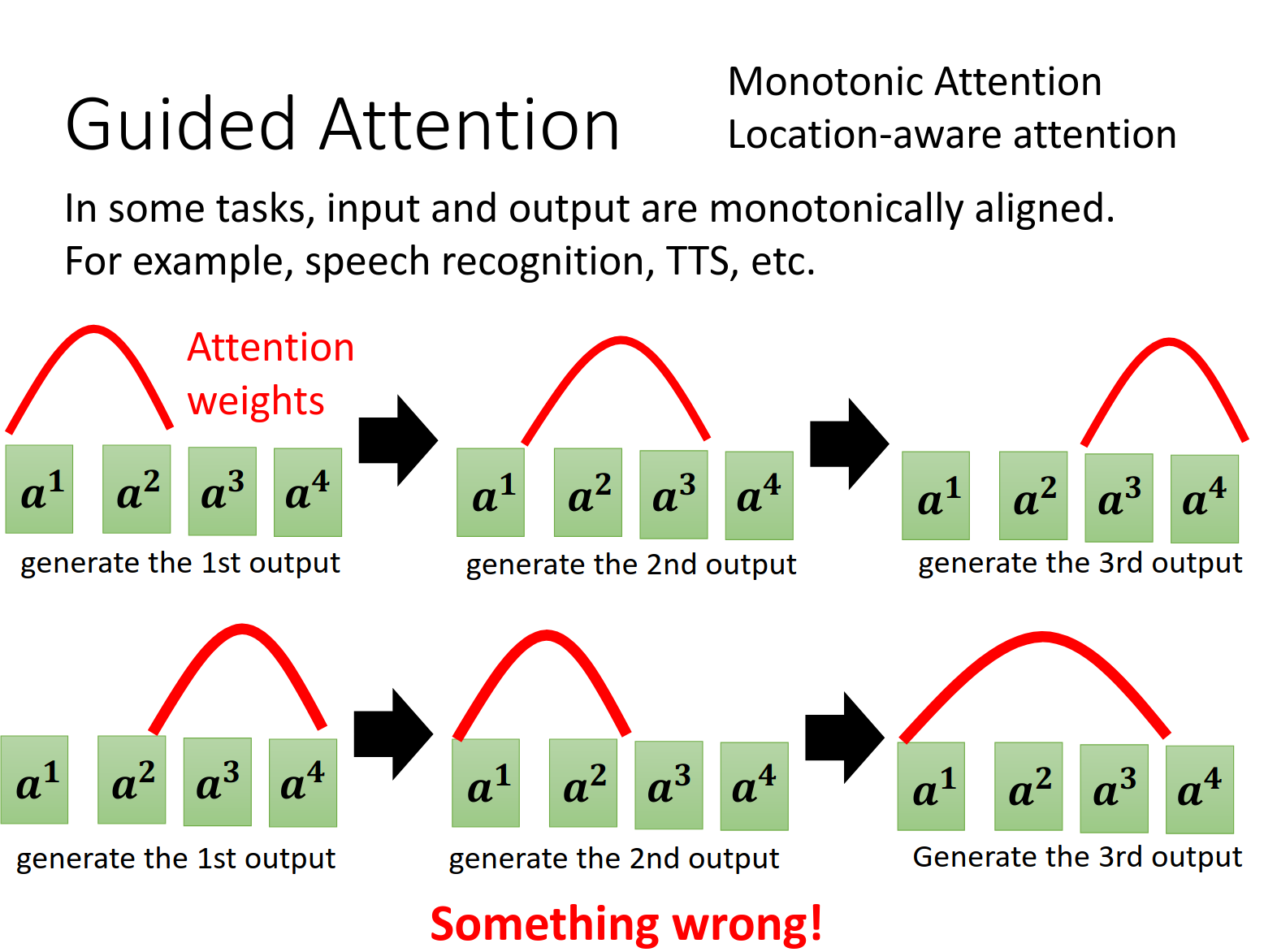
Guided Attention
强迫attention要有限制,不能乱关注
Monotonic Attention
Location-aware attention
是两个这方面的关键词
Beam Search
虽然第一次绿色的不好,但是他会让后面的选择很好,因此全部走红的不一定是最好的。
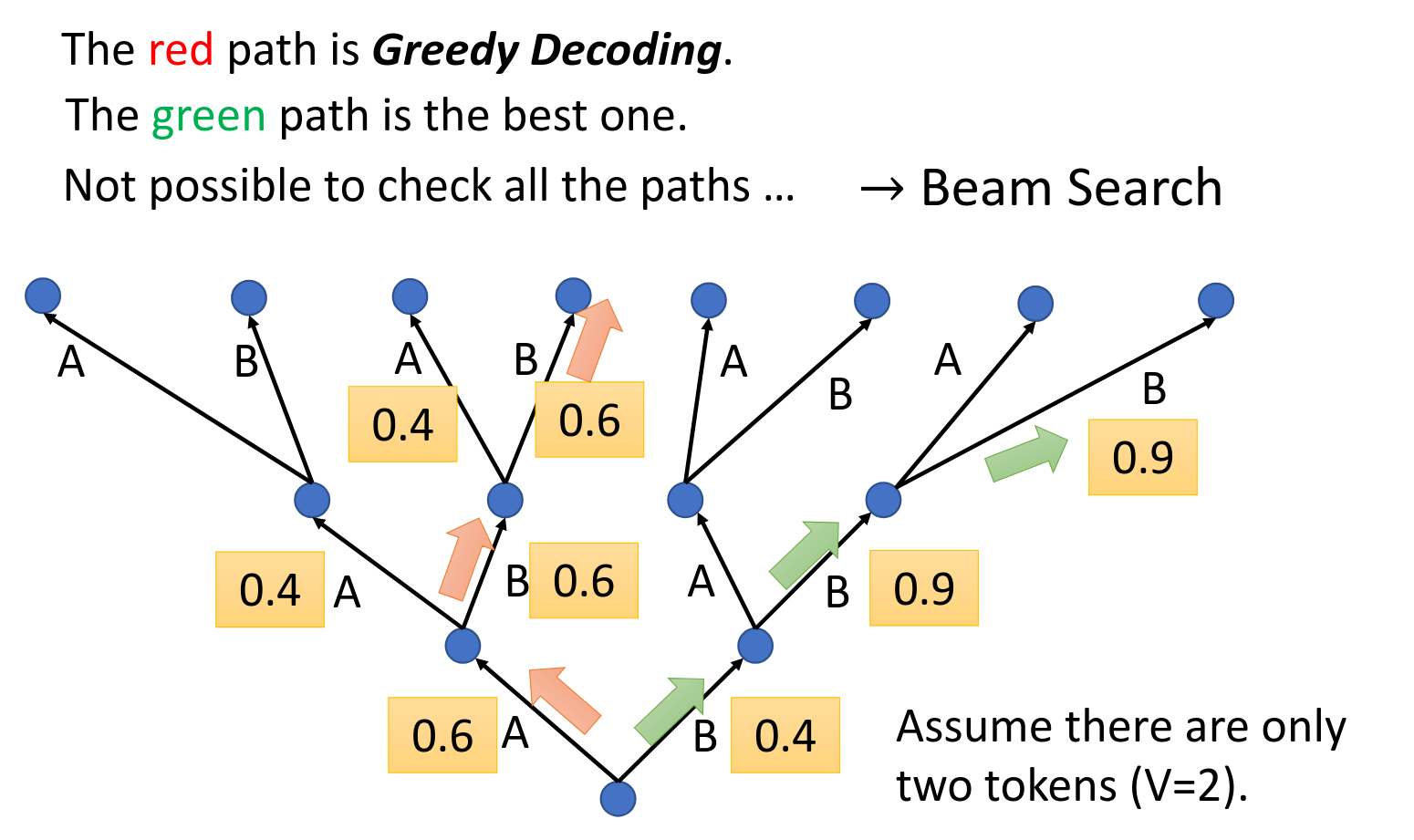
但是又又又又又又反转了。任务答案明确的时候beam search就好一些,但是需要机器的创造力的时候(编故事)那么就要加入随机性,因此一定要根据task选择方法。

https://arxiv.org/abs/1904.09751
Optimizing Evaluation Metrics?
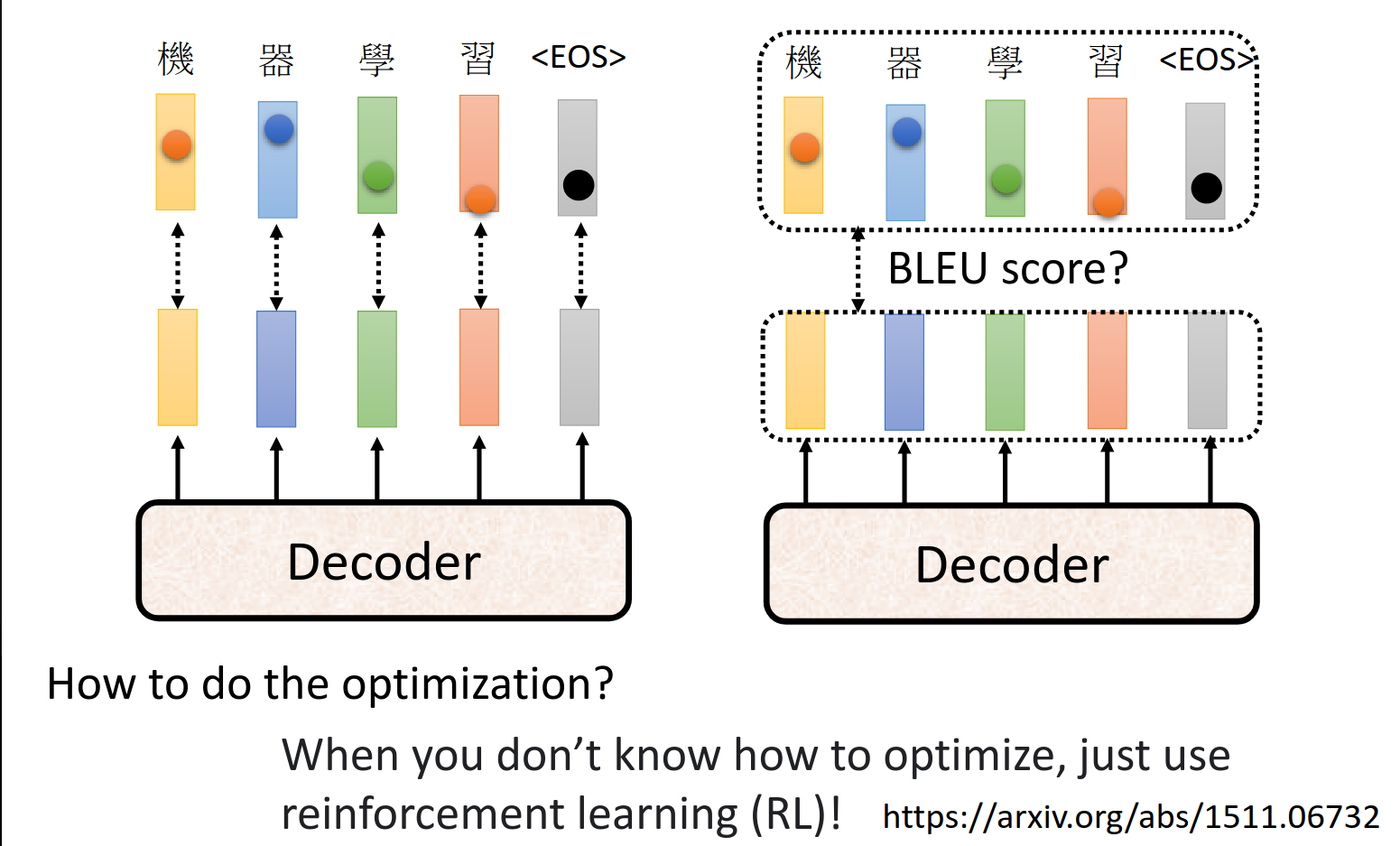
这张图片讲解了在序列生成任务(例如机器翻译)中优化评估指标的概念,具体提到了常用的评估指标 BLEU 分数。BLEU 分数用于评估模型生成的文本与参考翻译的相似程度。
使用强化学习!
Scheduled Sampling
Original Scheduled Sampling
Scheduled Sampling for Transformer
Parallel Scheduled Sampling
https://arxiv.org/abs/1506.03099
https://arxiv.org/abs/1906.07651
https://arxiv.org/abs/1906.04331
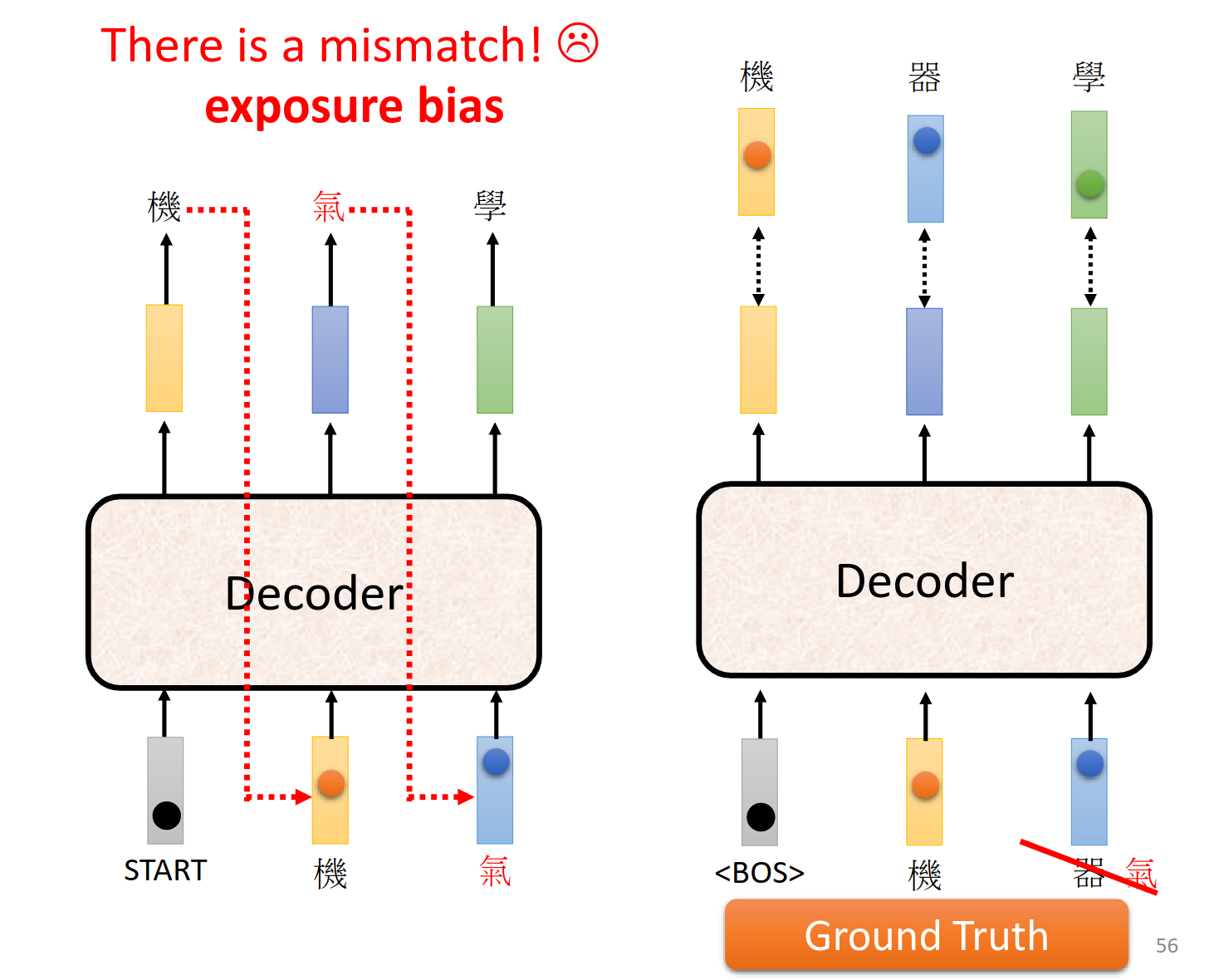
我们训练的时候也要给一些错的,增强系统的鲁棒性。
Scheduled Sampling 是一种用于训练序列生成模型(例如 RNN、LSTM 等)的技术,目的是解决训练时模型“暴露偏差”(exposure bias)的问题。暴露偏差是指在训练过程中,模型总是依赖真实数据(ground truth)的序列来进行下一个时间步的预测,而在测试阶段,模型只能依赖自己过去生成的输出,从而可能造成误差的累积,导致生成的序列质量下降。