Chapter1 Basic Concepts
A grid-world example
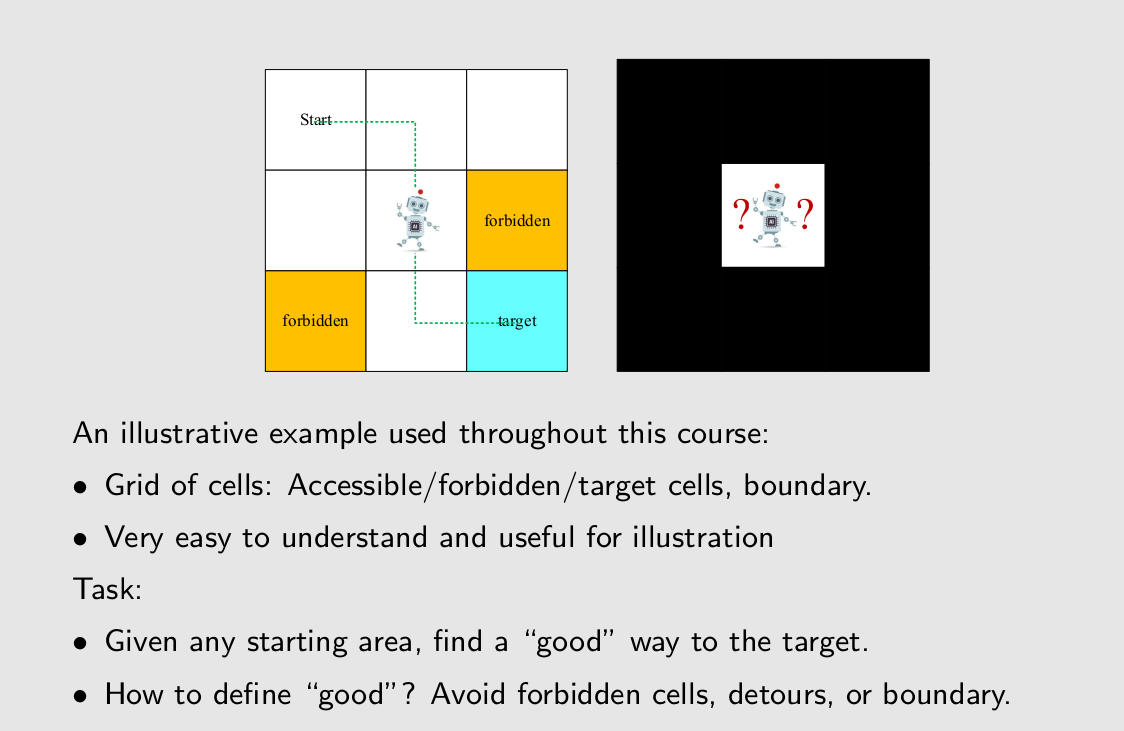
good的定义要因task而不同。
State

状态空间在这里面就是集合!
Action
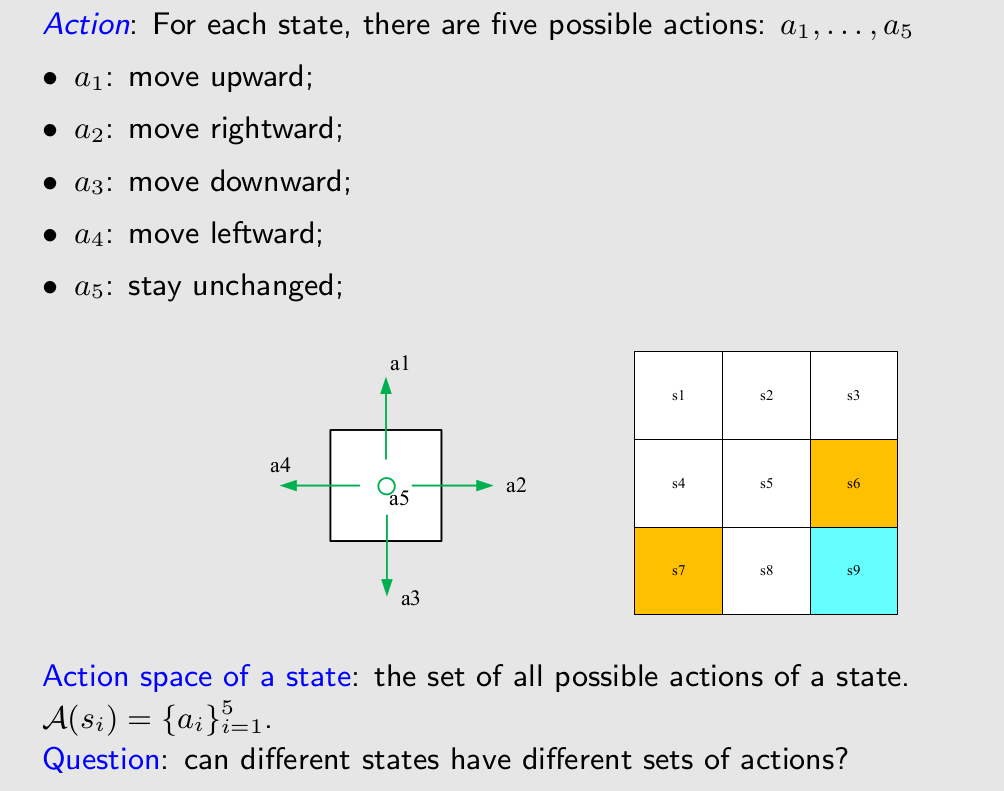
也是集合
注意ActionSpace是state的函数!
State transition

这是个游戏环境的话,状态转移可以随便定义
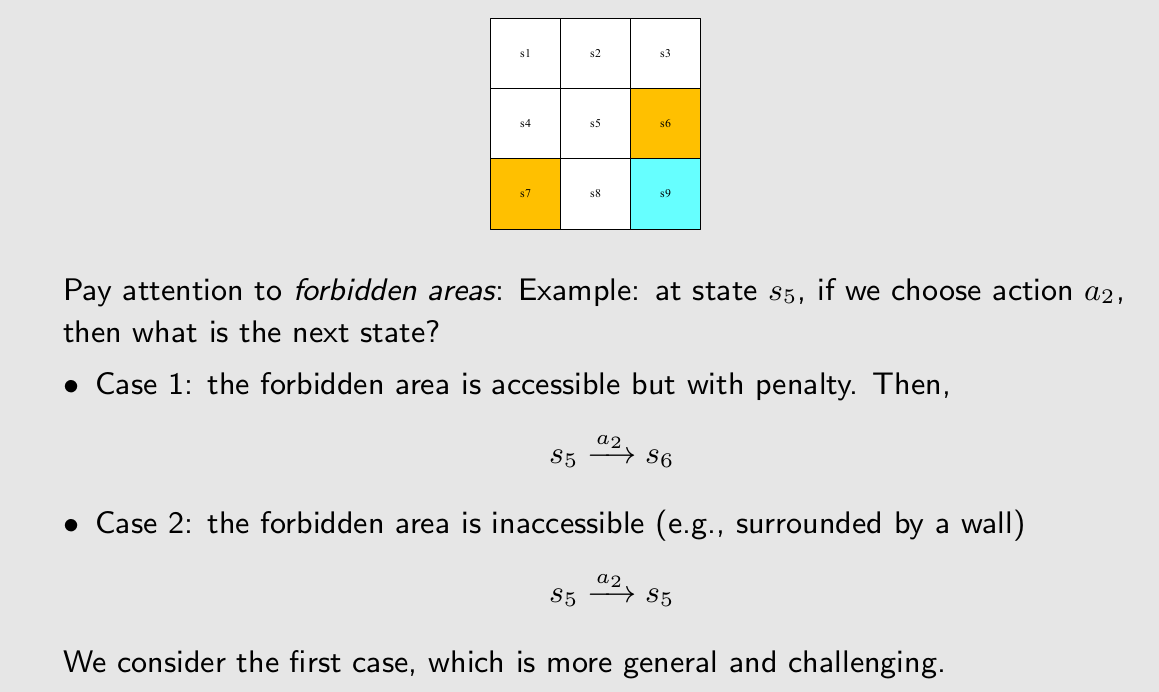
case1和case2是两种不同的forbidden area的定义,第一种是我们要研究的,因为更加复杂同时可能会有更加有意思的行为。
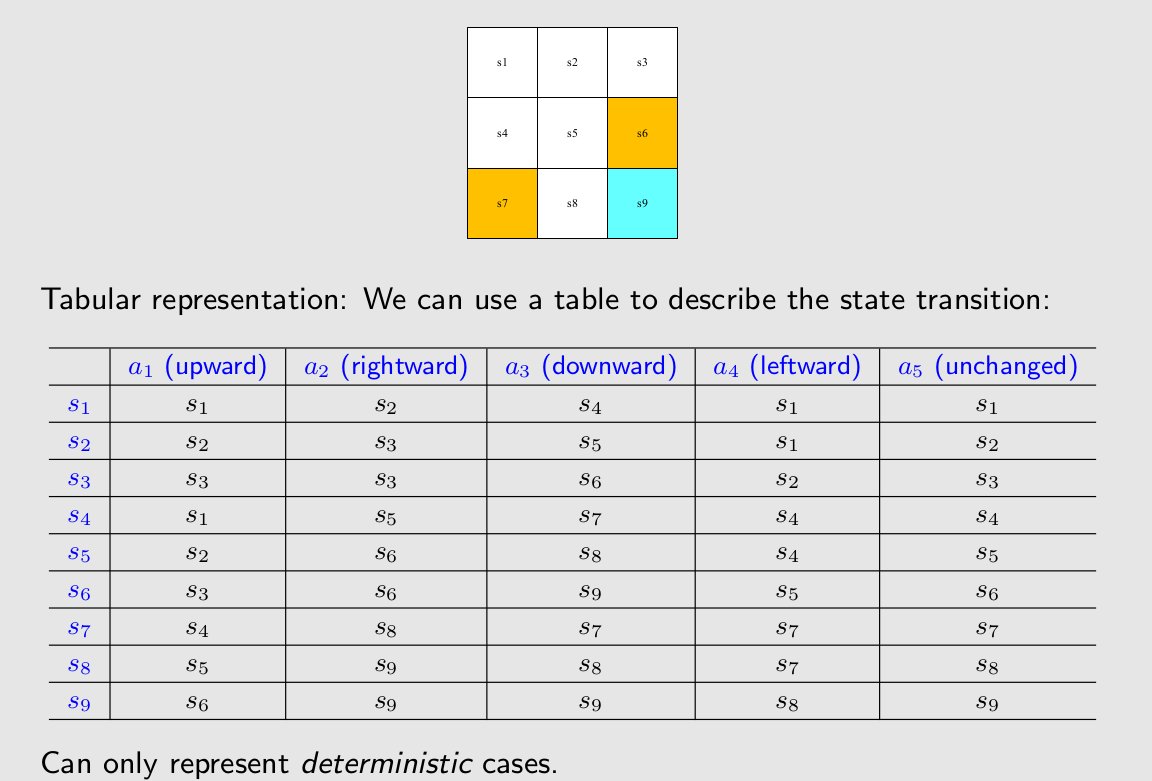
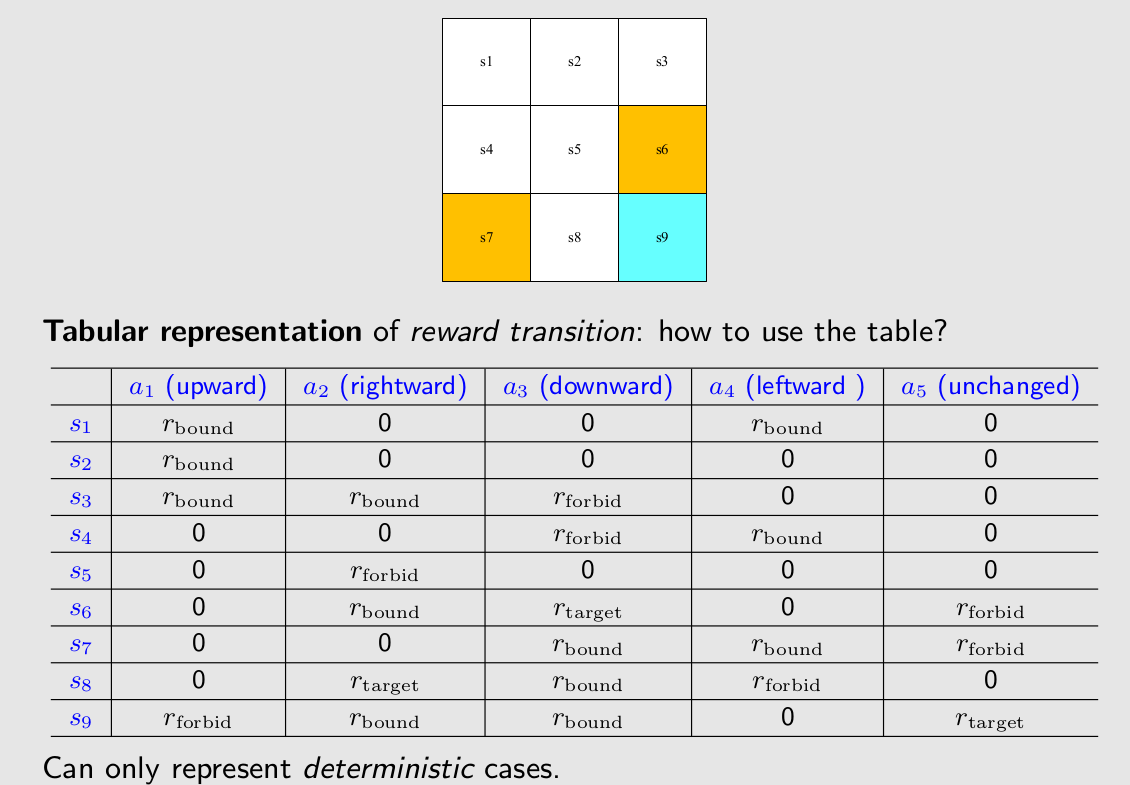
表格表示方法。
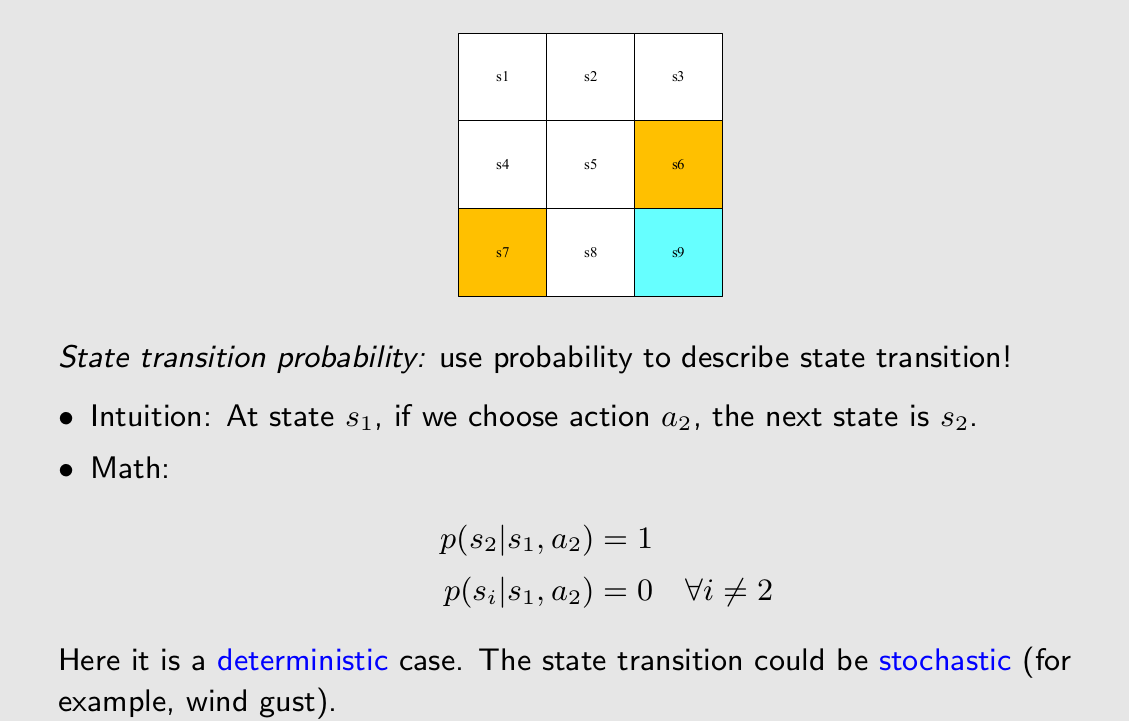
我们解释数学表达式中的第一行,state在s1,进行action中的a2,进入到s2的概率是1。
ppt中是一个确定性的例子,但是引入概率能描述一些随机性的行为,比如说吹过了一阵风让我们state在s1,进行action中的a2,进入到s2的概率是0.9。
Policy
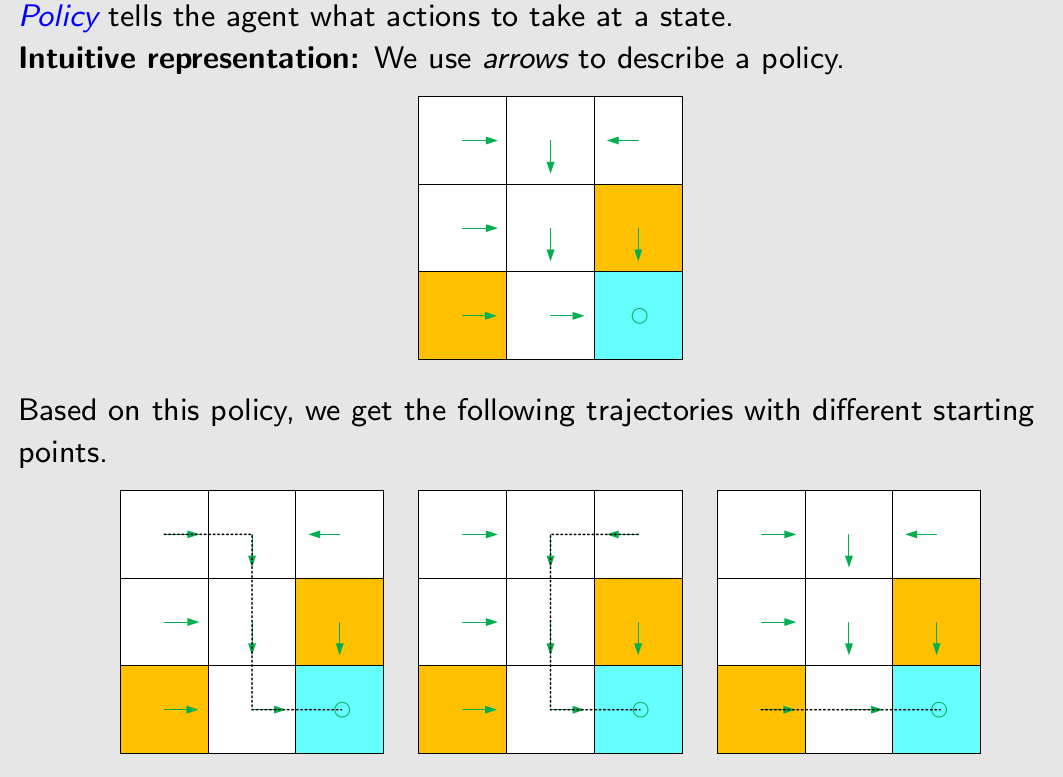
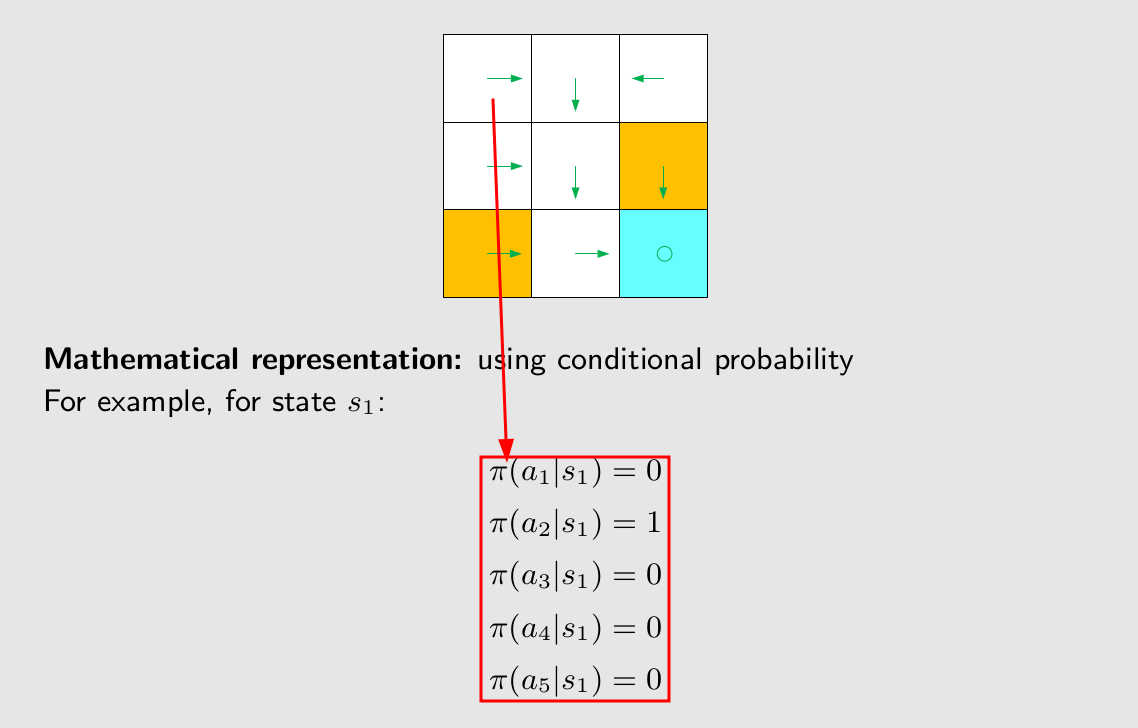
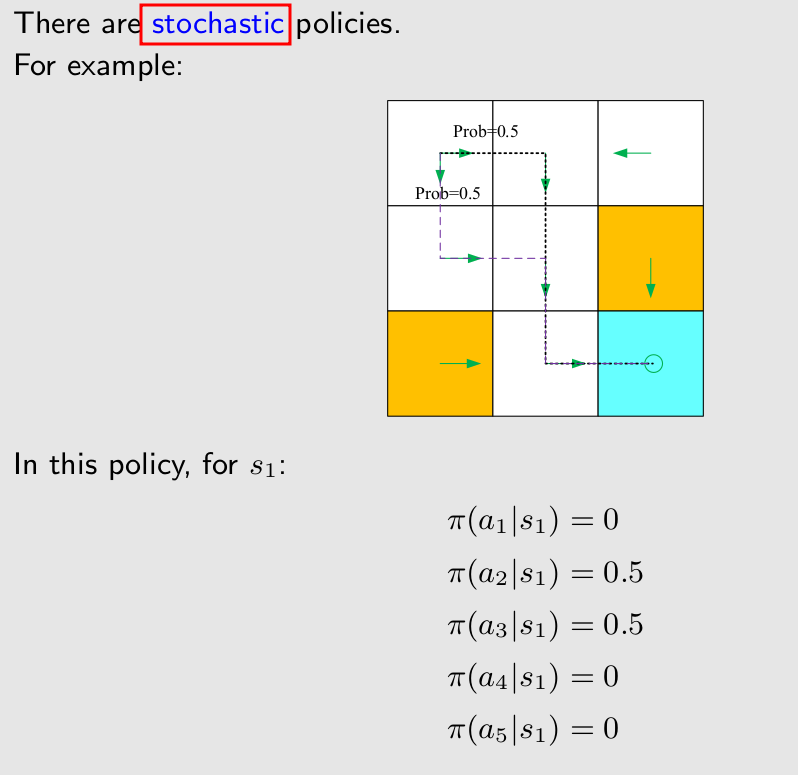
在一个state采取一个action的概率。
Reward



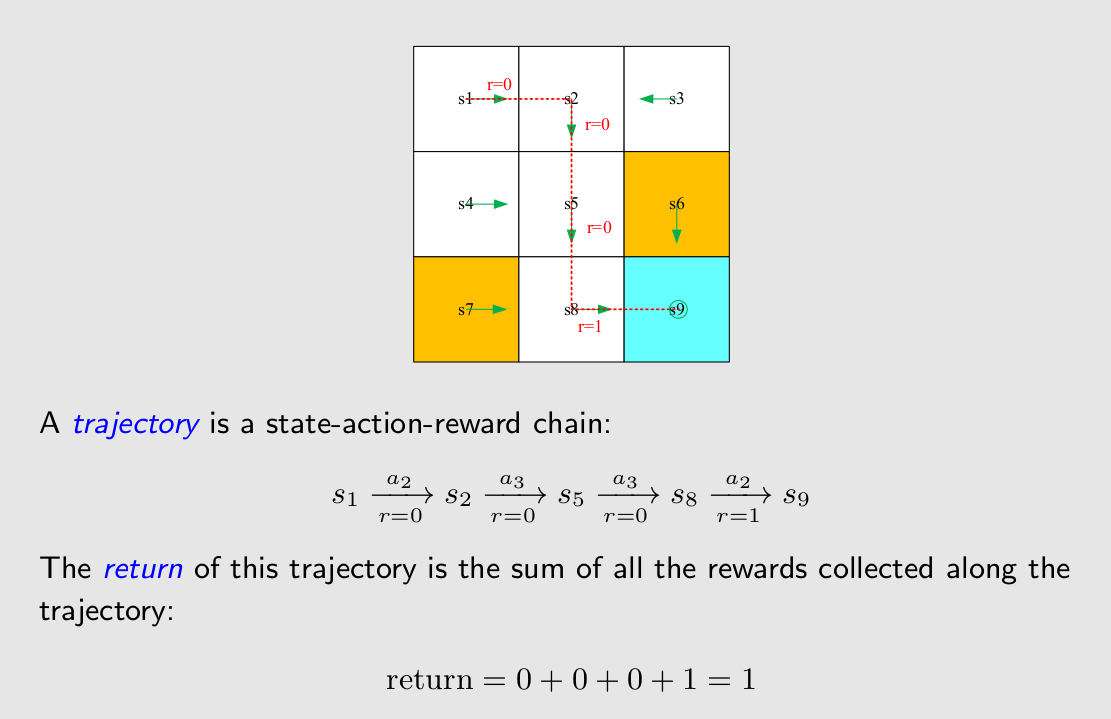
Trajectory and return
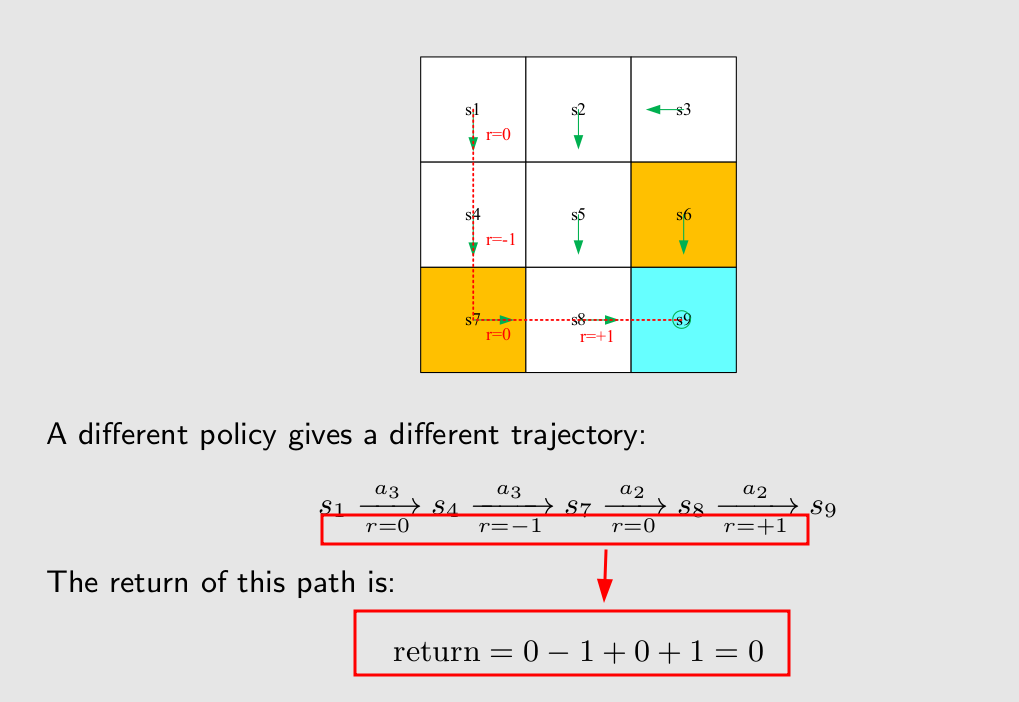
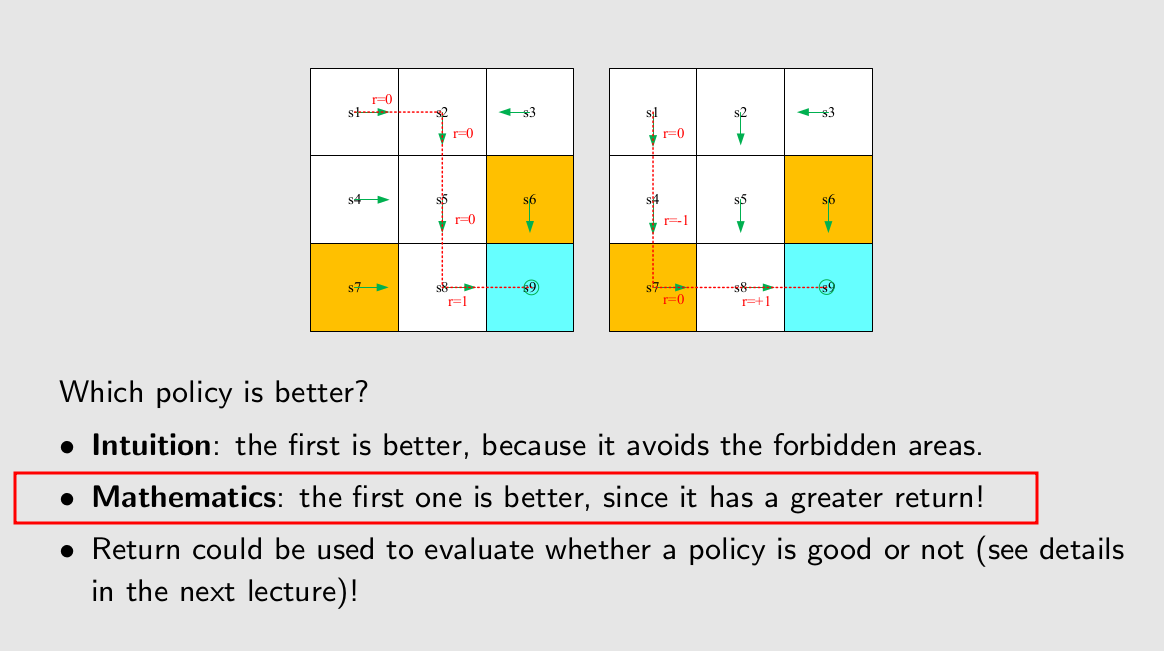
Discounted return


Episode
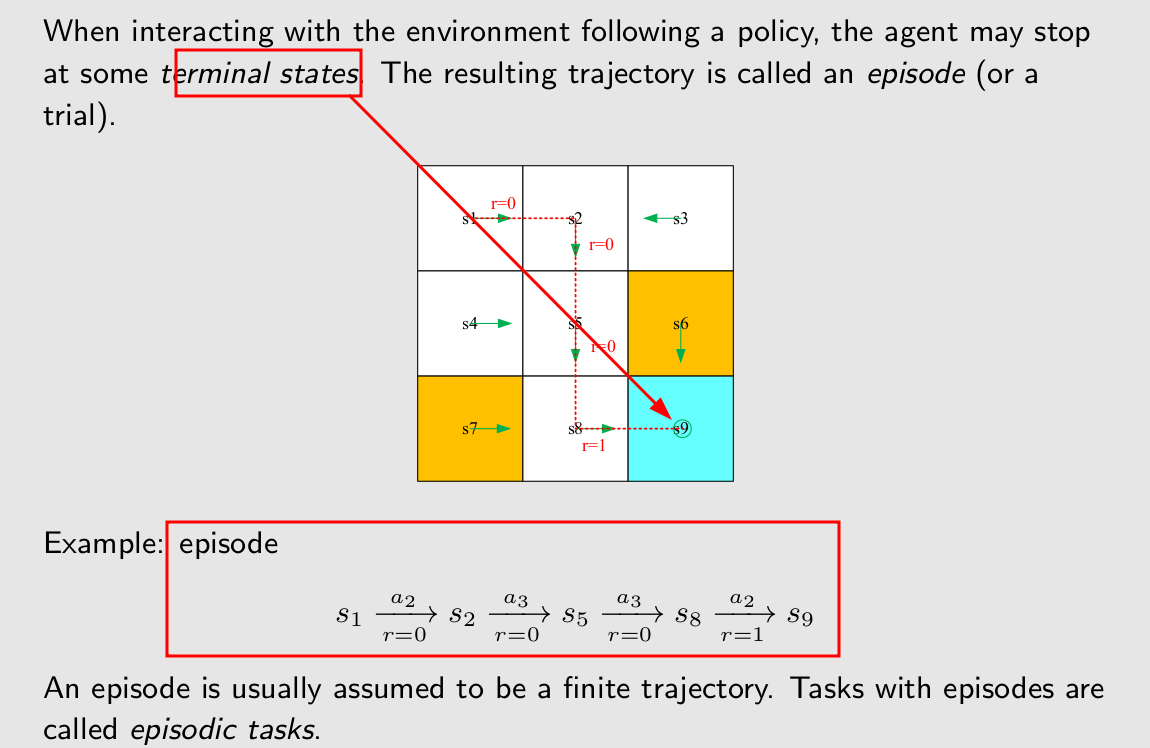
episode是指完成了有限步之后的整个trajectory。

Markov decision process (MDP)

M:Markov property
D:Policy
P:Sets and Probability distribution
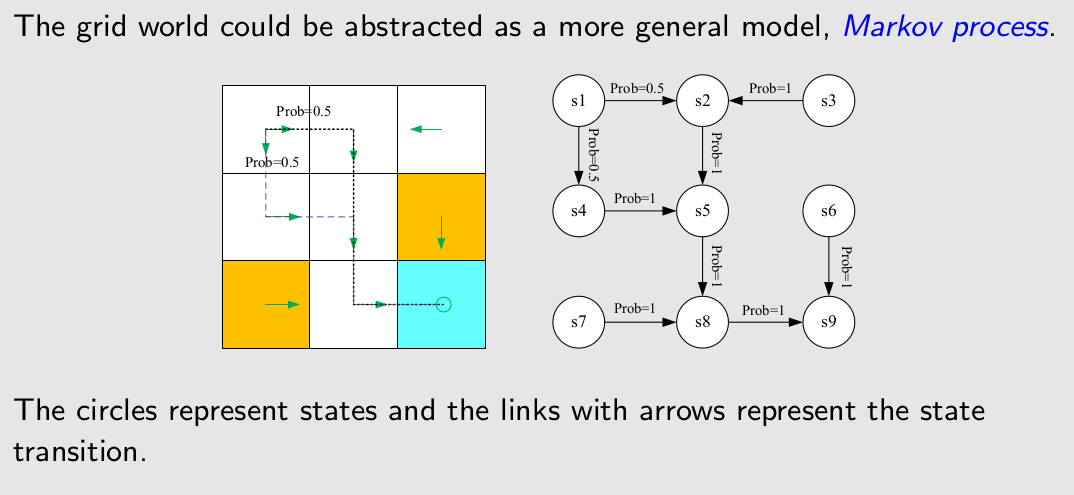
可以看出这种过程没有确定D:Policy因此就叫做Markov process